

")
LinkedIn Fairness Toolkit (LiFT) was released by the largest professional networking giant to enhance explainable AI initiatives by practitioners and organizations. This comes at the time when we are witnessing heated debate about the fairness of computer vision technology. Today, artificial intelligence is being used in a wide range of solutions right from identity authentication to determining defects in products and finding people with facial recognition. However, the lack of explainability in machine learning models has become a major roadblock that is hampering the proliferation of the latest technologies.
Although a wide range of libraries, services, and methodologies have been released in the last few years such as LIME, IBM Fairness 360 Toolkit, FAT-Forensics, DeepLIFT, Skater, SHAP, Rulex, Google Explainable AI, among others, the solutions have failed to democratize among users as they fail to deliver in large-scale problems or are very specific to cloud or use cases. Consequently, there was a need for a toolkit that can be leveraged across different platforms and problems.
Also Read: Creating 3D Images From 2D Images Using Autoencoder
This is where LinkedIn Fairness Toolkit bridges such gaps in the artificial intelligence landscape by enabling practitioners to deliver machine learning models to users without bias.
LinkedIn Fairness Toolkit (LiFT)
LinkedIn Fairness Toolkit is a Scala/Spark library that can evaluate biases in the entire lifecycle of model development workflows, even in large-scale machine learning projects. As per the release note of LinkedIn, the library has broad utility for organizations that wish to conduct regular analyses of the fairness of their own models and data.
Since machine learning models are now actively used in healthcare and criminal justice, it is necessary for an explainable toolkit to find correlation among different categories effectively. Consequently, LinkedIn Fairness Toolkit is a near-perfect fit for such use cases as it can be deployed to measure biases in training data, detect statistically significant differences in models’ performance across different subgroups, and evaluate fairness in ad hoc analysis.
Also Read: Amazon Makes Its Machine Learning Course Free For All
In addition, LinkedIn Fairness Toolkit comes with a unique metric-agnostic permutation testing framework that identifies statistically significant differences in model performance (as measured according to any given assessment metric) across different subgroups. However, the Evaluating Fairness Using Permutation Tests methodology will appear at KDD 2020, the authors noted.
What’s Behind LiFT?
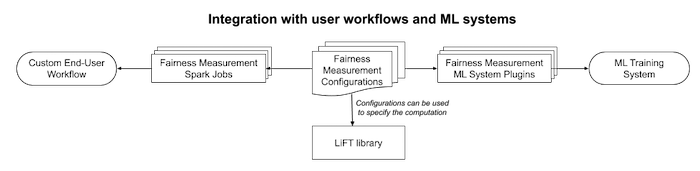
Built to work effortlessly on large scale machine learning workflows, the library can be used at any stage of the models’ development. As a result, you can carry out ad hoc analysis and still interact with the library for explainability. While the library provides flexibility as it can be used in production and even on Jupyter Notebook, for scalability while measuring bias, it leverages Apache Spark to enable you to process a colossal amount of data distributed over numerous nodes.
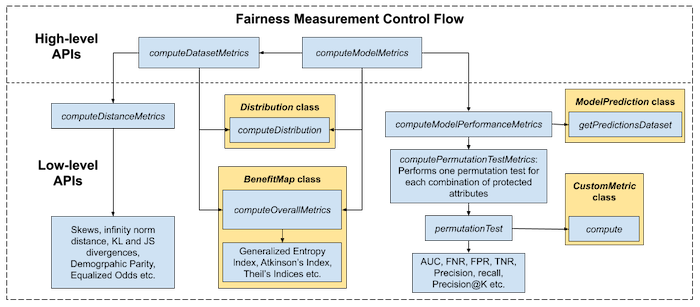
The design of the LinkedIn Fairness Toolkit also offers multiple interfaces based on the use cases with its high-level and low-level APIs for assessing fairness in models. While the high-level APIs can be used to compute metrics available, with parameterization handled by appropriate configuration classes, the low-level APIs enable users to integrate just a few metrics into their applications, or extend the provided classes to computer custom metrics.
LinkedIn has been using LinkedIn Fairness Toolkit for various machine learning models for explainability. For one, its job recommendation, when checked with LiFT, did not discriminate between gender. The model in production showed no significant difference in the probability of ranking a positive/relevant result above an irrelevant result between men and women.
Also Read: OpenAI Invites For It’s Scholars Program, Will Pay $10K Per Month
By making the library open-source, the social media giant is committed to further enhancing its functionality. The AI team at LinkedIn is also working toward bringing fairness while eliminating bias for recommendation systems and ranking problems.
To learn more about how the library was optimized for different types of tests and analysis, click here.