Tech Giant Google announced that it is developing an AI application that creates images from input text. Users can use the new app to generate images by typing only a few words. The app offers a “City Dreamer” function using which users can construct buildings and a “Wobble” feature to interact with cartoon monsters generated by the app.
At this year’s AI@, we shared how AI can help solve some of humanity’s biggest challenges, fuel our creativity, and help us make sense of the world through language.
Read more about the announcements we shared in these three major areas ↓ https://t.co/O6mguHm01a
The AI app was announced at the AI event in New York and will be accessible through AI Test Kitchen App. Users can test prototype AI-powered systems from the company’s labs using the AI Test Kitchen application before they are put into production.
The app will be rolled out shortly. Google has not revealed the date yet and plans to take it “slow.” Douglas Eck, Google’s Principal Scientist in New York, said, “We also have to consider the risks that generative AI can pose if we do not take good care, which is why we have been slow to release them.”
Additionally, Google demonstrated advancements in AI tools that assist with coding and audio production jobs and a text creation tool, Phenaki, that writers could use to create short stories.
Facebook-parent Meta Platforms said on Thursday that its India head, Ajit Mohan, has stepped down after four years, while a media report said he would join rival Snap. According to sources, Mohan will serve as Snap’s President of the Asia-Pacific business.
According to a spokesperson, Manish Chopra, head and director of partnerships at Meta India, will take on an interim capacity. Vice President of Global Business Group at Meta, Nicola Mendelsohn, said that Mohan has played a significant role in shaping and scaling their India operations over the last four years.
Mendelsohn said, “We remain deeply committed to India and have a strong leadership team to carry on all our work and partnerships.”
Mohan joined Meta in January 2019 as a vice-president and managing director of the India business. During his stay at the firm, Facebook’s family of apps, including Instagram and WhatsApp, added over 300 million users in India and made a series of ambitious investments in the country, including cutting a $5.7 billion check to Indian telecom giant Jio Platforms. It also ramped up the commerce engine of WhatsApp.
Snap has ramped up efforts in India and several other Asian markets recently and pushed to introduce a series of localized features. The app has quadrupled its user base to 100 million in India in the past three years.
Google has announced a new project to develop a single AI-language model supporting over 1000 spoken languages. The company is actively researching the domain as it believes that more than 7000 languages are spoken around the world, but only a few have representation.
Google is actively developing and enhancing language models, starting from MUM and LaMDA. The advancement was followed by Pathways, a neural architecture that works similarly to the brain. The company developed a 540-billion-parameter language model named PaLM using Pathways. Another language model, Universal Speech Model, is compatible with 400 languages as a part of its ambition.
Pathways-driven language models aid in breaking down language barriers by supporting more languages. Numerous languages have been added to Google Translate due to the development of such language models.
The recently proposed AI model will also aim to bring greater inclusion of marginalized communities. Google is partnering with several marginalized groups to source speech data and include more language recognition and translation services.
Other tech companies like Meta are also working in the domain to include marginalized languages and give them a fair representation with models like No Language Left Behind.
AI image generators are one of the hottest trends this year. AI image generators have gained more traction this year with the release of OpenAI’s DALL-E 2 in April and the self-titled product from independent research lab Midjourney in July. Additionally, Google announced Imagen in May, and Stability AI rolled out the text-to-image generator Stable Diffusion. We were also blessed with knock-offs like HuggingFace’s DALL-E Mini (later renamed to crayon). While these innovations are already sparking controversies about ownership and copyright violation, the results also ‘display’ another challenge: perpetuating gender and cultural bias in the results.
Hugging Face’s artificial intelligence researcher Sasha Luccioni developed a tool to show how the bias in text-to-art generators is put to use. Using the Stable Diffusion Explorer as an example, entering the word “ambitious CEO” produced results that showed various men in various black and blue suits, however, entering “supporting CEO” produced results that displayed an equal number of both women and men.
Luccioni explained to Gizmodo that the LAION image set, which comprises billions of photographs, photos, and other images collected from the internet, including image hosting and art sites, serves as the foundation for the Stable Diffusion system. The way Stability AI classifies various image categories leads to the establishment of this gender, as well as some racial and cultural prejudice. According to Luccioni, the system is trained to focus on the 90% of photos connected to a prompt if the training dataset comprises 90% male and 10% female images. That is the most extreme case, but the greater the diversity of visual data on the LAION dataset, the less probable it is that the Stable Diffusion Explorer would generate bias-free results.
