In a first, Waymo, one of the worlds leading self-driving car companies, demonstrated how its autonomous technology could avoid fatal crashes. While all other self-driving companies are selling the future of driving without accidents, none of them have a proven track record in real-world scenario-based crashes. But Waymo came up with an evaluation of its superior technology that brings confidence among the critiques of autonomous cars.
Waymo used the data of crashes in Arizona from 2008 to 2017 from the Chandler Police Department and Arizona Department of Transportation (ADOT) and Arizona Department of Public Safety. However, Waymo excluded the data that was beyond the current operating domain of Waymo. The idea was to obtain an understanding of how Waymo’s technology would perform during each real-world crash scenario.
Using the crash data, Waymo reconstructed each crash and simulated it with Waymo Driver. In each of the crashes, Waymo Driver played an initiator and responder role. While the initiator is the vehicle that initiated the crash, the responder is the vehicle that responds to other vehicles’ actions.
Also Read: Baidu Receives Permit To Test Self-Driving Cars In California Without Safety Drivers
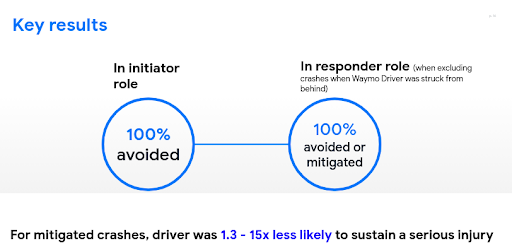
In the responder role, Waymo Driver avoided 82% of the simulated crash, and in the initiator role, it avoided every crash. Even in the responder role, where on numerous occasions a responder can do very little, it’s hit from the back. But Waymo Driver reduces the impact on such circumstances, showcasing the effectiveness of Waymo’s self-driving cars.
According to WHO, 1.3 million people die every year because of road accidents. Waymo, over the years, with constant effort, has ensured that self-driving car technology is not a fad. However, a lot of similar assurance is required to ingrain belief in the general public. As a result, Waymo also encourages other autonomous vehicle providers to make their reports publicly available.