Frontier Development Lab (FDL) researchers along with Intel AI Mentors conducted a landmark astronaut health study to adequately understand the physiological effects of radiation exposure on astronauts. The SETI Institute hosts the Frontier Development Lab in the U.S. It is in a public/private partnership with private-sector companies, NASA, and commercial AI partners. Frontier development lab used Intel artificial intelligence technology to create a first-of-its-kind algorithm to identify cancer progression biomarkers using mouse and human radiation exposure data.
Cosmic radiation can lead to health problems and cause cancer complications since it can penetrate several layers of aluminum and steel layers and affect human tissue during space travel. Since there is little data on how cosmic radiation affects astronauts from existing space missions, they need to access soiled data from various institutions that are heavily protected. FDL’s casual machine learning models don’t have to move the data between physical locations to operate on data across different areas.
Shashi Jain, strategic innovation and FDL partner manager at Intel, said that “We believe that the FDL Astronaut Health challenge results will enable NASA to understand the mechanisms involved in protecting astronauts more effectively as we return to the moon and beyond, as well as provide a blueprint to accelerate the use of AI in healthcare applications on Earth.”
Intel and FDL’s casual machine learning allows a federation of collaborator institutions to allow access to the data without moving it to separate locations. This is a testament to how public and private institutions can work together to unlock more insights that would otherwise remain buried.
FDL’s CRISP 2.0, developed by extending CRISP 1.0, leverages Intel’s Open Federated Learning framework (OpenFL). It makes it possible to drain and combine FDL’s CRISP 2.0 from institutions such as Mayo Clinic, NASA, and NASA GeneLab without moving the data to a central location.
Meta, formally known as Facebook shuts down facial recognition system. It’ll delete the “faceprints” of more than 1bn Facebook users over the coming weeks. Due to this move, people will no longer be automatically recognized in videos, memories, and photos across Facebook. This move is coming after a lawsuit accused Facebook’s tagging tech of violating Illinois’ biometric privacy law, which led to a $650 million settlement in February 2021. It was in 2018 that this case became a class-action lawsuit. However, Facebook made its facial recognition on the platform as opt-in only in 2019.
This change will also impact image descriptions for blind and visually impaired people since Automatic Alt Text (ATT) descriptions will no longer include people’s names from videos and photos on Facebook.
This change represents a more significant shift in facial recognition usage, removing over a billion people’s individual facial recognition templates from the Facebook database. Although facial recognition technology is highly valued in various cases, Meta stated that benefits have to be weighed against growing societal concerns. Additionally, the laws regarding this technology are unclear since regulators have yet to provide a set of rules for its use.
Facebook limiting its facial recognition technology will also affect services where people can verify the identity for financial products, gain access to a locked account, or unlock a personal device. The company, however, would continue working on limited but valuable use cases while ensuring that society and people have transparency and control over their right to be automatically recognized in memories, videos, and pictures.
“Making this change required us to weigh the instances where facial recognition can be helpful against the growing concerns about the use of this technology as a whole,” said Jason Grosse, a Meta spokesman. He also added that Meta has also not ruled out incorporating facial recognition technology into future products.
In this company-wide move, Meta will delete the identification templates of all people who have opted for face recognition. Facebook users will no longer be able to turn on face recognition or see a suggested tag with their name in photos, memories, and videos that they appear in. Although Facebook will delete the digital scans of facial features by December, it will not eliminate DeepFace, the software that powers the facial recognition system.
Jerome Presenti, Meta’s vice president of artificial intelligence, stated that facial recognition is valuable. However, it requires strict transparency and privacy controls so people can choose how their faces are used and recognized. He also stated that it’s best to limit facial recognition technology for a narrow set of use cases because of the ongoing uncertainty. Presenti said that face recognition is most valuable when data is not connected to a cloud server and only operates on personal devices such as unlocking smartphones or laptops.
By shutting down the Face Recognition tagging program that Facebook has used for years, Meta hopes to reinforce user confidence in its privacy protections as it prepares a rollout of potentially privacy-compromising augmented and virtual reality technology. Earlier this year, Facebook launched a pair of camera-equipped smart glasses with Ray-Ban and is gradually launching 3D virtual worlds on its Meta VR headset platform. Promoting these products and technology requires the company to garner a level of trust from regulators and users, and giving up Facebook auto-tagging after a lengthy legal battle seems a straightforward way to bolster it.
