


The neuroscientists’ group at MIT-IBM Watson AI lab released VOneNets, a biologically inspired neural network fortified against adversarial attacks. VOneNets are ordinary convolutional neural networks that are more robust by simply adding a new layer, VOneBlock, that mimics the earliest stage of the brain’s visual processing system, V1.
What Is V1?
V1 is the brain’s primary visual cortex that processes visual input like static images and moving ones to recognize edges. And later, the neurons build upon the edges up to the full visual representation of the input. This behavior has inspired ConvNets that detect edges from raw pixels in the first layer, then use the nonlinear combination of edges to detect simple shapes in the next layer. These shapes are again combined in a non-linear fashion to detect higher-level features in subsequent layers. Yet, the ConvNets struggle to recognize objects in corrupted images that are easily recognized by humans.

Scientists thus carried out functional modeling of V1 to emulate the brain’s prowess for visual understanding in computers. As a result, a classical neuroscientific model, the linear-nonlinear-Poisson (LNP) model, was developed. The LNP model consists of a biologically-constrained Gabor filter bank, simple and complex cell nonlinearities, and a neuronal stochasticity generator. And this LNP model became the base of the VOneNets that are superior to ordinary ConvNets.
Also read: Optical Chips Paves The Way For Faster Machine Learning
Why VOneNets?
- Can V1 inspired computations provide adversarial robustness if used as a base for initial layers?
Yes, Li et al. had shown in an experiment that biasing a neural network’s representations towards those of the mouse’ V1 increases the robustness of grey-scale CIFAR trained neural networks to both noise and white box adversarial attacks.
- How are the activations in ConvNets and primate V1’s related in the context of adversarial robustness?
Using the “BrainScore” metric that compares activations in deep neural networks and neural responses in the brain, the scientists measured all ConvNet model’s robustness. They tested it against white-box adversarial attacks, where an attacker has full knowledge of the structure and parameters of the target neural networks. They found that the more brain-like a model was, the more robust the system was against adversarial attacks.
- How does VOneBlock simulate V1?
The LNP model of V1 consists of three consecutive processing stages — convolution, nonlinearity, and stochasticity generator — with two distinct neuronal types, simple and complex cells — each with a certain number of units per spatial location.
The VOneBlock contains elements that mimic the LNP model. A fixed-weight biologically-constrained Gabor filter bank carries the convolutions in VOneBlock to approximate the diversity of primate V1 receptive fields like color and edges. A nonlinear layer introduces nonlinearities with two different nonlinearities, ReLU for simple cell activations and spectral power of a quadrature phase-pair for complex cell activations. And the stochastic layer mimics stochastic neural behavior — repeated measurements of a neuron in response to nominally identical visual inputs resulting in different spike trains.
- How do VOneBlock is integrated into VOneNets?
The VOneNet replaces the first stack of convolutional, normalization, nonlinear, and pooling layers in a ConvNet with the VOneBlock and a trained transition layer.

- How do VOneNets perform against adversarial attacks?
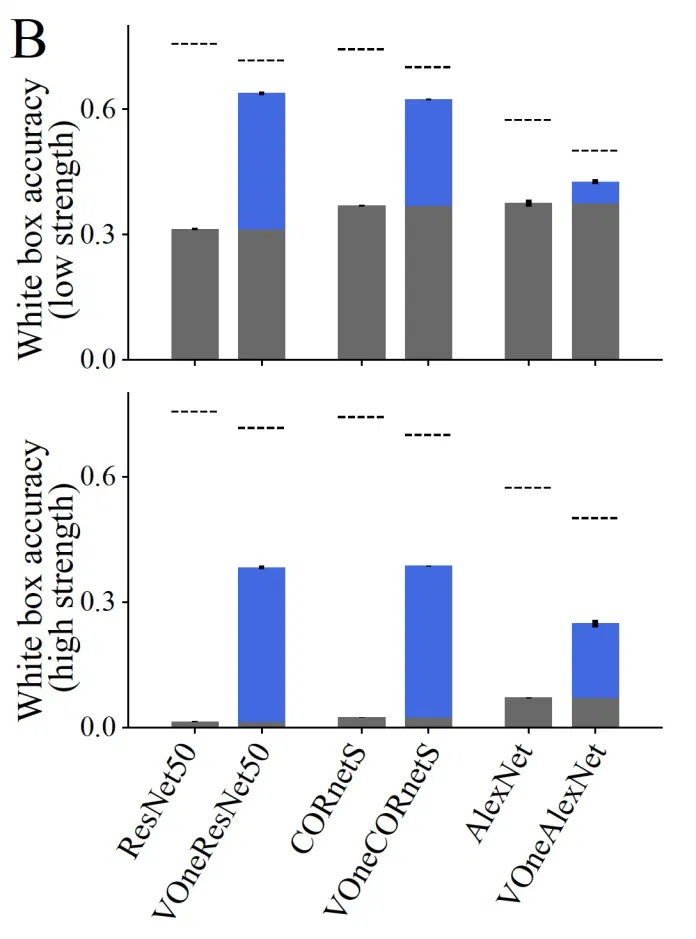
VOneNets are substantially more robust than their corresponding base models and retain high ImageNet performance after training. The adversarial robustness permeates across all architectures, hence shows the generalisability of the VOneblocks. All properties of the VOneBlock — Convolution, nonlinearities, and stochasticity — work in synergy to improve robustness to different perturbation types. And the neuronal stochastic elements at the VOneBlock level lead the downstream layers to learn more robust input features.
The blue region represents the increment in white-box accuracy over the base models.
Read about the research in detail here and find the code here.