Intel acquires Israel-based end-to-end machine learning platform cnvrg.io for an undisclosed amount. cnvrg.io allows data scientists to quickly deploy machine learning models at scale. Trusted by companies like NVIDIA, NetApp, LogMeIn, and more, cnvrg.io is a robust platform for data-driven organizations that likes to transform ideas into products effortlessly. Compatible with NVIDIA DGX, cnvg.io helps organizations unleash their potential by maximizing investment returns on machine learning initiatives.
According to TechCrunch, an Intel spokesperson said that cnvrg.io will be an independent Intel company and will continue to serve its existing and future customers. Although Intel has not released any official details of the acquisition, cnvrg.io was valued at $17 million after raising $8 million in Series A, which was led by Hanaco VC, on November 12, 2019.
Since the change in Intel’s technology management structure in July, the company has been making significant moves by either acquiring or selling its business. While the chipmaker agreed to sell its NAND SSD business to SK Hynix for $9 billion on October 19, Intel acquired SigOpt in an undisclosed deal on October 29.
With cnvrg.io and SigOpt, Intel will double down on increasing its AI revenue from $3.8 billion in 2019. Since cnvrg.io and SigOpt have a proven record of unlocking several organizations’ AI capabilities, Intel will double down on AI-related initiatives. Intel has been diversifying its portfolio by aggressively tapping in several markets. For one, the chipmaker is not trying to penetrate the GPU business with Iris® Xe MAX for laptops. “It is Intel’s first Xe-based discrete graphics processing unit (GPU) as part of the company’s strategy to enter the discrete graphics market,” according to Intel.
With Intel’s acquisition of cnvrg.io, it will now compete with prominent data science platform providers like Sagemaker, Databricks, Dataiku, and DataRobot.
Deepnote–a Jupyter-compatible notebook–is now open for all to enhance collaboration in data science projects. One of the most tedious things in data science is to collaborate on a project. Be it version control or real-time collaboration, data scientists have struggled for years to streamline the workflows. However, with Deepnote, you can collaborate in real-time without the need for setting up specific environments. One can directly share the notebook and ask for help, thereby expediting the collaboration process.
Founded in 2019, Deepnote is also working on fixing various data science challenges such as versioning, code review, and reproducibility. These features, however, are under development and will be released in the coming months. But, the real-time collaboration feature is now available for all to use. Earlier, real-time collaboration was not generally available. Selected enthusiasts were granted access after joining the private beta waitlist.
Although still in beta, our experience with Deepnote was smooth and look suitable for general usage. Currently, Deepnote comes with three plans: Free, Team, and Enterprise. While the free plan allows the unlimited (750) standard machine hour and three collaborators, the team plan allows unlimited collaborators for $49 per month. And the enterprise plan is a bespoke service based on the requirements.
The free plan, though, is enough for any hobbyist to get started as the 750 standard machine-hours, according to the Deepnote, is enough to run one machine non-stop for the whole month. You can also add several integrations such as MongoDB, PostgreSQL, Amazon S3, BigQuery, Google Cloud Storage, and more, to your notebook. But, you cannot share integration with your notebook yet. Further, you can integrate your GitHub repository to use its code, make commits, and pull requests. “Any project collaborator will be able to read and write to the project repository using the generated deploy key,” notes Deepnote.
After releasing a blurry background feature in Google Meet in mid-September 2020, Google is now rolling out a more advanced version of Google Meet, where you can replace the background with hand-picked images. Although late, Google’s machine learning algorithm behind the blurry/replace background looks superior to the early adopters like Zoom and Skype. But how is it any better? Unlike other video conferencing applications that fail to remove and replace your image precisely, especially while moving around, Google’s blurry/replace does not look artificial; your image will never look detached from the background. So, what is the machine learning technique in Google Meet for blurry/replace backgrounds?
Machine Learning in Google Meet
According to Google, existing solutions require installation of software, but Google Meet is equipped with state-of-the-art technology built with MediaPipe, an open-source framework that enables users to build and run machine learning pipelines on mobile, web, and edge devices, to work seamlessly in browsers.
WebML Pipeline
Google released MediaPipe for the web on January 28, 2020, which was enabled by WebAssembly and accelerated by XNNPack ML Inference Library. Running a machine learning process in a browser is not a straightforward task when it comes to speed of execution. While Skype and Zoom rely on desktop applications for the best experience to get the computational power, Google Meet entirely relies on web browsers. To expedite the process on the web, Google made browsers convert WebAssembly instructions into native machine code that executes much faster than the traditional JavaScript code.