In the past decade, autonomous driving has progressed from ‘maybe possible’ to ‘now commercially available.’ Waymo, the company that emerged from Google’s self-driving car project, officially started its commercial self-driving car service in the suburbs of Phoenix in December 2018. At first, the program was available only to a few hundred vetted riders where human safety operators were always behind the wheel. However, in the past four years, Waymo has slowly opened the program to public members. Additionally, it has begun to run Robo taxis without drivers inside.
In 2009, Google began the self-driving car project, and in 2016, Alphabet bought Waymo, an autonomous driving technology company. Since then, Google’s self-driving project became Waymo. Waymo provides fully autonomous cars and has been dubbed ‘the World’s Most Experienced Driver’ by Alphabet AI.
In this article, we understand how Waymo leverages artificial intelligence to create its world-dominating self-driving technology.
Waymo’s Tech
The Waymo self-driving system has two essential parts: a highly sophisticated custom suite of sensors developed explicitly for fully autonomous operations and state-of-the-art software to make sense of the information.
Lidar is Waymo Driver’s most powerful sensor that paints a 3D picture of surroundings, allowing the system to measure the size and distance of objects around our vehicle. Lidar can measure the distance whether the things are 300 meters away or up close. Lidar sensors allow Waymo’s technology to see the world in incredible detail and identify objects in the sun on the brightest days and moonless nights.
Waymo has adopted the data centers of Google, TPUs, and the TensorFlow ecosystem, for training its neural networks. The rigorous training cycles and simulation testing allows the company to enhance its ML and autonomous system.
The platform also leverages AI to simulate sensor data gathered through its self-driving vehicles. In a recent paper, Waymo researchers introduced SurfelGAN, a technique that uses texture-mapped surface elements for reconstructing scenes and camera viewpoints to handle positions and orientations.
Advanced Sensors
Waymo claims to have built the most advanced sensor systems that have been trained with over 20 million autonomously driven miles. They have improved the current system over five generations of development. Its 5th generation Driver consists of radar, Lidar, and cameras to see 360 degrees around the vehicle.
In Waymo’s self-driving automobiles, a family of Lidar sensors uses light waves to paint rich 3D pictures, known as point clouds, allowing the Waymo Driver to see the world in incredible detail. Point clouds from Lidar can capture the distance and size of objects, allowing the software to spot pedestrians walking on a moonless night an entire city block away.
Second, Waymo vehicles are also equipped with a range of cameras that provide the Waymo Driver with different road perspectives. These cameras can capture long-range objects and help the rest of our system by adding various sources of information, providing a deeper understanding of its environment to the Waymo Driver.
Radar System
Waymo uses one of the world’s first radar imaging systems for fully autonomous vehicles that complement its cameras and Lidars. This radar can instantly perceive a pedestrian’s speed and trajectory even in challenging weather conditions, such as fog, snow, and rain, providing the Waymo Driver with unprecedented resolution, range, and field of view for safe driving.
Waymo sensors produce various types of data, including fine-grained Lidar point clouds, video footage, and radar imagery over different ranges and fields of view. The diversity of sensors allows a sensor fusion technique that improves detections and characterizations of objects.
Sensor fusion technology allows Waymo to amplify the advantages of its sensor. For example, Lidar excels at providing depth information and detecting the 3D shape of objects. At the same time, cameras can pick out visual features such as a temporary road sign and the color of traffic signals. Meanwhile, Waymo’s radar is highly effective in bad weather and can track moving objects like animals running out of a bush and onto the road.
This week, Microsoft hosts its second Ignite conference of the year. It’s an annual opportunity to showcase what the company is emphasizing and how it plans to revolutionize the way businesses work. At this event, customers get to meet with experts to obtain answers to questions about implementing and managing Microsoft technologies at the conference. This year’s user and partner event is no exception.
