CAST AI, a multi-cloud company that helps developers deploy, manage, and cost-optimize applications in multiple clouds simultaneously, today announced its multi-cloud platform launch and closing of its $7.7M Series Seed round.
“We built CAST AI with a simple idea in mind – developers need tools to take advantage of everything that AWS, Azure, and other public cloud vendors have to offer. Until now, developers had to pick their preferred cloud partner. With CAST AI, our clients can deploy their infrastructure across all public cloud providers simultaneously,” said Yuri Frayman, Co-founder and CEO of CAST AI.
CAST AI enables businesses to deploy an application in a unified infrastructure that spans multiple public clouds. “We connected the clouds via a secure network mesh, allowing any cloud services of one cloud provider to be available on any other cloud. With autoscaling, we adjust compute resources in real-time, and, with the power of Kubernetes, we add workload replicas when the application needs it,” said Laurent Gil, Co-founder, and CPO of CAST AI. “This is our breakthrough, one application that spans many clouds on an infrastructure that is constantly resized to fit the application needs,” continued Laurent Gil.
The Covid-19 pandemic has massively accelerated cloud adoption. But what do cloud users find once they start scaling? Ballooning bills, growing complexity, and vendor lock-in. This means thousands of wasted DevOps hours and skyrocketing company budgets.
To combat these problems, many companies are now diversifying their infrastructure to multi-cloud. According to Gartner, more than 75% of mid-sized and large businesses will adopt a multi-cloud or hybrid cloud approach by 2021. Using multiple cloud services solves some problems, like vendor lock-in and cost optimization. But up to now, migrating to multi-cloud and managing such complicated infrastructure has been challenging and expensive.
“We went through all these struggles ourselves while trying to solve problems like stopping cloud bills from growing and saving the time of our teams. But it was only getting more complex and challenging. That was enough!” said Leon Kuperman, Co-founder, and CTO of CAST AI.
“We decided to solve this problem and finally let developers easily move their cloud infrastructures across all major providers and take advantage of everything that AWS, Azure, and Google Cloud have to offer. No more vendor lock-in, no more cloud waste. Giving the power back to developers is our mission, and we’re proud to share our platform with the world,” continued Leon Kuperman.
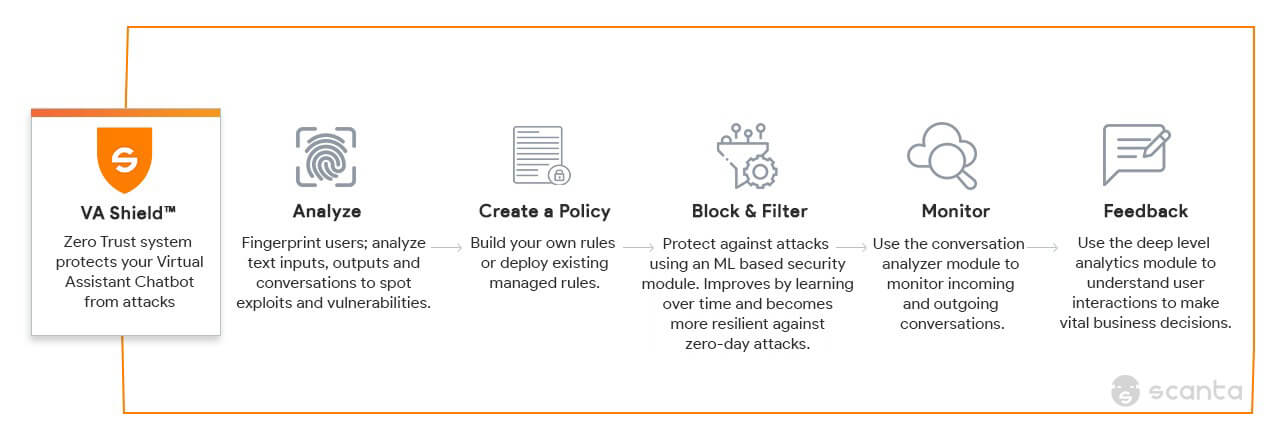
Also Read: How Scanta Is Fortifying ML-Based Chatbots From Cyberattacks
CAST AI recently raised $7.7 million from VC and angel investors for its Seed round, including a contribution from TA Ventures. “I believe that multi-cloud is the next big thing in the tech world. That’s why we invested in CAST AI. We support their mission of democratizing the cloud market and helping all developers to avoid vendor lock-in,” said Oleg Malenkov, Partner at TA Ventures.
CAST AI in its beta version attracted over 30 business clients. Launching out of stealth, the firm intends to use its Seed funding to expand sales efforts and continue investing in product development.
“As enterprises embrace digital transformation and move applications to the cloud, the centralized management of multi-cloud environments becomes critical,” said Alan Dumas, CEO of Red River, a partner of CAST AI. “CAST AI has the potential to be a game-changer for our customers by giving negotiating power back to cloud users, helping them avoid vendor lock-ins, reduce costs, and benefit from provider diversity.”
“We launched CAST AI because we believe that managing a multi-cloud setup should be as easy as buying anything online. With the backing of our investors and early clients, we are here to make the cloud a better place,” said Yuri Frayman.