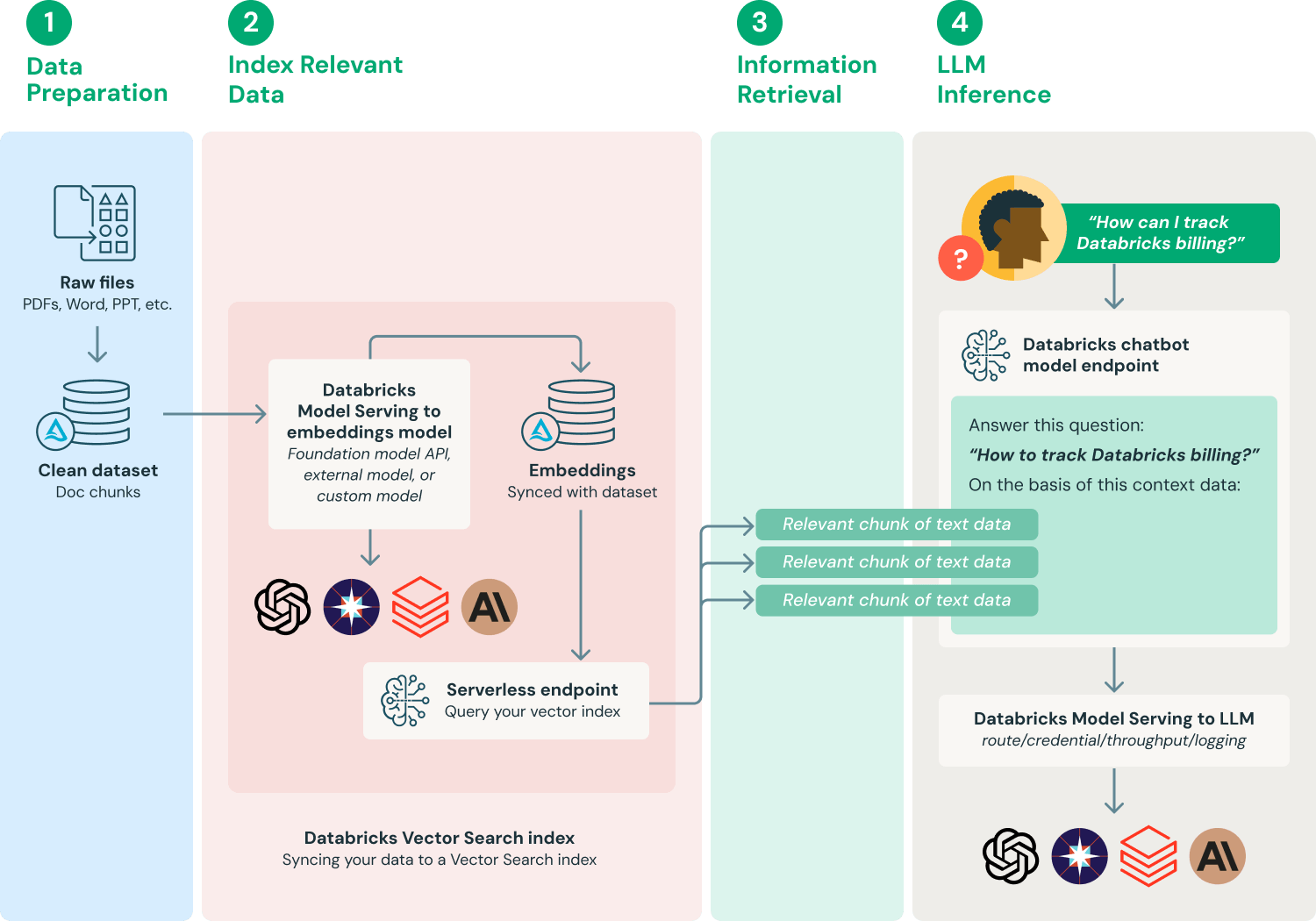
Language models have been revolutionizing human-computer interactions since the early 1980s. With improvements occurring every year, these models are now capable of complex reasoning tasks, summarizing challenging research papers, and translating languages.
Among these models, large language models are the prominent ones that can conduct the most sophisticated operations. This is the key reason for their popularity among various tech enthusiasts and industry professionals.
