


Facebook AI introduces DeIT (Data-efficient Image Transformer), a Transformer-based approach to train computer vision models. Over the years, Transformer has led to several breakthroughs in NLP, but the use of Transformer for image processing has been a new advancement of late. The idea behind Transformer is to move away from the popularly used image processing techniques like Convolutional Neural Networks as the new technique delivers exceptional results while decreasing the need for data and computation.
On 3 December 2020, Google also released a Transformer-based image processing technique — Visual Transformer (ViT), achieving state-of-the-art results on image classification by obtaining superior accuracy on the ImageNet dataset. They used external data that amounts to 300 million training images, which is yet to be released. But within mere 20 days, researchers from Facebook published DeIT, which was trained on a single 8-GPU node in two to three days (53 hours of pre-training, and optionally 20 hours of fine-tuning) with no external data.
Researchers from FAIR built upon Visual Transformer (ViT) architecture from Google and used patch embeddings as input. But, they introduced a new transformer-specific knowledge distillation procedure based on a distillation token that brought down the training data requirement significantly compared to ViT.
Also Read: Top Image Processing Libraries In Python
It seems that Google Brain and FAIR researchers are trying to one-up each other. The ground details are below.
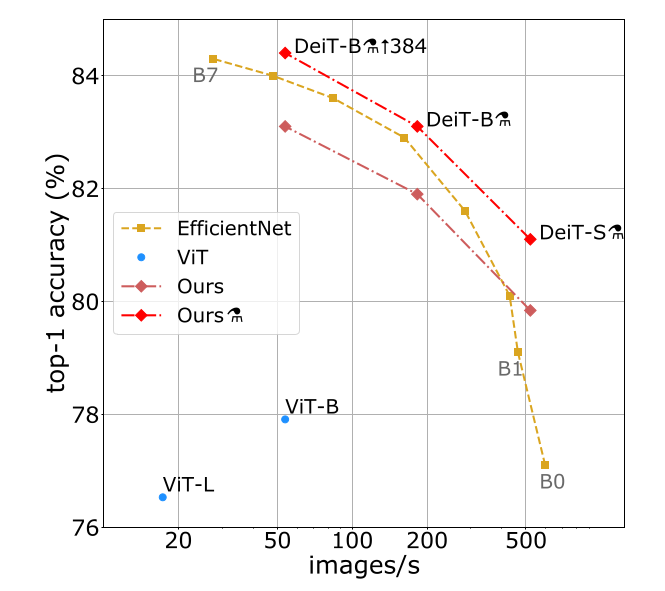
DeIT achieved competitive results against the state-of-the-art on ImageNet. When the pre-trained model was fine-tuned for fine-grained classification on several popular public benchmarks like CIFAR-10, CIFAR-100, Flowers, Stanford Cars and iNaturalist-18/19, it managed to secure the 2nd position in terms of classification accuracy in iNaturalist-18/19 with competitive scores in the rest of them.
Currently, the FAIR team has released three models with varying numbers of parameters:-

The reported tricks used to achieve such a feat are Knowledge distillation, Multi-head Self Attention layers (MSA) [with heads = 3,6,12] and certain standard image augmentation techniques like Auto-Augment and Random-Augment. They also used ADAMW optimizer and regularization techniques like Mixup and Cutmix to improve performance.