In a Risks and Limitations document released in April, OpenAI noted that their technology might encourage prejudices. Their technology generated photos that disproportionately displayed white individuals and frequently depicted western culture, such as western-style weddings. Similar to this, the DALL-E 2 generated results that were biased toward men for the phrase “builder” and women for the term “flight attendant,” despite the fact that both men and women work as flight attendants and builders, respectively.
Large tech companies are generally hesitant to grant unrestricted access to their AI product because of concerns about being misused and, in this case: to generate ethically questionable content. But in the last few years, several AI researchers have started creating and making AI products available to the public. The development leads to experts raising questions about the possible exploitation of AI technology. Even though Stability AI touted Stable Diffusion as a far more “open” platform than its competitors, its actually quite unregulated. In comparison, OpenAI has been upfront about the biases in their AI image generators.
Even Google mentioned that Imagen encodes social prejudices, as its algorithms also produce content that is frequently racist, sexist, or harmful in other creative ways.
The core inspiration behind Stable Diffusion is to make AI-based image generation more accessible. However, this did not age well with time! Though the official version of Stable Diffusion contains safeguards to prevent the production of nudity or gore, since the entire code of the AI model has been made available, others have been able to remove such restrictions – allowing the public to generate explicit content and thereby adding more bias to the system. The inability to AI image generators to state or showcase how well they understood the prompt while generating results is another gray area. Even if they produce hazy or disfigured results like Craiyon, giving incorrect results can be frustrating. For example, results of individuals dressed as judges for a ‘lawyer’ prompt.
People have been motivated to quit their jobs, pursue AI art, and fantasize about the future when artificial intelligence will make it possible for them to experiment with making creative material since AI image generators have evolved so much better over the past year. The earlier generation of generative AIs was built using an algorithm known as GANs, or generative adversarial networks. GANs are notorious for their ability to create deepfakes of humans by pitting two AI models against one another to see who can better produce a picture that serves a certain purpose. In comparison, AI image generators rely on transformers initially introduced in a 2017 Google study. Transformers are trained on larger datasets that are generally web-scrapped online data, including user information from social networking sites. And every social media user is aware of the fact that social networking sites can be breeding grounds for ethnic and racial hate, coupled with content that are either sexist or misogynist. Therefore, training transformer models on online (visual) data that already leans towards human socio-ethnic bias, is something that needs to be addressed.
AI image generators are not the first instance of AI models being criticized for biased results. For instance, Microsoft created an AI chatbot to learn how to comprehend conversations a few years ago. While engaging with thousands of Twitter users, the software began to act abnormally, and in a surprising turn of events, the chatbot professed its hatred for the Jewish people and voiced allegiance to Adolf Hitler. A few years ago, Amazon’s test-market hiring tool employed artificial intelligence to provide job seekers ratings of one to five stars, akin to how customers review purchases on Amazon. In this case, Amazon’s computer models were programmed to screen candidates by studying trends in resumes sent to the company over a 10-year period, where the majority of submissions were from males, echoing the dominance of men in the tech world. As a result, Amazon’s algorithm started to favor male applicants and penalized applications that contained the phrase “women’s.”
There are a lot of stories in the news about how AI failed to stop sexist advertising, misogynistic employment practices, racist criminal justice practices, and the dissemination of misleading information. or has contributed to it. AI image generators are attracting a lot of hype, as with any other new technology, which is reasonable given that it is a truly remarkable and ground-breaking tool. But before it becomes a mass service tool we need to grasp what is happening behind the scenes. Even if these research results may be disheartening, at least we have started paying attention to how these biases seep into models. Some companies, such as OpenAI, have addressed flaws and hazards associated with their AI image generators in documentation and research, stating that the systems are prone to gender and racial prejudices.
Developers and open-source model users can use this to identify problems and nip them in the bud to prevent them from getting worse. In other words, what can the scientific and tech community do to improve things is the question.
For now, if some of the AI image generators are not open-sourced yet, it is better as their capacity to automate image-making spread racial and gender bias on a large scale is being reviewed before making it public.
NVIDIA announced in its speech AI summit that it would collaborate with Mozilla Common Voice for its new speech AI. Both NVIDIA and Mozilla Common Voice aim to speed up the growth of automatic speech recognition models.
Mozilla Common Voice is an open-source platform with multi-language datasets of voices that users can use to train any speech-enabled application. It has datasets for 34 languages, including Hindi, English, Bengali, Marathi, Tamil, and more.
NVIDIA realized that standard voice assistants such as Amazon Alexa and Google have very few of the world’s spoken languages. To solve this problem, NVIDIA and Mozilla Common Voice decided to improve linguistic inclusion in speech AI.