Microsoft introduced a slew of new capabilities for Microsoft Teams, reiterating the company’s commitment to Teams as the hub for collaboration. It also recognizes the need of improving security and collaboration capabilities, as well as explore new ways to use the metaverse in the workplace. At Microsoft Ignite 2021, Microsoft CEO Satya Nadella highlighted that 90 new services and updates will be unveiled at the Ignite conference for Fall 2021, as well as other steps Microsoft is doing to better equip customers in an age of fast digital change and broad hybrid work. Here are some of the key Microsoft Ignite announcements from the Fall Edition event:
Microsoft and Metaverse
“As the digital and physical worlds come together, we are creating an entirely new platform layer, which is the metaverse,” Nadella said during the Ignite 2021 conference.
“We’re bringing people, places and things together with the digital world, in both the consumer space as well as in the enterprise,” he added.
Just days after Facebook was renamed as Meta in an effort to establish virtual places for both consumers and companies, Microsoft is joining the battle to build a metaverse inside Teams. Next year, Microsoft will integrate Mesh, a collaboration platform for virtual experiences, into Microsoft Teams. Mesh expands on prevailing Teams features like Together mode and Presenter view, and it’s intended to make remote and hybrid meetings more collaborative and immersive by communicating to participants that they’re in the same virtual area.
Mesh will employ HoloLens headsets and Microsoft’s mixed reality technology for virtual meetings, conferences, and video conversations that Teams members may participate in as avatars. Microsoft’s Mesh technology will also let users participate in normal web- or app-based Teams meetings as both their VR versions and themselves. For Teams video conversations, there will be a 3D avatar that you can customize for yourself, and it will be available even if you don’t have a headset. Customers who do not have a device that can show 3D images will be able to view the content and avatars in 2D.
Azure OpenAI Service
One of the expected Microsoft Ignite announcements was Microsoft’s Azure cloud platform collaborating with OpenAI. The new Azure OpenAI Service will provide Azure users access to OpenAI’s GPT-3 API. GPT-3 is an autoregressive language model capable of turning natural language into direct software code, as well as summarising big text blocks with questions.
For the time being, Microsoft says Azure OpenAI Service will remain an invite-only platform. The Azure OpenAI Service will give Microsoft’s cloud clients additional options to get the best results for their businesses. It will supplement the conventional GPT-3 API in terms of security, management, and networking.
Microsoft Loop
Microsoft Loop, a new Microsoft 365 tool that pushes collaboration beyond the typical document, is based on the Fluid Framework.
Loop components, Loop pages, and Loop workspaces are the three major features of Microsoft Loop. Loop components are information pieces that you may iterate on and that function across the Microsoft 365 ecosystem. A Loop component can be a table, a to-do list, or anything else, and it’s updated in real-time with the most up-to-date information wherever it’s accessible. As explained during the Microsoft Ignite announcements, if you share a Loop table on Microsoft Teams, you can make changes right there, and they’ll appear on any website or place where the table is referenced. Loop components are described by Microsoft as “atomic units of productivity that help you collaborate and complete work right within chats and meetings, emails, documents, and more.”
Loop pages allow you to pull together all of the material connected to a project in a way that is always up-to-date since all of the components are updated in real-time wherever you share them. Loop workspaces are more akin to notebooks, in which you may organize pages into groups and sections to make things easy to discover, which is very beneficial for huge projects. Both pages and workspaces can be collaborated on by multiple users at the same time.
Azure Cosmos DB
Microsoft has also delivered on its commitment to push boundaries of data analytics capabilities of the Azure database. According to the company, one upgrade offers new functionality for Azure Cosmos DB with the purpose of making Apache Cassandra data transfer easier. As per Microsoft, Azure Managed Instance for Apache Cassandra is now broadly accessible, with an automated synchronization functionality that enables hybrid data to run in the cloud and on-premises.
Similar to Apache HBase and Google Cloud Bigtable, Cassandra is an open-source column family store NoSQL database. The Azure Cassandra service features an automated synchronization capability that allows users to sync data across their own Cassandra servers, both on-premises and in the cloud.
Microsoft adds that all Azure Advisor users may now configure alerts for throughput spending restrictions to help them keep track of their spending.