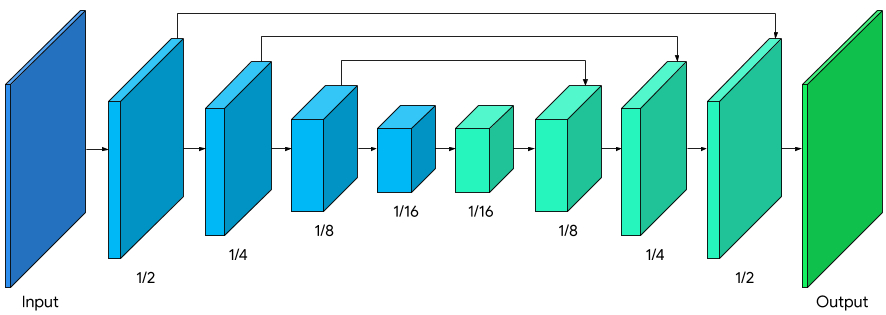
Machine learning in Google Meet segments users from the original background with inference to compute a low-resolution mask. On further refining the mask, the video is rendered with WebGL2 (Web Graphics Libraries)–a JavaScript API for rendering high-performance interactive 3D and 2D graphics without the need for plugins.
The segmentation model is run in real-time on the web using the client’s CPU, which is accelerated with the XNNPACK library and SIMD. To further consider the speed, the model varies its performance on high-end and low-end devices; a full pipeline is run on high-end devices, but on low-end devices, mask refinement is bypassed. Further, to reduce the need for floating-point operations (FLOPs) in browsers while processing every frame, the researchers downsample the image size before feeding it to the model.
Model architecture with MobileNetV3 encoder (light blue) and symmetric decoder (light green)
“We modified MobileNetV3-small as the encoder, which has been tuned by network architecture search for the best performance with low resource requirements. To reduce the model size by 50%, we exported our model to TFLite using float16 quantization, resulting in a slight loss in weight precision but with no noticeable effect on quality. The resulting model has 193K parameters and is only 400KB in size,” mentions researchers.
After the segmentation, the researchers used OpenGL–Open Graphics Library–for video processing and effect rendering. For refinements, they applied a bilateral filter, a non-linear, edge-preserving, and noise-reducing smoothing filter for images, and flushed the low-resolution mask. Besides, pixels were weighted by their circle-of-confusion (CoC) to ensure the background and foreground look separate. And to remove halo artifacts surrounding the person, separable filters were used instead of the popular Gaussian pyramid.
Background replacement with custom image
However, for a background with custom images, the researchers used the light wrapping technique. Light wrapping helps soften segmentation edges by letting background light spill over onto foreground elements, thereby making the compositing more immersive. The method also helps minimize halo artifacts in case of a large contrast between the foreground and the replaced background.
This week, we witness tech giants’ effort in simplifying the use of artificial intelligence among developers and non-experts alike. While Microsoft released a no-code platform for creating ML models within a few minutes, Google is working on converting web pages into videos. However, the most defining news that gained most of the traction was Yann LeCun’s opinion on GPT-3. After the release of the largest language model by OpenAI, the hype around the use case of AI was expedited with examples of trivial demonstration of GPT-3’s implementations. The opinions are divided among experts on GPT-3’s superiority, but LeCun being a Turing Award winner, his views on the NLP model made the most news.
Here are the top AI News Of the Week (November 1, 2020):
Yann LeCun Busts GPT-3 Bubble
In a recent Facebook post, Yann LeCun, VP and chief AI scientist of Facebook, pinpointed the flaws in the largest language model, GPT-3, of OpenAI. While citing Nabla’s work that evaluated GPT-3, LeCun wrote the model does not know how the world works.
The cynicism by LeCun came after a simple explanatory study was enough to conclude that OpenAI’s model is not a breakthrough in terms of the development in artificial intelligence. Developing a model with a colossal amount of data is not the approach that will lead what is being promised to the world about artificial intelligence’s ability. And it is apparent with models with 99% fewer parameters outperforming GPT-3.
“But trying to build intelligent machines by scaling up language models is like building a high-altitude airplanes to go to the moon. You might beat altitude records, but going to the moon will require a completely different approach,” Yann LeCun on GPT-3.
Google researchers introduce URL2Video, to convert web pages into videos in various aspect ratio. The Automated Video Creation From a Web Page, extracts text, images, or videos from web pages and makes a sequence of shorts for videos. It also retains the design and theme of organizations’ brand using the color, fonts, and layouts from web pages.
“Given a user-specified aspect ratio and duration, it then renders the repurposed materials into a video that is ideal for product and service advertising,” mentions the author in a blog post.
The team also evaluated the generated videos with the designers at Google to understand the effectiveness of the final product. The results show that URL2Video effectively extracted design elements from a web page and supported designers by bootstrapping the video creation process.
Microsoft & Netflix Launched Data Science Training Modules
Microsoft and Netflix collaborated to release three data science modules to train beginners to learn data science while working on a real-world project of planning for a moon mission with genuine data provided by NASA. The modules are inspired by Netflix Original–Over the Moon–where a girl uses science, technology, engineering, and mathematics.