In the same speech AI summit, Caroline de Brito Gottlieb, product manager at NVIDIA, said that Demographic diversity is the key to capturing language diversity. She also stated that many factors, like underserved dialects, pidgins, and accents, can impact speech variation. With the NVIDIA-Mozilla Common Voice partnership, NVIDIA can create a dataset ecosystem to build speech datasets and models for any language.
NVIDIA has been developing speech AI for many use cases, like artificial speech translation, automatic speech recognition, and text-to-speech. NVIDIA’s Riva is a GPU-accelerated speech AI SDK used to build and deploy fully customizable real-time AI pipelines.
Data-centric AI is an emerging class of AI that focuses on “data” rather than the model. Generally, machine learning (ML) techniques are model-centric; they attain a static environment within which the model performs. However, most AI applications in the real world cannot always function in a static environment because several processes incorporating a machine learning approach require different processing and monitoring capabilities. To make AI applications more efficient and standardized, models are shifting to a data-centric approach or a combination of both. The new data-centric approach focuses on studying, analyzing, and utilizing data for decision-making.
Andrew Ng, a deep-learning pioneer, and founder of Landing AI has become a vocalist for data-centric AI as he believes everything comes down to data. If data is carefully prepared, organizations can accomplish the same goals with much lesser of it. To reach this stage, all organizations must shift to a data-centric approach to reap the maximum benefits of using artificial intelligence.
This shift in approach has pushed for “Active Learning (AL)” to reduce manual efforts of sampling and labeling data in ML models. Active Learning shortlists the most representative data samples for training and sends them for labeling. Only the selected sub-datasets are fed into the model to obtain more competitive results, save labeling time, and reduce training costs. While this approach saves manual data handling time, users must build an extensive backend to run those active learning pipelines. Consequently, significant engineering and coding work make active learning application challenging.
To overcome the issue, the newly proposed system at the National University of Singapore, named Active-Learning-as-a-Service (ALaaS), runs multiple strategies on datasets and performs the desired tasks by building pipelines. The server-client architecture, data manager, and AL strategy zoo are the three major components of this framework.
The system adopts a “server-client” architecture to perform scheduled jobs, making it compatible with individual devices and clouds. This architecture abstracts all necessary algorithms into web-based services users can directly use. Users only need to follow the suggested guidelines while creating a configuration file with basic settings like dataset path and desired techniques. Users can then initiate the client and the server with only a few lines of code (LoCs).
Once a user uploads the dataset and initiates the server, the data manager becomes responsible for it. The manager stores the metadata and indexes the samples to avoid redundant data movements.
Finally, the AL strategy zooabstracts the desired strategies, like Bayesian, density-driven, batch selection, etc.
Besides the three main components, others, like the model repositoryand serving engine, help automate the AL application by enabling connections with public hubs like HuggingFace, TorchHub, etc., and calling other ML serving backends for inference.
With its smartly designed architecture and components, ALaaS promises three key improvements: efficiency, modularity, and accessibility.
ALaaS makes it much more convenient to leverage active learning by provisioning optimization technologies, including pipeline generation, ML backend adoption, etc. As active learning mainly faces large-scale datasets while employing multiple computational deep learning (DL) models, dataset processing, application development, and ML backend adoption are highly crucial for efficiency.
ALaaS leverages a user-friendly experience by implementing containerized active learning services to ensure that even non-technical users can conveniently use it without getting into code details, making it highly accessible.
Active learning is advancing rapidly, mainly due to the development of deep learning techniques. Making active learning more accessible should not prevent professionals from using it for more complex projects. Due to the very modular nature of ALaaS, professionals may quickly prototype, extend, and deploy cutting-edge, state-of-the-art active learning approaches.
Such an MLOps system, as described in “Active-Learning-as-a-Service: An Efficient MLOps System for Data-Centric AI,” for leveraging data-centric AI is a significant advancement in Machine-Learning-as-a-Service. More crucially, ALaaS integrates batching, cache, and stage-level parallelism (a pipeline approach) to increase the effectiveness of active learning operations. Results from the study also show that active learning offers low latency and higher throughput than running individual jobs.
