In the latest updated release of CUDA 11.3, a software development platform for building GPU-accelerated AI-based applications, NVIDIA adds direct Python support.
Now, users can build applications without relying on third-party libraries or frameworks to work with CUDA using Python. Over the years, data scientists used to leverage libraries like TensorFlow, PyTorch, CuPy, Sckit-CUDA, RAPIDS, and more to use CUDA with Python programming language.
Since these libraries had their own interoperability layer between the CUDA API and Python, data scientists’ had to remember different workflow structures. However, with the support of Python for CUDA, the development of data-based applications with NVIDIA GPUs will become a lot easier. CUDA Python is also compatible with NVIDIA Nsight Compute, allowing data scientists to gain kernel insights for performance optimization.
As Python is an interpreted language and working with parallel programming requires low-level programming, NVIDIA ensured interoperability with Driver API and NVRTC. As a result, you will still be required to write the Kernel code in C++, but this release can be the beginning of complete interoperability in the future.
On various performance tests, NVIDIA determined that the performance of CUDA Python is similar to that of working with CUDA using C++.
NVIDIA, in upcoming releases, will introduce the source code on GitHub or package through PIP and Conda to simplify the access to Cuday Python.
With CUDA 11.3, NVIDIA releases several other enhancements for developers using C++ and improved CUDA API for CUDA Graphs. The full list of the release can be accessed here.
Salesforce, a CRM provider, collaborates with NASSCOM’s FutureSkills Prime program to upskill 1 lakh aspirants by 2024 for free. The idea is to bring courses devised by Salesforce’s experts on NASSCOM’s online learning platform, FutureSkills.
Over the years, Salesforce has been offering free courses through its Trailhead platform to not only aspirants from Salesforce but also from any corner of the world. Since 2014, the year of the launch of Trailhead, over 3 million people have learned in-demand skills for free.
However, the requirement for digital skill since the pandemic has rapidly increased, as a result, there is a need to double down on such upskilling initiatives from both organizations and governments alike. As per a report from World Economic Forum, 50% of all employees will need new skills in the next five years.
Salesforce will also provide learners access to its career fails and help get a job post getting upskilled. “Trailhead is designed to remove barriers to learning by empowering anyone to skill up for the jobs of tomorrow. We are excited to be associated with NASSCOM to provide a platform for continuous learning and bridge the digital skills gap in India,” says Arundhati Bhattacharya, CEO and chairperson of Salesforce India.
NASSCOM’s FutureSkills has been continuously adding new courses on the e-learning platform since its inception. With the recent collaboration with Salesforce, the platform will allow aspirants to get mentors’ help, bring new dimensions to the platform.
Coursera, to celebrate its 9th anniversary, is offering some of the most popular courses with an option to get certified for free. The edtech platform has curated 9 courses for learners to enroll and learn for free.
Among the top courses, it has featured courses that can cater to the needs of data science aspirants and other developers, providing a much-needed opportunity for learners during the pandemic.
However, you will only have an option to choose any one of the curated 9 courses that are being offered for free.
Coursera free certification initiatives are not new for the company, during the start of the pandemic, the edtech platform had collaborated with many universities to give free courses to students. It had also collaborated with a few states in India to offer free Coursera certification.
The last day to enroll for Coursera anniversary free courses is on 30 April 2021.
NVIDIA GTC 2021, one of the largest artificial intelligence conferences, was kickstarted on April 12 with several announcements by Jensen Huang, co-founder and CEO of NVIDIA. Unlike in the past, NVIDIA GTC 2021 was free for any enthusiasts to attend. The free pass not only allowed people to watch the live sessions but also engage with other attendees.
Here are the top announcements from the NVIDIA GTC 2021: –
NVIDIA GTC 2021 Announcements
1. NVIDIA Omniverse
“We are building virtual worlds with NVIDIA Omniverse — a miraculous platform that will help build the next wave of AI for robotics and self-driving cars,” Jensen Huang, co-founder and CEO of NVIDIA. NVIDIA Omniverse is multi-GPU real-time simulation and collaboration platform for the 3D ecosystem.
