


Advancement in computer vision technology can not only empower self-driving cars but also assist developers in building unbiased facial recognition solutions. However, the dearth of 3D images is impeding the development of computer vision technology. Today, most of the existing image data are in 2D, but 3D data are equally essential for researchers as well as developers to understand the real-world effectively. 3D images of varied objects can allow them to create superior computer vision solutions that can revolutionize the way we live. But, gathering 3D images is not as straightforward as collecting 2D images. It is near impossible to manually collect 3D images of every object in the world. Consequently, to mitigate one of the longest standing predicaments around 3D images, researchers from the University of Oxford proposed a novel approach of creating 3D images from 2D raw single-view images.
The effectiveness of the approach was recognized by one of the largest computer vision conferences — Computer Vision and Pattern Recognition — as the best paper of the year award.
Let us understand how researchers blazed a trail to accomplish this strenuous task of generating 3D images using single-view 2D images.
Also Read: Amazon Makes Its Machine Learning Course Free For All
Creating 3D Images
The researchers of the Visual Geometry Group, University of Oxford — Shangzhe Wu, Christian Rupprecht, and Andrea Vedaldi — introduced unsupervised learning of probably symmetric deformable 3D objects from images in the wild. The idea behind the technique is to create 3D images of symmetric objects from single-view 2D images without supervising the process. The method is based on an autoencoder — a machine learning technique to encode input images and then provide output by reconstructing it with decoders. In this work, an autoencoder factors each input image into depth, albedo, viewpoint, and illumination. While the depth is to identify the information related to the distance of surfaces of objects from a viewpoint, albedo is the reflectivity of a surface. Along with depth and albedo, viewpoint and illumination are crucial for creating 3D images as well; the variation in light and shadow is obtained from the illumination with the changing angle/viewpoint of the observer. All the aforementioned concepts play an important role in image processing to obtain 3D images. These factors will be used to generate 3D images by further processing and clubbing it back together.
To create 3D images with depth, albedo, viewpoint, and illumination, the researchers leveraged the fact that numerous objects in the world have a symmetric structure. Therefore, the research was mostly limited to symmetric objects such as human faces, cat faces, and cars from single-view images.
Challenges
Motivated to understand images more naturally for 3D image modelling, the researchers worked under two challenging conditions. Firstly, they ensured that no 2D or 3D ground truth information such as key points, segmentation, depth maps, or prior knowledge of a 3D model was utilized while training the model. Being unaware of every detail of images while generating 3D images is essential as this would eliminate the bottleneck of gathering image annotations for computer vision solutions. Secondly, the researchers had to create 3D images using only single-view images. In other words, it eliminates the need to collect multiple views of the same object. Considering these two problems was vital for the researchers because it would expedite working with fewer images while making computer vision-based applications.
Also Read: OpenAI Invites For It’s Scholars Program, Will Pay $10K Per Month
Approach
In this work, the internal decomposition of images into albedo, depth, viewpoint, and illumination was carried out without supervision. Following this, the researchers used symmetry as a geometric cue to construct 3D images with the generated four factors of input images. Although objects might never be completely symmetric, neither in shape nor appearance, the researchers compensated for their consideration later in their work. For instance, one cannot always take the left part of a face to construct the other half of the face considering symmetry, as hairstyle or expression of humans may vary. Similarly, albedo can be non-symmetric since the texture of a cat’s both sides of the face may differ. And to make the matter worse, even if both shape and albedo are symmetric, the appearance may still be different due to illumination. To mitigate these challenges, the researchers devised two approaches. They explicitly modelled illumination to recover the shape of the input objects’ images. In addition, they augmented the model to reason the absence of symmetry in objects while generating 3D images.
By combining the two methods, the researchers built an end-to-end learning formulation that delivered exceptional results compared to previous research that used an unsupervised approach for morphing 3D images. Besides, the researchers were able to outperform a recent state-of-the-art method that leveraged supervision for creating 3D images from 2D images.