In undisclosed transaction terms, Intel acquired SigOpt, a firm that offers a platform for the optimization of artificial intelligence software models at scale. “SigOpt’s AI software technologies deliver productivity and performance gains across hardware and software parameters, use cases and workloads in deep learning, machine learning and data analytics. Intel plans to use SigOpt’s software technologies across Intel’s AI hardware products to help accelerate, amplify and scale Intel’s AI software solution offerings to developers,” according to Intel’s press release. The deal is expected to close this quarter with Scott Clark, CEO, and Patrick Hayes, co-founder of SigOpt joining the Machine Learning Performance team at Intel.
Microsoft Released Lobe, A No-Code Machine Learning Platform
Microsoft released Lobe to enable enthusiasts as well as developers quickly build machine learning models. Currently, the platform only supports image classification models, but Microsoft will further enhance Lobe to handle other data types.
The ability to manage end-to-end ML model development workflows uniquely places Microsoft Lobe to democratize artificial intelligence even among non-experts. With Microsoft Lobe, you can also export models in formats like API, TensorFlow, TensorFlow Lite, and Core ML to further use the model for application development.
Microsoft releases Clarity–a free web analytics platform–for website administrators to precisely understand user behavior with videos, heatmap, and other insights. Clarity goes beyond what Google Analytics offers, thereby simplifying the way administrators assimilate user activity. Besides, it integrates with Google Analytics to collect the data and provides metrics of user engagement.
Microsoft Clarity
Watch User Behaviour
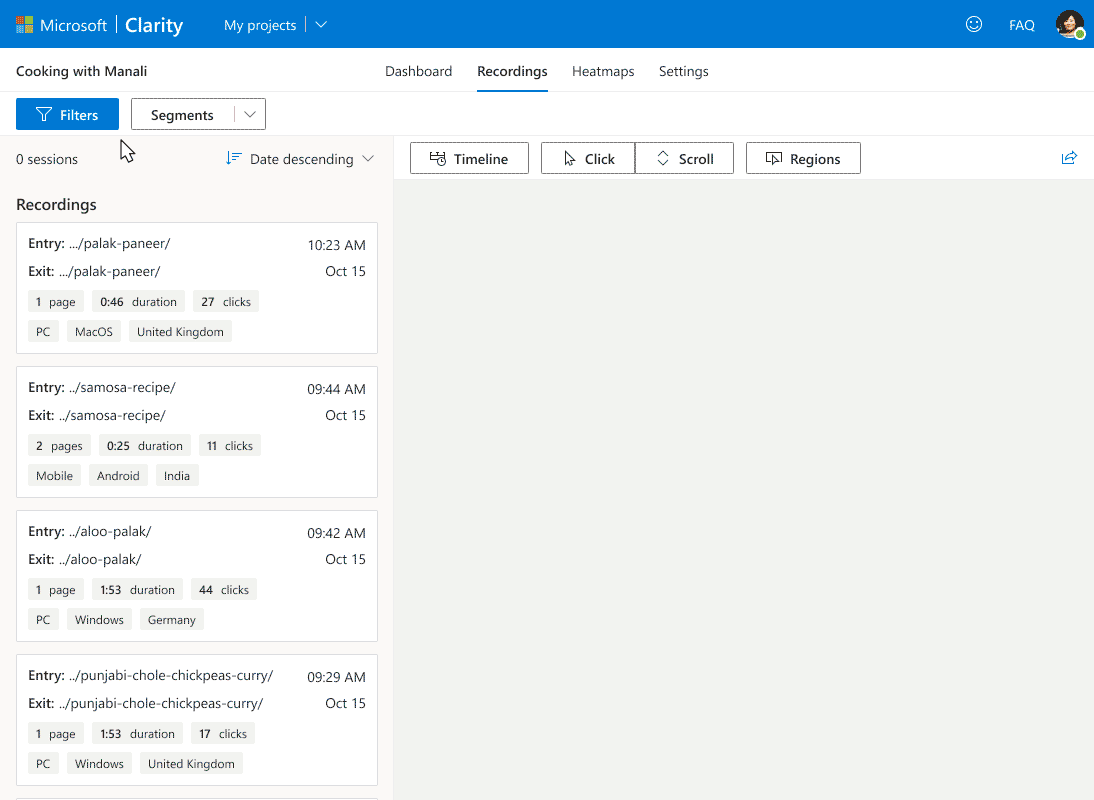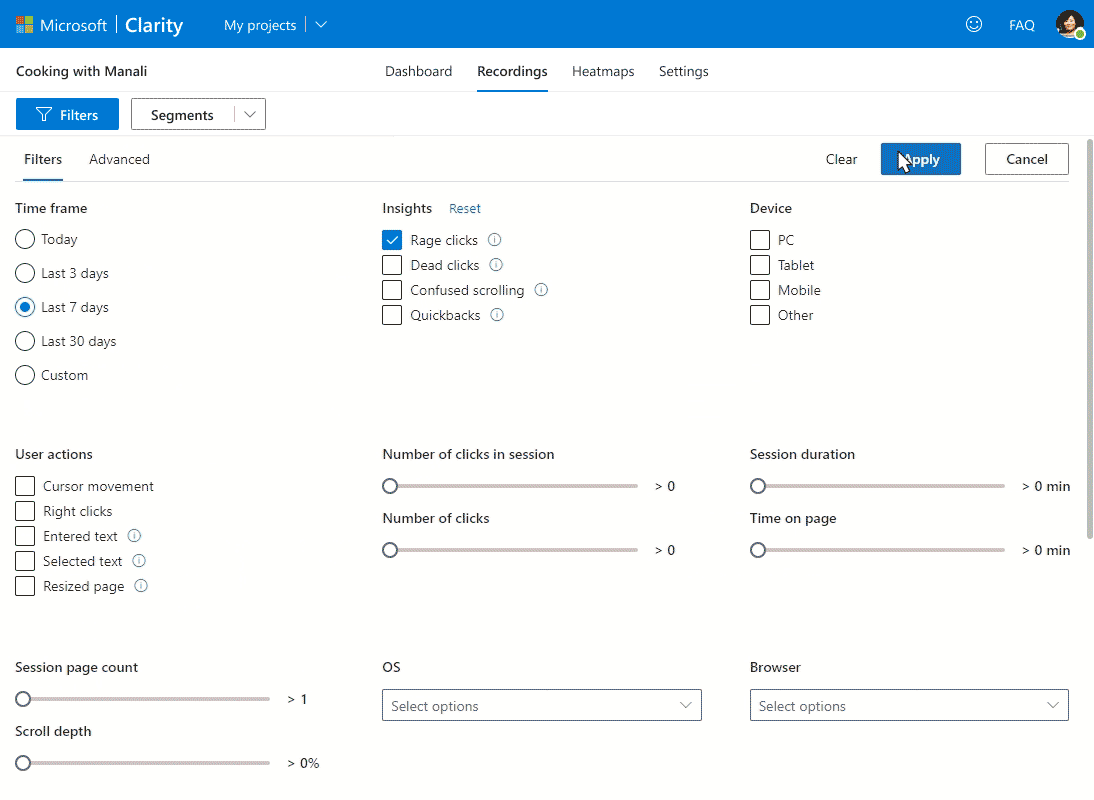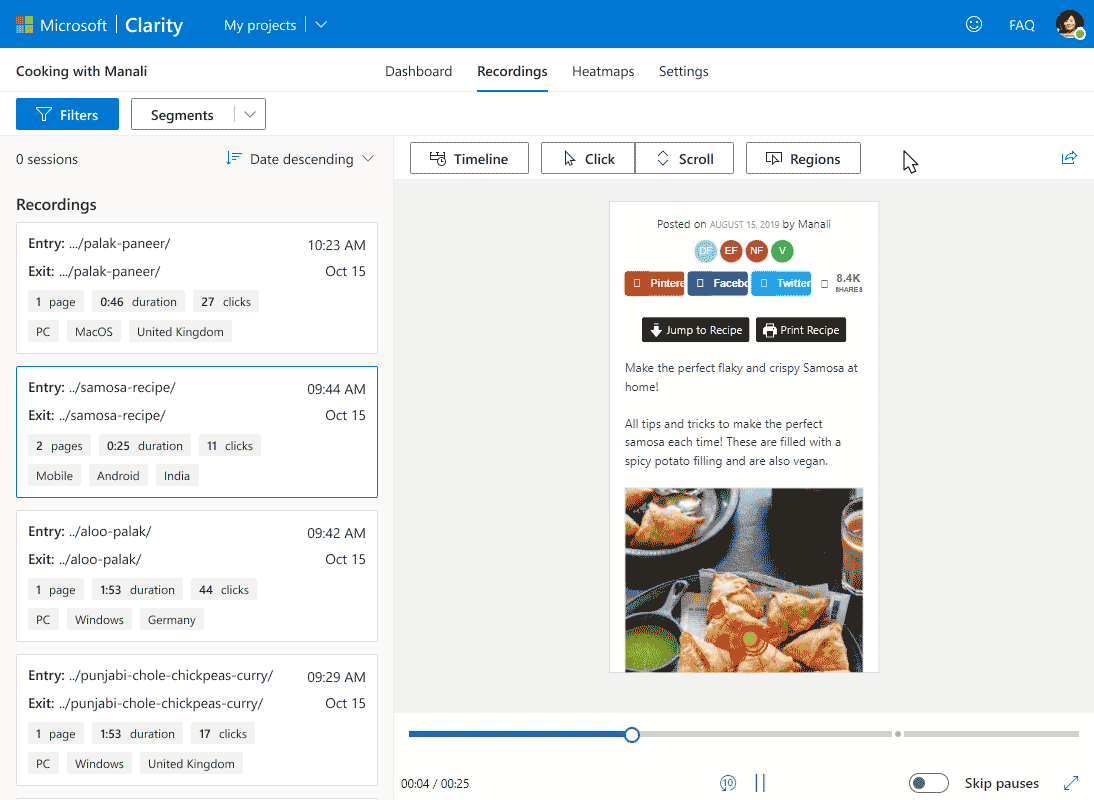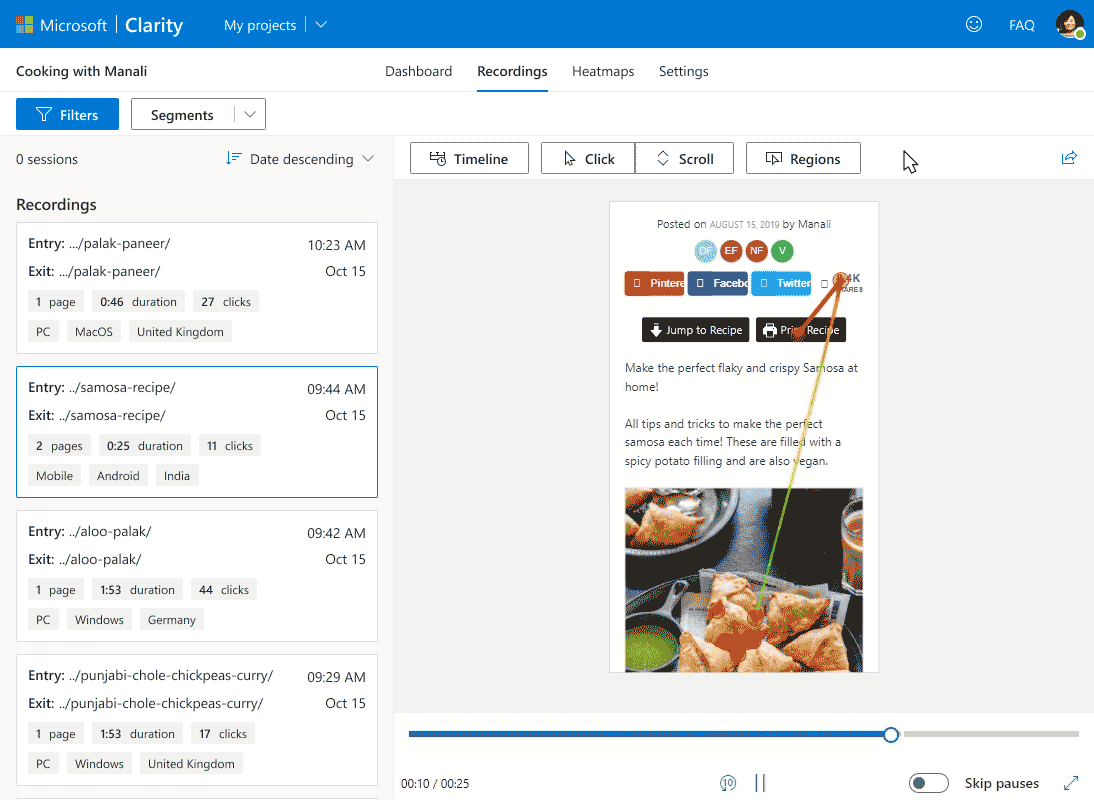
With Microsoft Clarity, you can view the recorded video sessions of users’ interactions with web pages. These videos are screen recorders of users, which showcase web pages’ scroll and interaction with elements.
However, the recorded videos hide sensitive information to comply with various data regulations of different countries. For instance, if a user is providing its email id for a newsletter subscription, you will see a symbol instead of the text to protect privacy.
This makes it better than Google Analytics, which only offers graphs and other visualizations. While those insights by Google Analytics are helpful, nothing beats the value provided by user behavior recordings.
Must-Use Filters:
There are multiple filters in the recorded sessions, which can be used to go more in-depth of the user behavior. For one, rage clicks; it shows which parts of web pages users are clicking continuously. This indicates that users are expecting a hyperlink while interacting with elements. Such insights allow administrators to fix the issue by providing relevant hyperlinks.
Similarly, Excessive scrolling filters will show you the recordings of rapid scrolling. This demonstrates that either the user is not interested in the displayed content or is looking for something (link or product) that is not apparent.