With NVIDIA Omniverse, organizations can effortlessly integrate other technologies from NVIDIA to augment the development workflows. NVIDIA Omniverse consists of Nucleus, Connect, Kit, Simulation, and RTX Renderer to make it suitable for most of the AI-workloads for self-driving cars and robotics. One can also integrate third-party digital content creation (DCC) to further extend the capabilities of the NVIDIA Omniverse ecosystem and build state-of-the-art applications.
NVIDIA’s acquisition of ARM is allowing the largest graphic processing chips provider to become a one-stop shop for all the artificial intelligence processing requirements. The company introduced NVIDIA Grace — a breakthrough data center CPU for AI and HPC workloads. According to NVIDIA, the Grace CPU leverages the flexibility of Arm architecture to deliver up to 30x higher aggregate bandwidth than the current servers and 10x the performance for applications running terabytes of data. “NVIDIA is now a three-chip [CPU, GPU, and DPU] company,” said Jensen at GTC 2021.
3. BlueField-3 DPU and DOCA1.0
The increase in demand for AI-based solutions has caused strain on the cloud infrastructure to deliver the requested resources at scale, leading to the development of data processing units (DPUs). At GTC 2021, one of the top announcements was about NVIDIA BlueField-3, which will have 22 billion transistors, provide 400 Gbps networking, and integrate 16 Arm CPUs. NVIDIA BlueField-3 will offer 10x the processing capability of its predecessor, BlueField-2. NVIDIA also announced its first data center infrastructure SDK — DOCA 1.0 to — help enterprises program BlueField.
4. DGX SuperPOD
NVIDIA introduced an advanced DGX system called DGX SuperPOD, a fully integrated and network-optimized, AI-data-center-as-a-product. Several DGXs are a part of top supercomputers around the world. Even the fifth-largest supercomputer of the world, developed by NVIDIA, uses 4 DGX SuperPODs. The company also upgraded the existing DGX systems like DGX Station to expedite the process of supporting researchers develop advanced products.
5. NVIDIA Megatron
Transformer-based machine learning models like GPT-3 and Microsoft’s Turing-NLG have billions of parameters. However, these take a huge amount of computational power to build models that can process a wide range of tasks like generating code, summarise documents, superior chatbots, and more. “Model sizes are growing exponentially at a pace of doubling every two and half months,” said Jensen at GTC 2021. To allow developers to build large-scale models NVIDIA announced Megatron.
NVIDIA Megatron consists of Trition Inference Server, which will allow the distribution of large models effectively to users, thereby assisting in delivering output within seconds instead of in minutes.
6. NVIDIA Morpheus
NVIDIA announced Morpheus, which tracks the infringements in networks and collects the information that are exposed. Morpheus can visualize the entire network system and notify the absence of security and how it is impacting other applications. With Morpheus, organizations can reduce the manual efforts required for evaluating networks across the enterprise.
7. NGC Pre-Trained Models
NVIDIA also introduced new pre-trained modes — Jarvis (Conversational AI), Merlin (recommender system), Maxine (virtual collaboration), and others — as well as a platform called TAO that will allow developers to further enhance the performance of the pre-trained models from NIVIDIA with their own data. Fleet command, another offering of NVIDIA, can be leveraged to securely monitor and deploy applications at the edge.
8. Drive AV
NVIDIA Drive AV is an open programmable platform that will empower developers to build products for self-driving vehicles and robotics. NVIDIA Drive AV is a full-stack platform for every need of self-driving car manufacturers. NVIDIA is committed to further improving the platform and has released Orin, an autonomous vehicle computer. “Orin will process in one central computer the cluster, infotainment, passenger interaction AI, and very importantly, the confidence view or the perception world model,” said Jensen.
The scikit-learn team introduces a MOOC to allow aspirants to learn about the machine learning library, scikit-learn. Currently, the free course is available on a website created by Jupyter Notebook. However, the full-fledged course will be hosted on Fun MOOC in the coming months.
Any enthusiast can take this course as it is devised for learners of all categories. But, there are a few prerequisites like Python programming, NumPy, Pandas, and Matplotlib. According to the scikit-learn team, the goal of this course is to teach machine learning with scikit-learn to beginners, even without a strong technical background.
Being one of the most widely used machine learning libraries among machine learning practitioners for predictive modeling, scikit-learn is a crucial library to learn.
The course has a wide range of topics covered with a few quizzes to allow learns to gain a complete understanding of predictive machine learning. With modules like hyperparameter tuning, linear models, decision tree models, ensemble models, and more, it makes an ideal course to learn from and master the most in-demand skills.