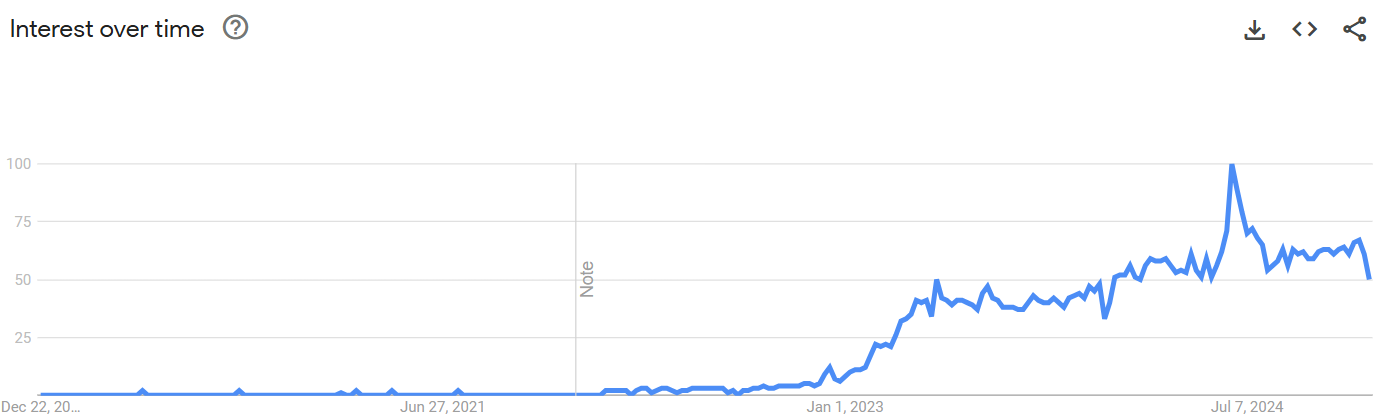
According to the above Google Trends graph, interest in the term “Large Language Models” has significantly increased in the past five years.
However, creating a custom large language model still remains a difficult task for most users. If the question “How to build a large language model on your own?” lingers in your mind, you have come to the right place!
This article comprehensively discusses the concept of large language models and highlights various methods for building one from scratch.
What Is a Large Language Model?

A Large Language Model, or LLM, is a complex computer program developed to understand and generate human-like text by analyzing patterns in vast datasets. You must train an LLM using deep learning algorithms and large datasets to analyze the behavior of data. This includes learning sentence structures, semantics, and contextual relationships. Once trained, the model predicts the probability of words in a sequence and generates results based on the prompts you provide.
Using the patterns identified in the training data, an LLM computes the probability of each potential response.
For example, the probability of the occurrence of “Humpty Dumpty sat on a wall” is greater than “Humpty Dumpty wall on a sat.” This is how the model correctly predicts the best-fitting translation of a sentence.
What Are the Characteristics of Large Language Models?
- Contextual Understanding: LLMs can understand the context of sentences. Rather than relying on words or phrases, these models consider entire sentences or paragraphs to generate the most relevant outcomes.
- Robust Adaptability: Fine-tuning LLMs makes them adaptable for specific tasks, including content summarization, text generation, and language translation for domains such as legal, medical, and educational.
- Sentiment Analysis: With LLMs, you can analyze the underlying sentiments involved in the text, identifying whether a statement conveys positive, negative, or neutral emotions. For example, you can analyze the product reviews left by your customers to determine specific business aspects that you can improve on.
What Are the Types of Large Language Models?
Currently, two types of LLMs are popular: the statistical language model and the neural language model.
Statistical language models rely on traditional data modeling techniques, such as N-grams and Markov chains, to learn the probability distribution of words. However, this model is constrained to short sequences, which makes it difficult to produce long contextual content due to their limited scope of memory.
Neural language models, on the other hand, use multiple parameters to predict the next word that best fits a given sequence. Libraries like Keras and frameworks such as TensorFlow provide tools to build and train neural models, creating meaningful associations between words.
What Are N-Gram Models?
N-gram is a statistical language model type that predicts the likelihood of a word based on a sequence of N words.
For example, expressing “Humpty Dumpty sat on a wall” as a Unigram or N=1 results in:
“Humpty”, “Dumpty”, “sat”, “on”, “a”, “wall”
On the other hand, utilizing Bigram of N=2, you get: “Humpty Dumpty”, “Dumpty sat”, “sat on”, “on a”, and “a wall”.
Similarly, an N-gram model would have a sequence of N words.