SQL Server 2022
During Executive Vice President Scott Guthrie’s keynote at Microsoft Ignite 2021 announcements: Day 1, on Tuesday morning, Microsoft announced SQL Server 2022. Because the product is still in private preview, the complete details of the release aren’t available yet. Microsoft, on the other hand, revealed some fascinating insights about the forthcoming update.
For example, SQL Server 2022 will support migrations to Managed Instance via distributed availability groups, allowing for database migrations with near-zero downtime.
Managed Instance is a platform-as-a-service (PaaS) product designed to make moving from on-premises or cloud-based virtual machines to PaaS as simple as possible. However, there were a few major difficulties that users had to deal with, e.g., performing migrations with minimal downtime necessitated a complicated database migration services solution.
From readable secondaries, SQL Server 2022 will also provide write access to the Query Store. This will provide you with more visibility into what’s going on with those secondary replicas and give you more adjusting options.
Microsoft Viva
Microsoft Viva is a Microsoft 365-based workforce platform that offers learning, resources, insights, knowledge, and communications. Until recently, the platform consisted of individual modules such as Connections, Insights, Learning, and Topics. Microsoft announced at Ignite 2021 that Microsoft Viva is now available as a full package.
Topics, Insights, Learning, and Connections are all part of the package. Microsoft Viva Insights is receiving additional capabilities to improve collaboration and productivity throughout the fully integrated platform.
Headspace’s guided meditations and mindfulness exercises in the Viva Insights app for Teams will be accessible in more languages later this month — French, German, Portuguese, and Spanish — to promote mindfulness and wellbeing throughout the workday.
Microsoft Excel API
Microsoft unveiled an upgrade to Excel that adds a new JavaScript API to the classic spreadsheet software at the Ignite conference. Developers will be able to construct custom data types and methods using this new API.
Over the last several years, Excel has begun to introduce a variety of new data kinds, first allowing users to draw in stock and geographic data from the cloud, then Power BI and Power Query data types, which allow users to deal with their own data. Customers will now be able to design their own add-ins and enhance already existing ones to leverage on data types, resulting in a more integrated, next-generation experience within Excel, according to Mircosoft. Developers can also define unique data types that are relevant to their businesses.
Azure Container Apps
Azure Container Apps is a new fully managed serverless container service from Microsoft that complements the company’s current container infrastructure offerings such as Azure Kubernetes Service (AKS). Azure Container Apps, according to Microsoft, was designed primarily for microservices, with the potential to expand fast based on HTTP traffic, events, or long-running background operations.
As per Microsoft, with Azure Container Apps, developers will be able to design their apps in the language and framework of their choice and then deploy them using this new service.
Azure Stack HCI
Microsoft’s Azure Stack HCI hyper-converged infrastructure solution has been enhanced to include GPU for AI and machine learning, soft kernel reboot, thin provisioning, and other infrastructure-level features. Virtual machine creation and administration through the Azure portal are among the management-level changes. All Azure Stack HCI integrated systems now include server core security.
A new Azure Stack HCI partner program allows users with additional certified solutions and services from independent software providers.
Microsoft has released a preview of Azure Virtual Desktop for Azure Stack HCI, as well as new autoscale functionality for AVD that allows users to plan the start and stop of session hosts.
Context IQ
Context IQ is another new Microsoft Office experience unveiled at Ignite Fall Edition. This is an artificial intelligence service that may provide you with relevant ideas and information at any moment. Microsoft Editor, the company’s spellchecking and proofreading product, will be the first platform to benefit from Context IQ. Context IQ allows Editor to not only fix what you’ve typed but also forecast what information you’ll want to write. It can, for instance, recommend files to share with a coworker based on projects you’re working on when you try to schedule a meeting through email, and it can do much more.
Context IQ may recommend related Dynamics 365 sales records plugins as well as third-party plugins like Jira, Zoho, and SAP. Users will be able to enter information without having to switch between email or other apps. In Teams, pressing Tab will prompt the Editor to finish a statement, such as when booking a trip online and entering a frequent flier number.
Azure Chaos Studio
Microsoft has released a preview of Azure Chaos Studio, a tool for experimenting with application resilience. The platform includes a library of errors caused by agents or services, as well as continuous validation to ensure that product quality is maintained.