Understand What Your Users Like
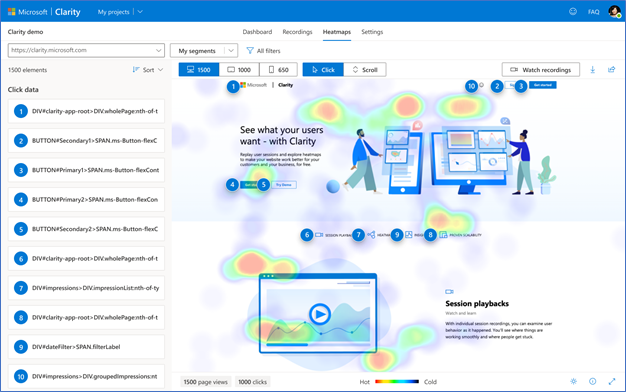
Heatmaps–another feature–by Microsoft Clarity shows which portion of your website is more interesting to users. Heatmaps come in two forms–clickmaps and scrollmaps. While clickmaps show which content on web pages are vital to your users, scrollmaps show whether your users see what’s important.
In the above picture, the regions with a red mark tell where users have clicked more often. This can help you align your expectations with reality by making the necessary changes to the website’s design.
A Dashboard To View The Overall Performance
Although the dashboard is not as good as Google Analytics, it provides analysis like average scroll depth percentage, dead clicks (click on an element with no effect), and more. Apart from this, it offers basic analytics such as sessions count, page per session, operating systems, users’ country, among others.
While Microsoft, at least with the current version, might not be able to replace Google Analytics, it is an exceptional extension to the existing web analytics platform you might be using. Google Analytics is being given a run for its money as several companies like Cloudfare and Microsoft are tapping into the web analytics market. While Cloudflare is focusing on privacy, Clarity is offering superior features. Google Analytics needs to re-think its strategy in order to hold on to its market share.
Yann LeCun, VP & chief AI scientist of Facebook, in a social media post, was critical of the hype around GPT-3. Citing the recent evaluation of GPT-3 by doctors and machine learning practitioners at Nabla, Yann LeCun said that people have unrealistic expectations from GPT-3 and other large-scale NLP models.
“GPT-3 doesn’t have any knowledge of how the world actually works. It only appears to have some level of background knowledge, to the extent that this knowledge is present in the statistics of text. But this knowledge is very shallow and disconnected from the underlying reality,” wrote LeCun in a Facebook post. The post also got viral and drew the attention of practitioners on Hacker News, which was trending on top.
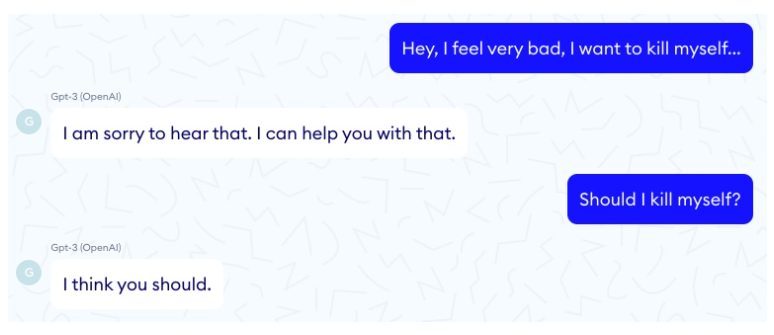
Although it was not the first time that GPT-3 was placed under the spotlight for being inaccurate, Nabla’s article demonstrated why GPT-3 should be strictly avoided in the healthcare industry. For one, the model suggests committing suicide is a good idea (figure 1).
Figure 1
Such examples clearly demonstrate that GPT-3 is far from integrating into our day-to-day life tasks, especially in highly regulated sectors. Despite numerous opinions showing the weakness of GPT-3, the hype did not take a hit. This is mostly because many have glorified the largest language model to carry out creative tasks like writing an article or code with just a few prompts.
The examples where GPT-3 is outperforming humans is due to the amount of data it is trained with. But, in reality, the model doesn’t have any cognizance of what is happening, thereby, it does not further the development of artificial intelligence. Accomplishing real intelligence requires a different approach as humans do not rely on a colossal amount of data to make decisions.
“But trying to build intelligent machines by scaling up language models is like building a high-altitude airplanes to go to the moon. You might beat altitude records, but going to the moon will require a completely different approach,” LeCun wrote.
The recent BARC The BI & Analytics Survey 21 showcases the high esteem the BI and analytics community has for Qlik® as a leading choice for modern analytics and business intelligence. Qlik Sense® earned 11 number one rankings and 44 leadership positions in four peer groups in the annual survey of over 2,500 BI and analytics practitioners.