Aspirants will also learn to create machine learning pipelines, select the best models, feature selection, evaluate model performance, and interpret features of models, making it a good mix of skills to gain for machine learning aspirants.
Intel launches its most advanced, highest-performance data center platform optimized to power the industry’s broadest range of workloads — from the cloud to the network to the intelligent edge. New 3rd Gen Intel® Xeon® Scalable processors (code-named “Ice Lake”) are the foundation of Intel’s data center platform, enabling customers to capitalize on some of the most significant business opportunities today by leveraging the power of AI.
New 3rd Gen Intel® Xeon® Scalable processors deliver a significant performance increase compared with the prior generation, with an average 46% improvement on popular data center workloads. The processors also add new and enhanced platform capabilities including Intel SGX for built-in security, and Intel Crypto Acceleration, and Intel DL Boost for AI acceleration. These new capabilities, combined with Intel’s broad portfolio of Intel® Select Solutions and Intel® Market-Ready Solutions, enable customers to accelerate deployments across cloud, AI, enterprise, HPC, networking, security, and edge applications.
“The future of technology is being shaped by several inflections, including the proliferation of the cloud, AI, the rapid adoption of 5G, and computing at the edge. As the pace of this digital disruption accelerates, Intel’s technology and leadership products are more critical than ever,” said Prakash Mallya, VP, and MD – Sales, Marketing and Communications Group, Intel India. “Intel’s new 3rd Gen Intel® Xeon® Scalable processors deliver flexible architecture with built-in acceleration and advanced security capabilities that are essential in a world of workload diversification and growing complexity. Our robust ecosystem and broad portfolio of purpose-built solutions ensure customers can rapidly deploy Intel-based infrastructure optimized for the most demanding workloads.”
In India, early adopters of the new 3rd Gen Intel® Xeon® Scalable platform include CtrlS, ESDS, Pi Datacenters, Reliance Jio, and Wipro Limited. Additionally, key hardware and software ecosystem players have market-ready solutions to enable customers to efficiently deploy Intel’s latest technologies and enhance performance across workloads.
“5G workloads will necessitate infrastructures that can seamlessly scale to support responsiveness and diverse performance requirements. The growth of data consumption, edge computing, and the rapid expansion of cloud-native 5G networks would require the evolution of processors to meet these demands. The 3rd Gen Intel® Xeon® Scalable processor is an important milestone in this evolution journey,” says Aayush Bhatnagar, Senior Vice President, Jio.
3rd Gen Intel Xeon Scalable Processors
Leveraging Intel 10 nanometer (nm) process technology, the latest 3rd Gen Intel® Xeon® Scalable processors deliver up to 40 cores per processor and up to 2.65 times higher average performance gain compared with a 5-year-old system. The platform supports up to 6 terabytes of system memory per socket, up to 8 channels of DDR4-3200 memory per socket, and up to 64 lanes of PCIe Gen4 per socket.
New 3rd Gen Intel® Xeon® Scalable processors are optimized for modern workloads that run in both on-premise and distributed multi-cloud environments. The processors provide customers with a flexible architecture including built-in acceleration and advanced security capabilities, leveraging decades of innovation.
• Built-in AI acceleration: The latest 3rd Gen Intel® Xeon® Scalable processors deliver the AI performance, productivity, and simplicity that enable customers to unlock more valuable insights from their data. As the only data center CPU with built-in AI acceleration, extensive software optimizations, and turnkey solutions, the new processors make it possible to infuse AI into every application from edge to network to cloud. The latest hardware and software optimizations deliver 74% faster AI performance compared with the prior generation and provide up to 1.5 times higher performance across a broad mix of 20 popular AI workloads versus AMD EPYC 7763 and up to 1.3 times higher performance on a broad mix of 20 popular AI workloads versus Nvidia A100 GPU.
▪ Built-in security: With hundreds of research studies and production deployments, plus the ability to be continuously hardened over time, Intel SGX protects sensitive code and data with the smallest potential attack surface within the system. It is now available on 2-socket Xeon® Scalable processors with enclaves that can isolate and process up to 1 terabyte of code and data to support the demands of mainstream workloads. Combined with new features, including Intel® Total Memory Encryption and Intel® Platform Firmware Resilience, the latest Xeon Scalable processors address today’s most pressing data protection concerns.