Users of Chaos Studio may deliberately interrupt programs with network delay, unexpected storage failures, secret expiration, a full data center outage, and other real-world events to uncover weaknesses and create mitigations before users are affected.
Microsoft Edge on Linux
Microsoft Edge has been out of beta for almost a year on Windows and macOS desktops, and the browser is finally ready for a new platform. Microsoft revealed during the Microsoft Ignite 2021 event announcements that Edge is now fully accessible on Linux in the stable channel.
This implies Edge has finally caught up to Google Chrome and Mozilla Firefox, both of which have long been available for Linux distribution. You may get Microsoft Edge for Linux by visiting the Edge download website and downloading the .deb or .rpm package. Microsoft is commemorating the release of Edge Stable on Linux with a bonus of the Edge Surf game.
Dynamics 365
Microsoft unveiled three new Dynamics 365 capabilities, each with varying levels of availability, to help businesses better their connections with customers, workers, and suppliers. These new tools are Dynamics 365 Supply Chain Insights, Dynamics 365 Customer Service voice channel, and Dynamics 365 Connected Spaces.
Dynamics 365 Supply Chain Insights assists organizations in avoiding possible supply interruptions by providing data “in near real-time” from multiple partners, such as logistics partners, data providers, and suppliers. The technology, which is now in preview, allows businesses to establish a digital version of their physical supply chain and improve end-to-end visibility throughout their whole value chain.
It also integrates data on global events that might have an influence on supply chains, such as political upheaval, natural catastrophes, or pandemic resurgences.
Dynamics 365 Customer Service voice channel is a voice-enabled, SaaS-based customer service application that is now generally accessible. According to Microsoft, it’s built on Microsoft Teams technology and combines the capabilities of conventional Contact Center as a Service (CCaaS), Unified Communications as a Service (UCaaS), and Customer Engagement Center (CEC) into a single solution.
Dynamics 365 Connected Spaces, which will be available as a preview in early December, allows businesses to harness observational data with ease, leverage AI-powered models to discover insights about your surroundings, and respond in real-time to trends and patterns.
Microsoft Defender for Business
Microsoft has unveiled a brand-new security suite tailored to the dangers that small and medium-sized organizations face at the Microsoft Ignite fall edition. Called Microsoft Defender for Business, which was launched today at Microsoft Ignite 2021, will try to offer what Microsoft calls “enterprise-grade endpoint protection” from Microsoft Defender for Endpoint to businesses with 300 or fewer employees.
Defender for Business, which is specifically built to defend organizations from malware and ransomware on Windows, macOS, iOS, and Android devices, will enable clients to construct a secure foundation by finding and correcting software vulnerabilities and misconfigurations. Its Endpoint detection and response (EDR) feature will assist SMBs in identifying persistent threats and removing them from their environments using behavioral-based detection and response alerts. It can also minimize alert volume and remediates threats.
You can watch the Microsoft Ignite Fall Edition 2021:Day 1 here:
United States-based software developing company Synopsys acquires artificial intelligence-enabled real-time performance optimization leader Concertio. Company officials have not provided any information regarding the valuation of the acquisition deal.
With this acquisition, Synopsys wants to further enhance its SiliconMAX Silicon Lifecycle Management platform. Synopsys plans to use the expertise of Concertio to maximize the performance of its platform, including manufacturing, product ramp, in-field operations, and product test.
General manager of Silicon Realization Group at Synopsys, Shankar Krishnamoorthy, said, “This acquisition of Concertio reflects our commitment to aggressively expand the capabilities and benefits of the SiliconMAX SLM platform to address our customers’ rapidly evolving silicon and system health needs.”
He further added that lifecycle management systems have become critical to successfully deploy and operate advanced electronic systems. Concertio’s unique artificial intelligence-enabled performance optimizer will enable Synopsis to boost the performance of many devices like automotive and industrial IoT.
Concertio’s software gets directly installed in the desired device and monitors its interaction. The software uses artificial intelligence technologies like reinforced learning to learn how the device interacts and then optimize them to enhance performance.
Concertio is a United States-based software firm that was founded by Tomer Morad, Timer Paz, and Andrey Gelman in the year 2016. Since its establishment, the company has earned a high reputation in its industry by providing best-in-class performance optimization solutions.