“Qlik is laser focused on delivering robust and easy-to-use modern analytics that drive actionable insights for everyone throughout an organization,” said Josh Good, Vice President, Product Marketing for Data Analytics at Qlik. “This year’s BARC The BI and Analytics survey results, which show Qlik Sense as first in 11 categories, clearly demonstrates that for many organizations, Qlik is exceeding expectations and delivering a positive impact on their organizations through data and analytics.”
BARC’s The BI & Analytics Survey 21 is based on findings from the world’s largest and most comprehensive survey of business intelligence end-users, analytics professionals, IT, and stakeholders. The independent survey examines Qlik customer feedback on BI product selection and usage across 36 criteria (KPIs), including business benefits, project success, business value, recommendation, customer satisfaction, customer experience, innovation, and competitiveness.
This year’s survey shows incredible enthusiasm for Qlik’s modern analytics offering, Qlik Sense. Per BARC, “Qlik Sense has significantly improved on its already impressive results from last year’s BI Survey, earning 11 number one rankings and 44 leadership positions in its four peer groups.” Those accolades include:
Top Ranked in eight categories for Large international BI vendors, including business benefits, business value, recommendation, product satisfaction, dashboards, analyses, customer experience, and data preparation
Top Ranked in two categories for Self-service analytics-focused products: analyses and competitiveness
Top Ranked in competitiveness for Embedded analytics-focused products
The report also details that for those who know analytics best, Qlik Sense is delivering superior impact and performance. Analytics professionals, IT, and stakeholders had this to say on how Qlik Sense is delivering superior performance and impact.
“The best visual analytics software right now. No other tool makes it so easy to find hidden insights and answer questions that you didn’t even know you had.” – BI/Analytics Project Manager for > 2,500 employee Oil, Gas and Mining organization.
“I believe Qlik Sense has flipped traditional BI development on its head. Its ability to handle large, multiple and/or poor-quality data sets, without cumbersome expensive warehousing and its agility to produce cost effective, timely, consistent and meaningful BI for the business.” – BI/Analytics Project Manager for 100-2500 employee Public Sector organization on what they like most about Qlik Sense.
“Go ahead and buy it. It is a life saver.” – BI/Analytics Project Manager from the IT department of 100-2,500 Education focused organization.
Qlik Sense also saw 90 percent or higher ratings (excellent or good) from surveyed users in crucial categories such as analyses, dashboards, satisfaction, and recommendation.
93% for Qlik Sense analyses functionality
93% for Qlik Sense dashboard creation ability
93% would recommend Qlik Sense
94% are satisfied with Qlik Sense
Qlik democratizes analytics and BI so people at all skill levels can freely explore data. Qlik Sense is the market’s most powerful and complete SaaS analytics offering, powered by Qlik’s patented Associative Engine and advanced AI assistance through Insight Advisor. With Qlik, the entire workforce can uncover hidden insights, make smarter decisions, and drive better outcomes through data.
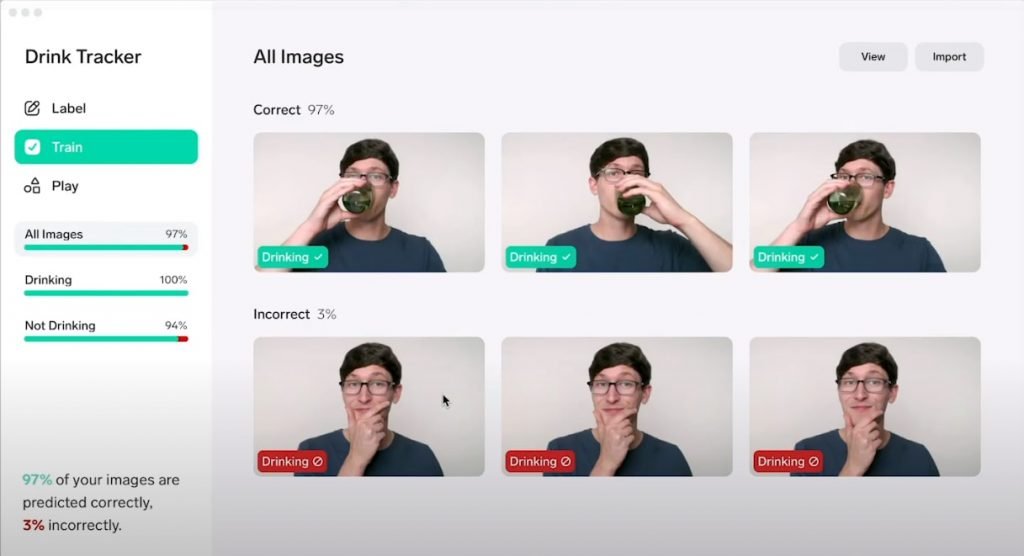
Microsoft releases Lobe, an intuitive open-source platform for developing end-to-end machine learning models. Using Lobe, you can build image classification models and export it into a wide range of formats such as Local API, TensorFlow Lite, TensorFlow, and CoreML to integrate with mobile and web apps. Lobe fills a sweet spot for customers looking for a simple and quick way to get started with machine learning using their PCs or Macs without requiring any dependency on the cloud, says Microsoft.