▪ Built-in crypto acceleration: Intel Crypto Acceleration delivers breakthrough performance across a host of important cryptographic algorithms. Businesses that run encryption-intensive workloads, such as online retailers who process millions of customer transactions per day, can leverage this capability to protect customer data without impacting user response times or overall system performance.
Additionally, to accelerate workloads on the 3rd Gen Intel® Xeon® Scalable platform, software developers can optimize their applications using oneAPI open, cross-architecture programming, which provides freedom from technical and economic burdens of proprietary models. The Intel® oneAPI Toolkits help realize the processors’ performance, AI, and encryption capabilities through advanced compilers, libraries, and analysis and debug tools.
Intel® Xeon® Scalable processors are supported by more than 500 ready-to-deploy Intel® IoT Market Ready Solutions and Intel Select Solutions that help accelerate customer deployments — with up to 80% of our Intel Select Solutions being refreshed by end of the year.
Industry-Leading Data Center Platform
Intel’s data center platforms are the most pervasive on the market, with unmatched capabilities to move, store and process data. The latest 3rd Gen Intel Xeon Scalable platform includes the Intel Optane persistent memory 200 series, Intel Optane Solid State Drive (SSD) P5800X, and Intel® SSD D5-P5316 NAND SSDs, as well as Intel Ethernet 800 Series Network Adapters and the latest Intel® Agilex FPGAs. Additional information about all these is available in the 3rd Gen Intel Xeon Scalable platform product fact sheet.
Delivering Flexible Performance Across Cloud, Networking, and Intelligent Edge
Our latest 3rd Gen Xeon Scalable platform is optimized for a wide range of market segments — from the cloud to the intelligent edge.
• For the cloud: 3rd Gen Intel Xeon Scalable processors are engineered and optimized for the demanding requirements of cloud workloads and support a wide range of service environments. Over 800 of the world’s cloud service providers run on Intel Xeon Scalable processors, and all of the largest cloud service providers are planning to offer cloud services in 2021 powered by 3rd Gen Intel Xeon Scalable processors.
• For the network: Intel’s network-optimized “N-SKUs” is designed to support diverse network environments and optimized for multiple workloads and performance levels. The latest 3rd Gen Intel Xeon Scalable processors deliver on average 62% more performance on a range of broadly deployed networks and 5G workloads over the prior generation.iv Working with a broad ecosystem of over 400 Intel® Network Builders members, Intel delivers solution blueprints based on 3rd Gen Intel Xeon Scalable processor “N SKUs,” resulting in accelerated qualification and shortened time-to-deployment for vRAN, NFVI, virtual CDN, and more.
• For the intelligent edge: 3rd Gen Intel Xeon Scalable processors deliver the performance, security, and operational controls required for powerful AI, complex image or video analytics, and consolidated workloads at the intelligent edge. The platform delivers up to 1.56 times more AI inference performance for image classification than the prior generations.
Neuralink — a moon shot project — does not look far from reality anymore as the company demonstrated a monkey playing a video game with the mind. Over the years, Musk was passionate about the capabilities of brain-machine interfaces (BMI) that could allow people to control digital devices handsfree.
But when Neuralink, in a live event, showcased Link implanted in a pig, in 2020, experts had mixed opinions. While some believed that it was groundbreaking, but for some, it was mediocre neuroscience. The criticisms, however, were valid as the company did not show any valid outcome from the signals it pulled out from 1024 channels from the Link. With the recent demonstrations by Neuralink, the company has made it clear that the signals can be effectively modeled to understand what a user wants to perform.
In the latest video, Neuralink showcased how a monkey named Pager was able to play a game with the mind. To do the unprecedented, the company placed a Link on the left and right side of the motor cortex that controls both sides of the body.
“By modeling the relationship between different patterns of neural activity and intended movement directions, we can build a model (i.e., “calibrate a decoder”) that can predict the direction and speed of an upcoming or intended movement,” mentioned the company in a blog post.
The company also believes that patterns of brain activity can be used to predict the possible control action through limbs. This can then be used to perform or control various movements like cursor movement, clicks, and more on digital devices. In the released video, we could see how it was used to control the MindPong paddle by Pager.