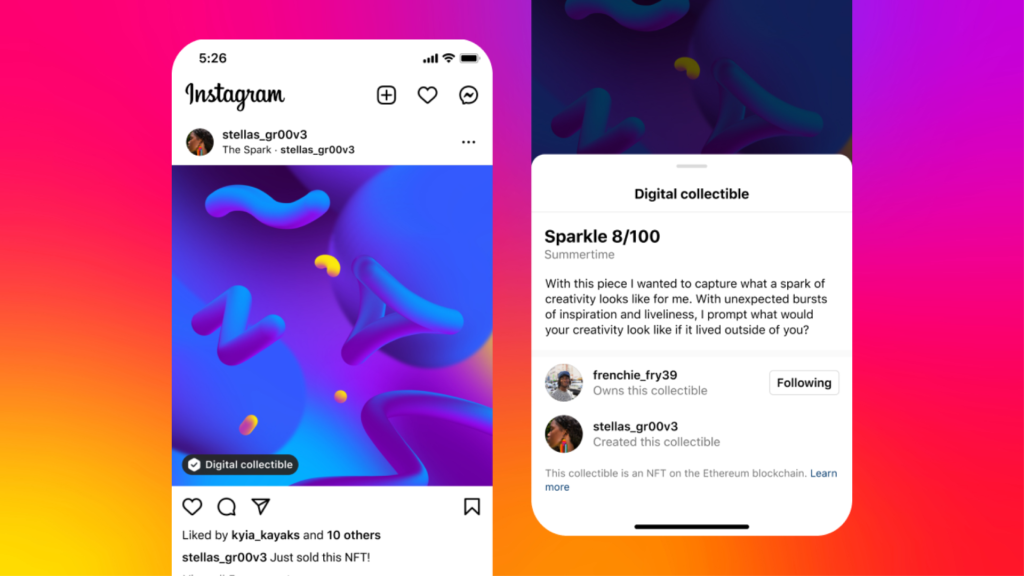
Meta has announced that it is testing, minting, and selling NFTs (or, as Meta calls it, digital collectibles) on Instagram, with a select set of creators in the United States being the first to have access to the feature.
The first group of chosen creators consists of Amber Vittoria, Dave Krugman, Refik Anadol, Isaac “Drift” Wright, Eric Rubens, Jason Seife, Vinnie Hager, Sara Baumann, Olive Allen, and Ilse Valfre. Creators will now have access to a toolbox that will enable them to produce, promote, and sell digital collectibles. Creators can showcase NFTs issued on the Polygon, Flow, Solana, and Ethereum blockchains. Similar to what Twitter does for its NFT profile image feature, Instagram will also be adding some metadata from OpenSea to the display.
Image Credit: Meta
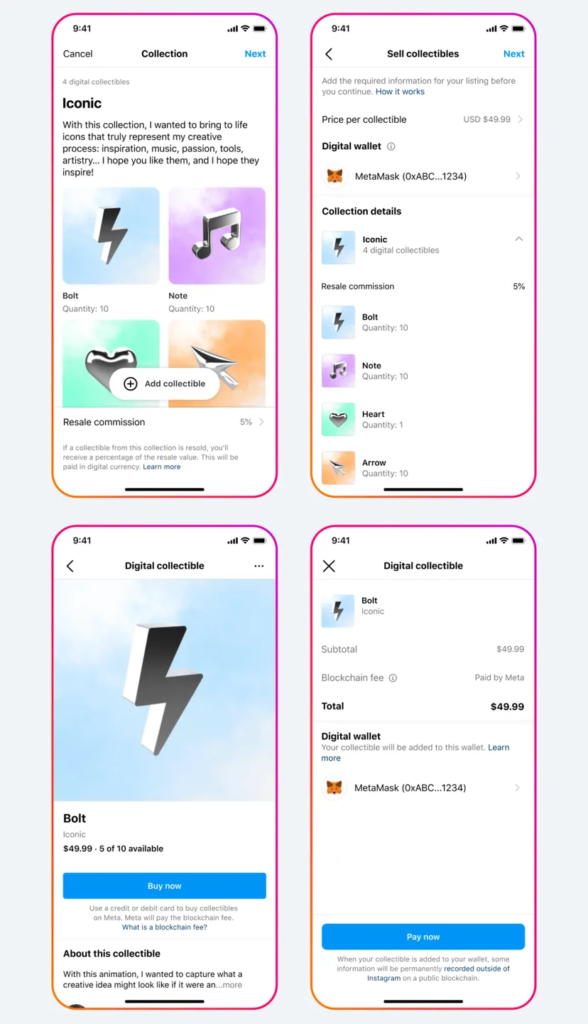
According to Meta, there will be no costs for posting and sharing digital collectibles on Facebook or Instagram, and there won’t be any further fees for selling digital collectibles until at least 2024. Moreover, it promised that for digital collectibles purchased on Instagram at launch, neither artists nor collectors would have to pay gas costs. However, it clarified that digital collectable transactions made within the Instagram app for the Android and iOS operating systems are liable for applicable app store fees.
Top: the process of making and selling NFTs on Instagram. Bottom: the process of buying an NFT on Instagram. Image Credit: Meta
It is reported that NFT creators will also be to choose their royalty portion, which will likely range from 5% to 25%. Then, creators can connect their bank account or Paypal account to get payment.