Concerto had raised over $4 million in its seed funding round from investors like Differential Ventures, NextLeap Ventures, and Big Red Ventures before being acquired by Synopsys.
Canada-based artificial intelligence solutions developing company Stallion AI has partnered with Rochester Institute of Technology (RTI) Dubai to award artificial intelligence citizenship. The newly launched joint program named 365 Digital AI Citizenship will help students from diverse backgrounds in becoming certified artificial intelligence citizens.
The program will provide personalized study plans to students and offer them access to a global network of industry experts so that students can carve their career pathways. The course will be available for students of RTI Dubai and will provide comprehensive knowledge and understanding for them to operate in artificial intelligence-powered environments.
CEO of Stallion AI, Samer Obeidat, said, “The biggest barrier to optimising the technology is the lack of knowledge and skills, so introducing young people to AI through this Citizenship program will ensure that they are highly sought after employees of the future, with the ability to both utilise and enhance AI functions in the workplace.”
He further added that artificial intelligence would impact jobs of all sectors, so it has become essential for students to have an understanding of artificial intelligence technologies and their applications.
According to the report, over 86% of surveyed workers claimed that artificial intelligence is an integral part of their day-to-day jobs. Hence this unique course will train students in artificial intelligence to help them better adjust to the changing work environment. Experts believe that artificial intelligence technologies will add over $15 trillion to the global economy by the end of 2030.
President of RTI Dubai, Dr. Yousef Al Assaf, said, “Artificial intelligence is an increasingly critical component of the global economy and, as Certified AI Citizens, our graduates will be equipped with the knowledge, skills and experience to play a leading role in this future-defining technology.”
He also mentioned that they are excited for this new collaboration with Stallion AI, and this is a step forwards towards the institute’s goal of going beyond traditional university education.
Amid the concerns that Moore’s law is grasping the last straws in the semiconductor industry, neuromorphic chips can be a revolutionary solution. Though silicon has blessed us in making computers take over the tech world, the limitations of miniaturization of silicon-based transistors are finally catching up. Even artificial intelligence models need to go beyond the emulated classical logic and self-learning by perception for deriving reasoned conclusions. While neuromorphic computing is founded on the notion of replicating the function of the human brain, it has its own challenges too.
Researchers from Germany’s Max Planck Institute of Microstructure Physics and SEMRON GmbH have developed new energy-efficient memcapacitive devices (memory capacitors) that might be used to perform machine-learning algorithms. These devices, which were described in a study published in Nature Electronics, function by utilizing a charge shielding mechanism.
Image Credit: Demasius, Kirschen & Parkin.
Memory circuit elements (memelements) are multidimensional electronic devices that have memory capability and whose resistance, capacitance, or inductance is determined by a previously applied voltage, charge, current, or flux. As a result, they mimic synapses, which are the connections between neurons in the brain, and whose electrical conductivity varies depending on how much electrical charge has traveled through them before.
Memristors, also known as memory resistors, are a type of electrical circuit building block that was hypothesized around 50 years ago but was developed for the first time a little more than a decade ago. Memcapacitive devices are related to memristive devices, however they work on a capacitive principle and may have lower static power consumption. In comparison, much research was not carried out using memcapacitive devices due to a lack of functional materials or systems whose capacitance can be controlled by external variables.
Neuromorphic computing aims to solve a wide range of computationally challenging jobs. Neuromorphic computers can do complicated calculations quicker, more effectively, and with a smaller footprint than classic von Neumann designs. These attributes provide strong motivations for building hardware that leverages neuromorphic architectures. The interest in designing such chips and devices is also backed by the possibility of augmenting the overall training and efficiency of artificial intelligence systems. Further, neural networks are getting more data-hungry than ever which directly influences the energy demands of training those models.
As per Kai-Uwe Demasius, one of the study’s researchers, the team discovered that, in addition to traditional digital ways for operating neural networks, there were largely memristive approaches and just a few memcapacitive suggestions. Not only that, the team also observed that all commercially available AI processors are digital/mixed-signal based, with only a few chips using resistive memory devices. This motivated them to look at a different technique based on a capacitive memory device.