Neuralink used the signals from Pager’s mind while manually playing with a joystick to perform activities based on the signals from the mind while playing a different game. Just like any artificial intelligence application that can predict future events when trained on a colossal amount of data, Neuralink can scale its technology to endless possibilities by extracting data from the brain.
Such capabilities can now open up doors for a major shift in the way humans treat disease and the way they live. Neuralink is like a once-in-a-century innovation that would leave a significant impact on humankind forever.
Hyperparameter tuning is a complex skill in data science to obtain exceptional results from the machine learning models. Often data scientists have to tune and train machine learning models to check their accuracy, consuming a colossal amount of resources. Such practices not only increase the operating costs but also impedes organizations in releasing products in the market. However, to eliminate such bottlenecks, Facebook AI has introduced a self-supervised learning framework for model selection (SSL-MS) and hyperparameter tuning (SSL-HPT) to provide accurate predictions while reducing the need for computational resources.
Current Techniques Used For Hyperparameter Tuning
Over the years, data scientists have embraced grid search, random search, and Bayesian optimal search to tune hyperparameters. According to researchers, these techniques require huge computational resources as well as cannot be used for scalable time-series hyperparameter tuning. With Facebook AI’s framework, data scientists can quickly optimize the hyperparameters without hampering the accuracy of the models.
For now, the framework can be used in time-series tasks like demand forecasting, anomaly detection, capacity planning and management, and energy prediction. “Our SSL framework offers an efficient solution to provide high-quality forecasting results at a low computational cost, and short running time,” writes the researchers.
How Does Facebook AI’s Model Selection Framework Work
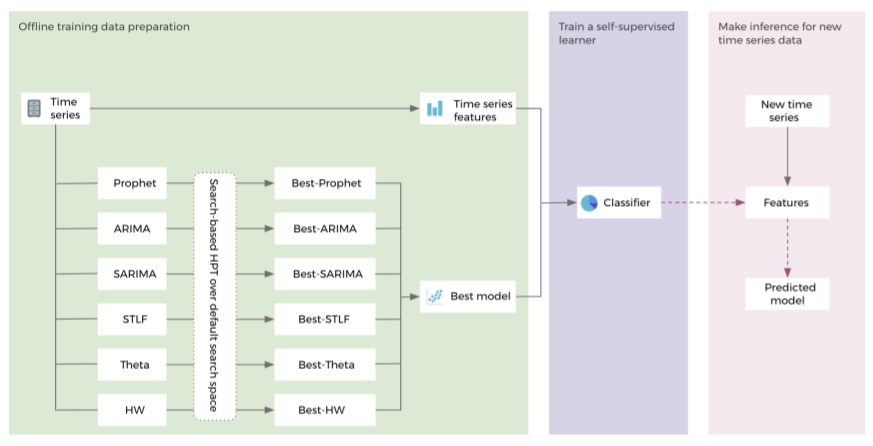
Facebook AI’s self-supervised learning model selection framework architecture consists of three stages — offline training data preparation, offline training for a classifier, and online model prediction. While the offline training data preparation assists in extracting time-series features from time-series data and the best performing model for each time series using offline exhaustive hyperparameter tuning, the offline training for a classifier is where a classifier is trained with the extracted time-series feature as input and best performing model as the label. Eventually, the online model prediction is used for extracting features from the given time series data to infer with the pre-trained classifier.
Workflow of Self-Supervised Learning for Model Selection (SSL-MS) | Credit: Facebook AI
However, only automating model sections does not assist organizations in quickly completing their projects. With time-series analysis, there is a need for having the perfect hyperparameter tuning to ensure superior accuracy of models. Hyperparameter tuning techniques like Grid search, Random search, and Bayesian Optima Search (BOP) work well with single time-series dataset but are computationally demanding. As a workaround, Facebook AI introduced a self-supervised learning framework self-supervised hyperparameter tuning (SSL-HPT).
