


Microsoft enhanced its open-source deep learning optimization library DeepSpeed for empowering developers or researchers to make 1-trillion-parameters models. Initially, when the library was released on 13 February 2020, it enabled uses to build 100-billion-parameters models. With the library, practitioners of natural language processing (NLP) can train large models with reduced cost and compute while scaling to unlock new intelligence possibilities.
Today, many developers have embraced large NLP models as a go-to approach for developing superior NLP products with higher accuracy and precision. However, training large models is not straightforward. It requires computational resources for parallel processing, thereby increasing the cost. To mitigate such challenges, Microsoft, in February, also released Zero Redundancy Optimizer (ZeRO), a parallelized optimizer to reduce the need for intensive resources while scaling the models with more parameters.
ZeRO allowed users to train models with 100 billion parameters on the existing GPU clusters by 3x-5x times. In May, Microsoft released ZeRO-2 to further enhance the workflow by allowing 200 billion parameters for model training with 10x the speed of the then state-of-the-art approach.
- MIT Task Force: No Self-Driving Cars For At Least 10 Years
- A New Free Deep Learning Course By fast.ai
- Amazon Makes Its Machine Learning Course Free For All
Now, with the recent release of DeepSpeed, one can even use a single GPU for developing large models. The library includes four new system technologies that support long input sequences, high-end clusters, and low-end clusters.
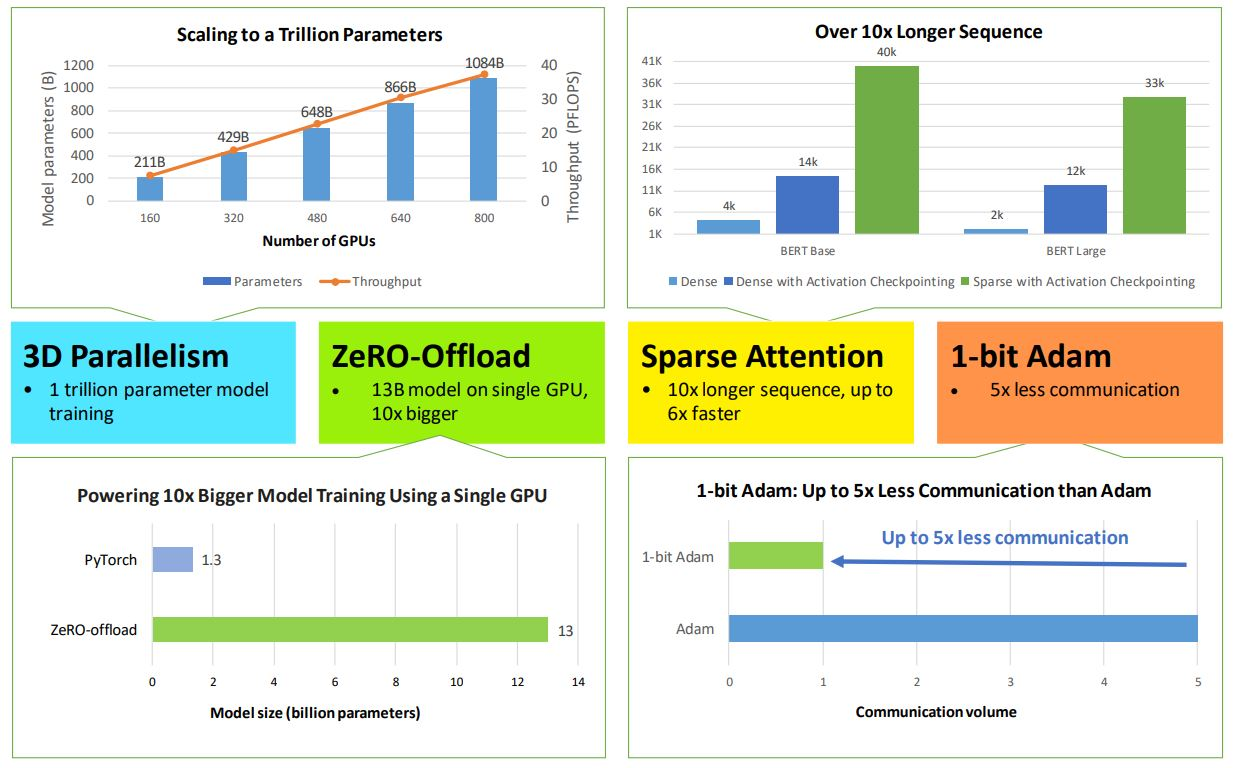
With DeepSpeed, Microsoft offers a combination of three parallelism approaches—ZeRO powered data parallelism, pipeline parallelism, and tensor-slicing model parallelism.
In addition, with ZeRO-Offload, NLP practitioners can train 10x bigger models using CPU and GPU memory. For instance, with NVIDIA V100 GPU, you can build a model up to 13 billion parameters without running out of memory.
For long sequences with text, image, and audio, DeepSpeed provides sparse attention kernels, which powers 10x longer sequences and 6x faster execution. Besides, its 1-bit Adam–a new algorithm–reduces communication volume by up to 5x. This makes the distributed training in communication-constrained scenarios 3.5x faster.