After the NFT announcements, Meta added Instagram is extending subscription access to all U.S.-based qualified creators. With a small number of producers, the social network started experimenting with subscriptions in January. The function, which was first seen on the App Store in November 2021, allows creators to charge their followers for exclusive Instagram Live videos and Stories. Subscribers are also issued a unique badge that helps them stand out in the comments area and in the inboxes of the creators.
Meanwhile, Meta is extending its professional-mode profile setting on Facebook to all creators. The professional mode is intended for usage by creators who want to utilize social networking site to monetize their fan bases. In December 2021, Facebook began testing professional mode with a small group of creators; it is now accessible to everyone on the network.
Meta also revealed that it would be launching gifts on Instagram, beginning with reels, to enable artists a new option to get paid by their followers. Fans may send gifts on reels by purchasing Stars on Instagram. Stars are virtual commodities that allow fans to show their support for their favorite creators during Facebook videos and live streams. This feature is now being tested by Meta with a select selection of American creators, and it will soon be made available to additional creators.
Further, Meta said that Facebook is extending Stars’ user base, enabling creators to get paid directly by viewers of Reels, live events, and recorded videos. Facebook will also begin testing automated creator onboarding, which will result in the ability to send stars showing up on their content without any hassles. Besides this, Stars are being added to non-video material on Facebook, such as images and textual posts.
The San Francisco-based lab, OpenAI, has launched a new program called Converge to provide early-stage AI startups with a capital of $1 million each and access to OpenAI resources.
The ten founders chosen for Converge will receive $1 million each, along with five weeks of office hours, events, and workshops with OpenAI staff. They will also receive early access to OpenAI models and programs tailored for AI companies. The deadline for application is November 25. However, OpenAI notes that it will continue to evaluate applications after the deadline for future cohorts.
When OpenAI first announced the OpenAI Startup Fund, it mentioned that the recipients of cash from the fund will also receive access to Azure resources from Microsoft. It is unclear if the same benefit will be available for Converge participants.
With Converge, OpenAI is looking to cash in on the increasingly lucrative AI industry. The Information reports that OpenAI, which is reportedly in talks to raise cash from Microsoft at a nearly $20 billion valuation, has agreed to lead the financing of Descript, an AI-powered audio and video editing app, at a valuation of around $550 million.
Edtech platform Byju’s, decided to revoke its plan to shut its operations in Thiruvananthapuram on 2 November after CEO Byju Raveendran met with Pinarayi Vijayan, Kerala’s Chief Minister.
Apart from revoking the plan to layoff and relocate 140 employees to one of its offices in Kerala, CEO Raveendran announced BYJU’s plans to hire 600 people in Thiruvananthapuram. The company has almost 3,000 people employed in Kerala.
The following update arrives as Raveendran, had written an emotional mail to the 2,500 employees on 31 October saying he is planning to layoff employees to ensure capital-efficient growth and sustainability due to adverse macroeconomic factors.
On 25 October, 170 Byju’s employees reached out to the Kerala labor commissioner K Vasuki claiming that a verbal request for a forced resignation by the company. At the same time, several media reports stated that the company had offered the laid-off employees to relocate to Kochi or Bengaluru.
Commenting on the layoff, Raveendran said he is genuinely sorry to those who will have to leave the company, adding that sackings break his heart too. He also sought forgiveness if the process was not smooth for the employees.
Raveendran said some business decisions need to be taken to protect the well-being of the larger organization, maintaining the decision did not reflect their (employees) performances and assured them support in their transition.
Elon Musk, now the sole director and CEO of Twitter, has authorized employees from other companies that he owns to work at the social media giant. These include 50 employees from Tesla, mainly from its Autopilot team, two from Boring Company, and one from Neuralink.
The employees from other companies that Musk has involved into Twitter include those that he ‘trusts’, like Tesla’s senior director of software engineering Maha Virduhagiri, director of software development Ashok Elluswamy, director of Autopilot/TeslaBot engineering Milan Kovac, and others.
Shortly after taking over, Musk fired the company’s top bosses – CEO Parag Agrawal, CFO Ned Segal, and the legal and policy head, Vijaya Gadde and dissolved the company’s board of directors.
He has now announced that Twitter will charge $8 per month for the blue verification tick that authenticates a Twitter account. Musk changed the “current lords and peasants system” for who does or does not have a blue checkmark.
“Power to the people! Blue for USD 8 per month,” he had tweeted, adding that the price is adjusted by country proportionate to purchasing power parity. Twitter already has a subscription service called Twitter Blue, which launched in June last year and offers access to features such as an option to edit tweets.






")