How Does Facebook AI’s Self-Supervised Hyperparameter Work
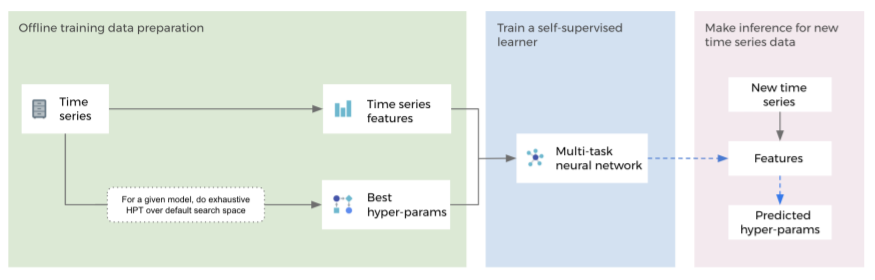
Workflow of Self-Supervised Learning for Hyper-Parameter Tuning (SSL-HPT) | Credit: Facebook AI
Similar to the model selection framework, Facebook AI’s hyperparameter tuning framework has three steps — offline training data preparation, offline training for neural network, and online hyperparameter tuning. While the offline training data preparation helps obtain time-series features and best-performed hyperparameters for models, the offline training for neural networks is carried out by training a multi-task neural network using datasets from step one. Eventually, given a new time-series data, in the final step, features are extracted, and then inferences are made using a pre-trained multi-tasks neural network. “Since SSL-HPT takes constant time to choose hyper-parameters, it makes fast and accurate forecasts at large scale become feasible,” mentions the researchers.
Integration Of Model Search And Hyperparameter Tuning
By integrating both model search and hyperparameter tuning, the speed at which developers can gain access to exceptional results gives a new dimension to the artificial intelligence landscape. Both SSL-MS and SSL-HPT are trained with the dataset collected in the first step — extracting features from time-series — and for input time-series dataset, the first model is predicted and then the hyperparameters. The computational time is constant since both SSL-learners are already trained offline, making the framework fast and reliable with large-scale workloads.
IBM launches a quantum computing certification to allow aspirants to showcase their skills by programming superior quantum computing hardware. The examination will be based on the open-source quantum toolkit, Qiskit.
Qiskit was launched by IBM in 2017 to empower developers to build applications that run on quantum chipsets. Since its release, the Qiskit team has witnessed over 600,000 installations by enthusiasts from across the globe.
📢 #IBMQuantum has announced their first developer certification today using Qiskit. We’re excited to help provide you with information on how to get free access to the exam, as well as study guides to help you prepare. Learn more here: 👇🏽https://t.co/qWIBdCcmB9
The exam will consist of 60 objective questions and would require you to correctly answer 44 questions to pass in 90 minutes. Although this exam will only focus on how to develop quantum chipsets for various applications, IBM has plans to release more certifications to help learners gain more in-depth knowledge of quantum computing.
This first certification will set the foundation for aspirants who are looking to start their careers in the quantum computing industry. To allow learners to prepare for the exam, IBM is providing learning resources of Qiskit and other sample tests. For more information, check the exam objectives.
Some of the key skills of learners this exam will evaluate are the ability to define, execute, and visualize results of quantum circuits, understand single-qubit gates and their rotations on the Bosch sphere, and fundamentals of Qiskit SDK features.
OpenMined, in collaboration with PyTorch, Facebook AI, Oxford releases the second free course of the Private AI Series. The second course — Foundations of Private Computation — is focused on educating techniques like federated learning, split neural networks, cryptography, homomorphic encryption, differential privacy, and more.
The Private AI Series includes four courses of which the first course was released early this year. Unlike the first course that sets the foundation for the entire series, the second course is technical and requires learners to have knowledge of Numpy and/or PyTorch.
The first lesson of the second course was released on 17 March and over the weeks, more lessons will be released. The second course will be of 60 hours long, which also includes a project at the end. Although it is a free course, OpenMined has ensured that learners can get their queries resolved with mentors. You can join the course discussion board or Slack community for engaging with other learners and mentors.
What makes OpenMined course stand out from the rest in the markets is its instructors, who are either developers of the tools or algorithms of privacy-related technologies or are experts in the domain.
Artificial intelligence has enormous potential to revamp the way we carry out personal or professional work. But, privacy concerns are impeding the embracement of artificial intelligence in highly regulated sectors like healthcare, finance, and more.
One of the many ways to eliminate the privacy challenges is to educate learners and develop a workforce that can bring a change by bringing trust among users. To ensure users trust providing their data on others’ hands, the artificial intelligence industry has to process data without exposing personal information.