How Does an N-Gram Model Work?
The N-gram model relies on conditional probability to predict the next word in a sequence. Through this model, you can determine the possibility of the appearance of the word “w” based on its preceding context, “h,” using the formula p(w|h). This formula represents the probability of w appearing given the historical sequence h.
Implementing the N-gram model requires you to:
- Apply the chain rule of probability.
- Employ a simplifying assumption to use historical data.
The chain rule allows you to compute the joint probability of a sequence by leveraging conditional probabilities of the previous words.
p(w1, w2, …, wn) = p(w1).p(w2|w1).p(w3|w1,w2)…p(wn|w1,…, wn-1)
Due to the impracticality of calculating probabilities for all possible historical sequences, the model relies on the Markov assumption, simplifying the process.
p(wk|w1,…, wk-1) = p(wk|wk-1)
This implies that the probability of wk depends only on the preceding word wk-1 rather than the entire sequence.
Building an N-Gram Model
Let’s apply the theory by building a basic N-gram language model that uses the Reuters corpus from the Natural Language Toolkit (NLTK).
To get started, open the terminal and install the Python nltk library using the following command:
pip install nltkFollow these steps to build a large language model from scratch with the N-gram principle:
- In your code editor, install all the necessary libraries, such as Jupyter Notebook, and download the required datasets.
from nltk.corpus import reuters
from nltk import trigrams
from collections import defaultdict
import nltk
nltk.download('reuters')
nltk.download('punkt')- Create a placeholder for the model utilizing the defaultdict subclass. This will store the counts for each trigram.
model = defaultdict(lambda: defaultdict(lambda: 0))- Now, you can iterate over all the sentences in the Reuters corpus, convert the sentences into trigrams, and count the number of occurrences of each trigram.
for sentence in reuters.sents():
for w1, w2, w3 in trigrams(sentence, pad_right=True, pad_left=True):
model[(w1, w2)][w3] += 1- The trigram count is beneficial in generating the probability distribution of the most relevant next word.
for w1_w2 in model:
total_count = float(sum(model[w1_w2].values()))
for w3 in model[w1_w2]:
model[w1_w2][w3] /= total_count- To test the results of this model, you can print the likelihood of occurrence of a word next to given two words:
print(dict(model['the', 'cost']))Output:
{‘of’: 0.816, ‘will’: 0.011, ‘for’: 0.011, ‘-‘: 0.011, ‘savings’: 0.057, ‘effect’: 0.011, ‘.’: 0.011, ‘would’: 0.023, ‘escalation’: 0.011, ‘.”‘: 0.011, ‘down’: 0.011, ‘estimate’: 0.011}
From the above output, the word ‘of’ has the highest probability of appearing after the phrase ‘the cost,’ which makes sense.
In this way, you can create your N-gram model. Although this model is efficient in producing sentences, it has certain limitations.
Limitations of the N-Gram Model
- Higher values of N enhance the model’s prediction accuracy. However, it also requires more memory and processing power, leading to computational overhead.
- If the word is unavailable in the training corpus, the probability of the word appearing will be zero, which restricts the generation of new words.
What Are Neural Language Models?
Neural language models are a type of LLM that utilizes neural network architecture to generate responses based on previous data. These models capture semantic relationships between words to produce contextually relevant outputs.
How Does a Neural Language Model Work?
When working with huge data volumes, you can use Recurrent Neural Networks (RNNs). It is a type of machine learning algorithm that enables you to identify the patterns in the input data based on training data.
Composed of multiple layers with interconnected nodes, RNNs have memory elements to keep track of all the training information. However, for long sequences of text, the computational requirements of RNNs become expensive and result in performance degradation.
To overcome this challenge, you can use the Long Short-Term Memory (LSTM) algorithm. This variant of RNN introduces the concept of a “cell” mechanism that retains or discards information in the hidden layers. Each LSTM cell has three gates:
- Input Gate: Regulates new information flow into the cell.
- Forget Gate: Determines which information to discard from the memory.
- Output Gate: Decides which information to transmit as the system’s output.
Building a Neural Language Model
Let’s develop a neural language model using the Python Keras library. Before you begin, you must install the Keras library on your local machine.
pip install kerasThen, follow these steps to build a large language model with Keras:
- Import the essential libraries in your preferred code editor, such as Jupyter Notebook, to build the model.