Techniques Of Creating 3D Images from 2D Images
The four factors — albedo, depth, viewpoint, and illumination — that are decomposed from the input images are supposed to regenerate the image on their combination. But, due to the asymmetric nature of objects, even for the faces of humans and cats, clubbing the albedo, depth, viewpoint, and illumination, might not be able to replicate the input image in 3D. To compensate for their earlier consideration of symmetricity of objects, even though objects were not really symmetric, the researchers devised two measures. According to researchers, asymmetries arise from shape deformation, asymmetric albedo, and illumination. Therefore, they explicitly modelled asymmetric illumination. They then ensured that the model estimates a confidence score for each pixel in the input image that explains the probability of the pixel having a symmetric counterpart in the image.
The technique can be explained broadly in two different steps as follows: –
- Photo-geometric autoencoder for image formation
- How symmetries are modelled
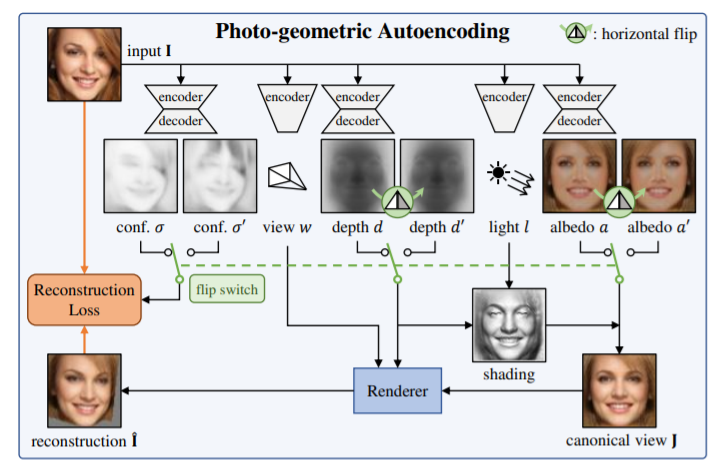
Photo-geometric autonecoder: After deforming the input images into albedo, depth, viewpoint, and illumination, the reconstruction takes place in two steps: lighting and reprojection. While the lightning function creates a version of the object based on the depth map, light direction, albedo, as seen from a canonical viewpoint, the reprojection function simulates the effect of a viewpoint change and generates images given the canonical depth and shaded canonical image.
Probably symmetric objects: Creating 3D image from 2D images requires determining the object points in images that are symmetric. By combining depth and albedo, the researchers were able to get a canonical frame. But, this process was also carried out by flipping the depth and albedo along a horizontal axis. This was embraced to get another image that was reconstructed with the flipped depth and albedo. Following this, they used the reconstruction losses of both the images that were leveraged for reasoning the symmetry probabilistically while generating the 3D images. The imperfections in created images caused blurry reconstruction. However, it was addressed by adding perceptual loss — a function to compare discrepancies among images.
Benchmarking
The model created by the researchers was put to the test on three human face datasets — CelebA, 3DFAW, and BFM. While CelebA consists of images of real human faces in the wild annotated with bounding boxes, the 3DFAW contains 23k images with 66 3D keypoint annotations, which was used for assessing the resulting 3D images. The BFM (Basel Face Model) is a synthetic face model considered for evaluating the quality of 3D reconstructions.
The researchers implemented the protocol of this paper to obtain a dataset, sampling shapes, poses, textures, and illumination randomly. They also used SUN Database for background and saved ground truth depth maps to evaluate their generated 3D images.
“Since the scale of 3D reconstruction from projective cameras is inherently ambiguous, we discount it in the evaluation. Specifically, given the depth map predicted by our model in the canonical view, we wrap it to a depth map in the actual view using the predicted viewpoint and compare the latter to the ground-truth depth map using the scale-invariant depth error (SIDE),” noted the authors in the preprint paper.
Besides, the researchers reported the mean angle deviation (MAD), which can estimate how well the surface of generated images are captured.
This comparison is carried out by a function that evaluates the depth, albedo, viewpoint, lighting, and confidence maps using individual neural networks. While encoder-decoder networks generate the depth and albedo, viewpoint and lighting are regressed using simple encoder networks.