While examining previous research, Demasius and his colleagues have found that all existing memcapacitive devices were difficult to scale up and had a low dynamic range. As a result, they set out to create more efficient and scalable technologies. They drew inspiration for their innovative memcapacitive technology from synapses and neurotransmitters in the brain.
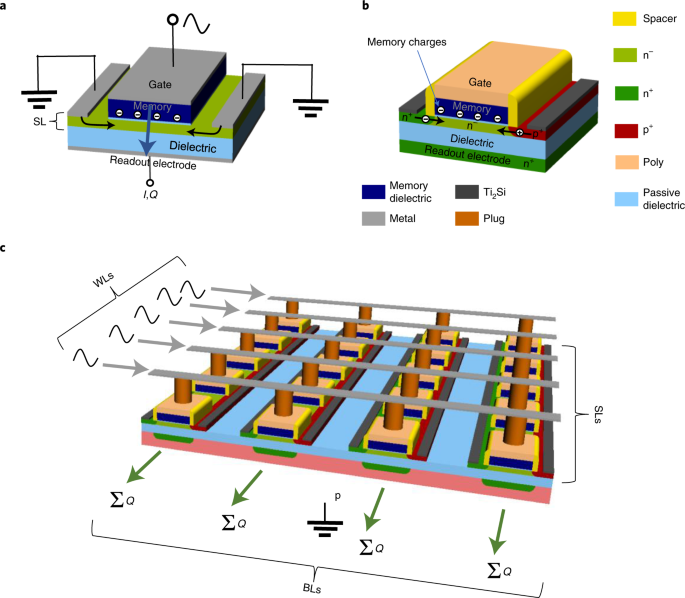
a, General device structure with a gate electrode, shielding layer (SL) and readout electrode (I, current; Q, charge). The electric field coupling is indicated by the blue arrow. b, Device structure with a lateral pin junction as well as electron and hole injection. c, Crossbar arrangement of the device in b, where a.c. input signals are applied to the word lines (WLs) and the accumulated charge is read out at the bit lines (BLs). During readout, the SL is mostly connected to GND. Source: Nature
The researchers’ memcapacitive device has a top gate electrode, a shielding layer containing contacts, and a back-side readout electrode; these layers are segmented using dielectric layers. Here, the shielding layer can either transmit or strongly shield an electric field. An analog memory is used to alter this shielding layer by storing the varying weight values of artificial neural networks which is akin to how neurotransmitters in the brain store and transfer information. The top dielectric layer may have a memory effect, such as charge trapping or ferroelectricity, which may impact the shielding layer, or the shielding layer may have a memory effect.
Because memcapacitor devices are based on electric fields rather than currents, and have a greater signal-to-noise ratio, they are intrinsically several times more energy-efficient than memristive devices. Also, being based on charge screening, it allows for far greater scalability and a larger dynamic range than previous experiments on memcapacitive devices. Simply applying an external voltage to a doped junction or the influence of non-volatile memory in an upper dielectric layer can change the shielding layer’s properties.
To test the effectiveness of their memcapacitor devices, the researchers grouped 156 of them in a crossbar pattern, then used them to train a neural network to distinguish three different roman alphabet characters (“M,” “P,” and “I”). Their devices achieved astonishing energy efficiency of over 3,500 TOPS/W at 8 Bit precision, which is 35 to 300 times higher than other known memresistive techniques. These results show that the team’s novel memcapacitors have the ability to operate huge and complicated deep learning models with very low power consumption (in the μW regime).
As speech recognition software will go mainstream in the future, they will rely on the computing prowess of large neural network-based models with billions of parameters. Demasius and his colleagues are positive that their groundbreaking work in memcapacitor devices can usher a momentous impact in the future of artificial intelligence and neuromorphic applications. The team hopes to develop additional neural network-based models in the future, as well as scale up the memcapacitor-based system they created by boosting its efficiency and device density.
The Food and Drug Administration releases new ethical guidelines for the development of artificial intelligence and machine learning technologies for the healthcare industry. FDA, Health Canada, the United Kingdom’s Medicines, and Healthcare products Regulatory Agency (MHRA) have jointly issued a statement mentioning ten guidelines that researchers have to follow while developing artificial intelligence technologies.