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense, GRU, Embedding- Directly read the dataset as a string in a new Jupyter notebook.
data_text = 'Enter your data'- For data cleaning, you must preprocess the text to prepare it for model training. These steps can involve converting the text to lowercase, removing punctuation, and eliminating insignificant words.
- To efficiently model the dataset, consider splitting the data into smaller manageable sequences. For example, you can create a function to create a sequence of 25 characters using clean data obtained from the previous step.
def create_seq(text):
length = 25
sequences = list()
for i in range(length, len(text)):
seq = text[i-length:i+1]
sequences.append(seq)
print('Total Sequences: %d' % len(sequences))
return sequences
sequences = create_seq(clean_data)- Create a character mapping index and an encoding function that converts the textual data into numeric tokens on which the model can train. Execute the following code:
chars = sorted(list(set(clean_data)))
mapping = dict((c, i) for i, c in enumerate(chars))
def encode_seq(seq):
sequences = list()
for line in seq:
encoded_seq = [mapping[char] for char in line]
sequences.append(encoded_seq)
return sequences
sequences = encode_seq(sequences)Running the sequences variable will produce a two-dimensional array of numbers highlighting the encoded values of sequences.
- After preparing the data, you can now split it into training, testing, and validation sets. To accomplish this, you can either split the data directly utilizing Python indexing or perform the same with methods like train_test_split() from sklearn.model_selection module.
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(encoded_sequences, labels, test_size=0.2, random_state=42)- To build a large language model, you can define the model using the Sequential() API and outline its different layers. The embedding layer converts input into dense vectors, the GRU layer defines the RNN architecture, and the dense layer serves as an output interface. You can print the model summary describing its characteristics.
model = Sequential()
model.add(Embedding(vocab, 50, input_length=25, trainable=True))
model.add(GRU(150, recurrent_dropout=0.1, dropout=0.1))
model.add(Dense(vocab, activation='softmax'))
print(model.summary())- Compile the model by mentioning the loss function, metrics, and optimizer arguments. This aids in optimizing the model performance.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')- Fit the training data to the model by defining the total number of iterations, epochs, and the validation set arguments.
model.fit(X_tr, y_tr, epochs=100, verbose=2, validation_data=(X_val, y_val))- Finally, after training, you can use the test data to determine how well this model performs with unseen data. Evaluating the test results is crucial to developing models that generalize effectively across diverse datasets.
Unlike statistical models, neural language models are more efficient at generating new data due to their context-based understanding of the language. However, neural models require technical expertise and significant computational resources. To simplify development, you can leverage the pre-trained models to avoid building from scratch.
Build a Large Language Model Using Hugging Face
The introduction of Generative Adversarial Networks (GANs) and transformer architectures has revolutionized the field of artificial intelligence. GANs utilize two neural networks—a generator and a discriminator—to produce new content. On the other hand, transformers use a self-attention mechanism to process data.
When working with modern LLM architectures like transformers, Hugging Face is a prominent platform. It provides libraries with thousands of pre-trained models for building powerful applications. This reduces the complexity of creating an LLM from scratch.
Along with the model, the Hugging Face platform also offers access to multiple datasets. By integrating your organizational data with these datasets, you can enhance the context-specific relevance of your application.
Key Takeaways
You can build a large language model in Python using different techniques, including statistical, neural language, and pre-trained models. These methods allow you to develop robust LLM applications.
Choose the method for building an LLM based on your needs and the desired level of contextual understanding. However, before getting started with building an LLM, you must ensure that the data is clean to minimize errors and reduce the chances of incorrect or biased outputs.
FAQs
What are some examples of LLMs?
Some popular large language model examples include GPT-4 by OpenAI, BERT by Google AI, Llama by Meta AI, and Claude by Anthropic.
What is the difference between LLM and GPT?
LLM is a broad category of machine learning models trained on massive amounts of text data to understand and generate human-like text. Conversely, a Generative Pre-trained Transformer (GPT) is a specific type of large language model developed by OpenAI.
How do you build a large language model in AI with a prompt context length of 100 trillion words?
Building an LLM with an extended context length will require immense resources. These include data collection, ensuring sufficient computational resources and memory, selecting the appropriate architecture, picking training algorithms, and applying validation strategies.
What is the primary purpose of Large Language Models?
The primary purpose of LLMs is for applications like content creation, code generation, question answering, text classification, and summarization.
: Comprehensive Guide")






")