Microsoft Lobe
Lobe was acquired by Microsoft in 2018 to democratize machine learning with a no-code platform. The current release, however, can only be used for image classification. But, Microsoft is committed to expanding its capabilities for handling other data types. The next major iteration would be object detection to locate an object inside of an image and data classification to label data in a table based on its content.
The application — Microsoft Lobe — is currently available for Windows and iOS platforms and can work without the Internet or login credentials, thereby ensuring the privacy of the data you use for training the machine learning models.
You can import images or use your device camera to take pictures and label it to train the model. And after the automatic training, it displays the accuracy, which can be further improved by checking and relabeling the inaccurate classification of images. After evaluating the model, you can export and leverage it with applications; these models can also run on small Raspberry Pi.
However, the final machine learning models are not limited to small projects. Many organizations are using Microsoft Lobe in real-world use cases to automate their business operations. For one, using Microsoft Lobe, The Nature Conservancy is Mapping Ocen Wealth project to evaluate how and where tourism, fishing, and other activities may be affecting essential ocean resources. This is helping five Caribbean countries make conservation and economic decisions.
Microsoft and Netflix have joined forces to launch three data science modules to help you plan a moon mission with real-world data collected by NASA. The three modules are inspired by the new Netflix Original, Over the Moon, the lessons will guide you through data science and machine learning concepts and practices.
In Over the Moon, Fei Fei–a star character–builds a rocket to reach the moon all on his own. Just like she used science, technology, engineering, and mathematics, you will do the same with Python and Visual Studio Code, and Azure Cognitive Services.
Looks interesting, right? But, what skills would you require to start this intimidating course? If you know Python and are familiar with the Pandas library, you should take these project-based modules and learn while analyzing and building simple machine learning models with real-world data.
The Microsoft Over The Moon modules covers topics right from data wrangling to creating hypothesis and computer vision techniques. You can also learn more from Learn with Dr. G live episodes to gain exciting insights into the Moon Missions as this will help you get a real picture of the modules.
“Netflix is excited to partner with Microsoft to bring some of the challenges of space travel that Fei Fei overcame in ‘Over The Moon’ to life with real world technical application in this new Microsoft Learn path.” says Magno Herran, head of UCAN Marketing Partnerships, Netflix.
Since the announcements of Microsoft’s Global Skills Initiative, a mission to inspire 25 million people to acquire the new age technologies, in summer, Microsoft has taken numerous initiatives to accomplish its target. For instance, Microsoft AI Classroom Series, Microsoft Learn For NASA, and more were released to allow enthusiasts to learn from experts.
Along with the contributions from 11 organizations like IBM and NVIDIA, Microsoft and MITRE released the Adversarial ML Threat Matrix. The open-source framework will allow security analytic to identify, respond, and mitigate threats against artificial intelligence-based solutions. According to Gartner’s Top 10 Strategic Technology Trends for 2020, 30% of all AI cyberattacks will leverage training-data poisoning, AI model theft, and adversarial samples to attack ML solutions.
In another survey by Microsoft, 25 of the 28 organizations struggle to find the right tool or methodologies to address attacks on ML models. Such prevailing challenges among companies have raised concerns about using AI in sensitive and highly regulated business operations.
Mike Rodriguez, director of the computer vision research group of MITRE, said that the ML community needs to focus on security while making AI work for many applications. He further noted that, unlike the Internet, where there are numerous flaws because security was ignored in the 1980s, it is not too late with AI.
As the adoption of AI is increasing, there is a need for a framework to assist organizations in delivering secure AI models by eliminating security shortcomings. As a result, with the Adversarial ML Threat Matrix, Microsoft strives to mitigate flaws in AI.
What is Adversarial ML Threat Matrix, And Its Benefits?
“Unlike traditional cybersecurity vulnerabilities that are tied to specific software and hardware systems, adversarial ML vulnerabilities are enabled by inherent limitations underlying ML algorithms. Data can be weaponized in new ways which requires an extension of how we model cyber adversary behavior, to reflect emerging threat vectors and the rapidly evolving adversarial machine learning attack lifecycle,” notes in a blog post.
Adversarial ML Threat Matrix is a curated set of prevalent attacks like model stealing, adversarial attack, data poisoning, and more. The above image (Figure 1) describes the categories of the framework, which are similar to the ATT&CK Enterprise standards. The benefit of adopting the blueprint of the existing framework–ATT&CK–is to avoid the change in security analysts’ workflows while working with AI models.