The agencies have meticulously reviewed the newly issued guidelines for the safe and effective use of AI solutions for diagnosis and treatment of patients. In recent years, artificial intelligence has widely impacted the healthcare industry as developers create new solutions to enhance treatment and diagnosis quality for several health conditions like heart sickness, cancer, tumor, and many more.
The guidelines will also work as international regulation of the development of ethical and safe AI healthcare technologies. FDA mentioned that areas of international collaboration would include research, consumer standards, global homogeneous solution development, and creating educational tools.
Below mentioned are the guidelines issued by government organizations.
Multi-Disciplinary Expertise Is Leveraged Throughout the Total Product Life Cycle
Good Software Engineering and Security Practices Are Implemented
Clinical Study Participants and Data Sets Are Representative of the Intended Patient Population
Training Data Sets Are Independent of Test Sets
Selected Reference Datasets Are Based Upon Best Available Methods
Model Design Is Tailored to the Available Data and Reflects the Intended Use of the Device
Focus Is Placed on the Performance of the Human-AI Team
Testing Demonstrates Device Performance during Clinically Relevant Conditions
Users Are Provided Clear, Essential Information
Deployed Models Are Monitored for Performance and Re-training Risks are Managed
FDA and other government bodies have realized that artificial intelligence technologies will drive innovations in the healthcare industry and revolutionize the way patients are treated in the coming years. Hence they decided to lay down the guidelines mentioned above as a precautionary measure to ensure the safety and security of individuals.
At the conference on Empirical Methods in Natural Language Processing (EMNLP) 2021, Hugging Face’s “Datasets: A Community Library for Natural Language Processing” paper was awarded for the best demonstration paper. It is their second award in a row from EMNLP, where the paper on “Transformers: State of the Art Natural Language Processing” got the best demonstration paper award last year at EMNLP 2020.
EMNLP 2021 aims at five categories of awards such as best long paper, best short paper, main conference papers, outstanding papers, as well as the best demo paper, where Hugging Face grabs the award for best demo paper.
The award-winning paper comprises the Hugging Face’s dataset projects that have more than 300 contributors. It is termed as a community project that allows researchers to access hundreds of datasets with ease. It has provided the new use cases of cross-dataset NLP and advanced the existing features for tasks like indexing and streaming large datasets.
The project has lightweight libraries that provide two significant features, such as one-line data loaders for many public datasets and efficient data pre-processing techniques.
In addition, it provides access to +15 evaluation metrics and is specially designed to let users quickly add and share new datasets and metrics. Further attributes include smart caching, built-in interoperability, etc. Datasets originated from a fork of the TensorFlow dataset and developed further.
For more information about the paper on “Datasets: A Community Library for Natural Language Processing,” you can read the official documentation from Hugging Face in the link.
Artificial Intelligence expert, Stuart Russel from the University of California, says that the rapid development of AI technologies is spooking its creators. He said this regarding the fact that developers and researchers are getting surprised by their own success in bringing new artificial intelligence-powered innovations.
Russel firmly believes that artificial intelligence technologies will outperform human intelligence by the end of the 21st century. He mentioned that it has become critical for countries to sign international agreements to have control over the growth of artificial intelligence technologies for human benefit.
“The AI community has not yet adjusted to the fact that we are now starting to have a really big impact in the real world. That simply wasn’t the case for most of the history of the field – we were just in the lab, developing things, trying to get stuff to work, mostly failing to get stuff to work,” said Russell.
He further added that humans need to quickly catch up with the rapid pace of technological advancement. Founder of the Center for Human-Compatible Artificial Intelligence at the University of California, Berkeley, said that scientists and researchers are yet not careful enough to use methodologies for developing artificial intelligence in real-world environments.
It is critical to take immediate measures to ensure humans remain in control when superintelligent artificial intelligence gets developed. For instance, social media algorithms have massive control over what and how users spend their time online reading.
“I think numbers range from 10 years for the most optimistic to a few hundred years. But almost all AI researchers would say it’s going to happen in this century,” said Russell when asked about AI’s depiction in movies.
Stuart Russe will also be giving 2021’s BBC Reith lectures, named ‘Living with Artificial Intelligence.’