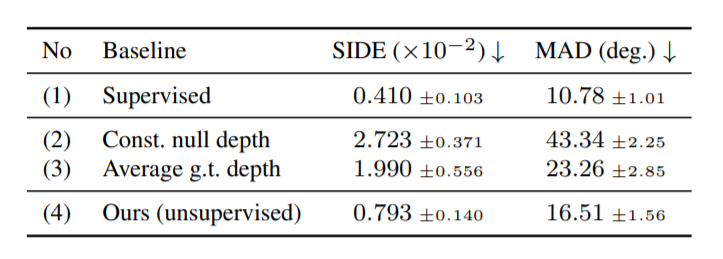
The above table compares the depth reconstruction quality achieved by leveraging photo-geometric autoencoders with other baselines: fully-supervised baseline, const. null depth, and average g.t depth (BFM dataset was used to create all the models). The unsupervised model outperforms the other models by a wider margin; a lower MAD means the deviation of generated and original images were bare minimal.
To understand how significant every step of the model construction was, the researchers evaluated the individual parts of the model by making several modifications.
Following approaches were tweaked:
- Assessment by avoiding the albedo flip
- Evaluation by ignoring the depth flip
- Predicting shading map instead of computing it from depth and light direction
- Avoiding the implementation of perceptual loss
- Replacing the ImageNet pretrained image encoder used in the perceptual loss with one trained through a self-supervised task
- Switching off the confidence maps
The result of such modification can be seen below:
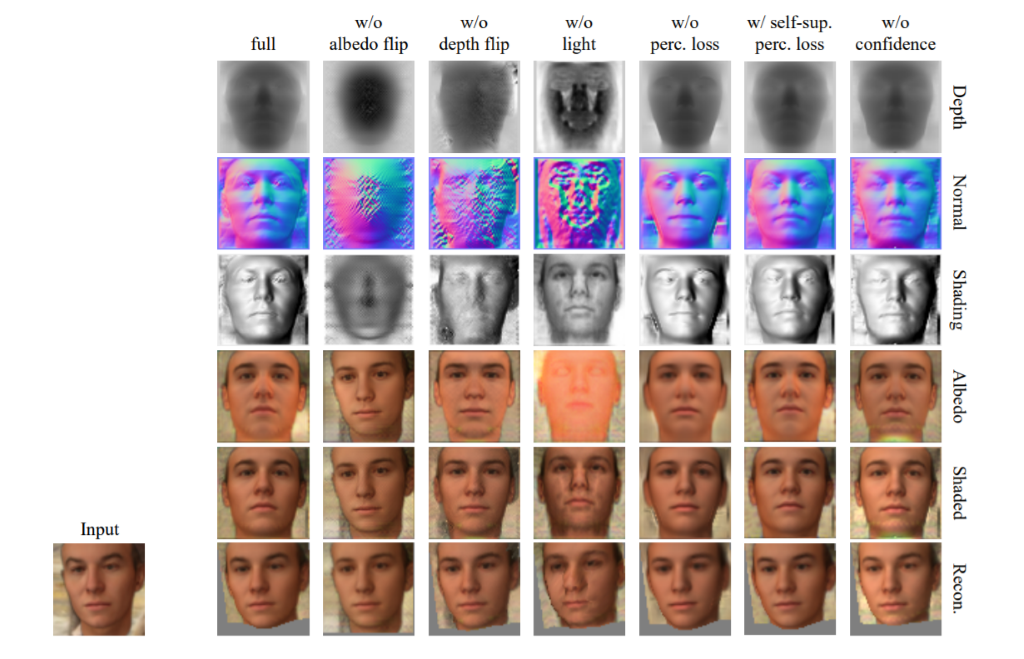
“Since our model predicts a canonical view of the objects that is symmetric about the vertical centerline of the image, we can easily visualize the symmetry plane, which is otherwise non-trivial to detect from in-the-wild images. In [the below figure], we warp the centerline of the canonical image to the predicted input viewpoint. Our method can detect symmetry planes accurately despite the presence of asymmetric texture and lighting effects,” mentioned the researchers.

Outlook
Construction of 3D images from 2D images can transform the entire computer vision landscape as it can open up the door for building groundbreaking image processing-based applications. Although the researchers devised a novel approach with their model, there are numerous shortcomings, especially with images of extreme facial expressions that need to be fixed in order to democratize the approach. Nevertheless, the model is able to generate 3D images from a single-view image of objects without supervision. In future, however, more research has to be carried out to extend the model to create 3D representation of complex objects than faces and other symmetric objects.