


Machine learning (ML) algorithms are programs that help you analyze large volumes of data to identify hidden patterns and make predictions. These algorithms are step-by-step instructions that enable your machines to learn from data and perform several downstream tasks without explicit programming.
As a data analyst, understanding and utilizing these algorithms can significantly enhance your ability to extract valuable insights from complex datasets.
Employing machine learning algorithms allows you to automate tasks, build predictive models, and discover trends you might overlook otherwise. These algorithms can enhance the reliability and accuracy of your analysis results for a competitive edge.
This article will provide a detailed rundown of the top ten machine learning algorithms list that every data analyst in 2024 should know.
Types of Machine Learning Algorithms
Based on the data type and the learning objectives, ML algorithms can be broadly classified into supervised, semi-supervised, unsupervised, and reinforcement learning. Let’s explore each category:
Supervised Machine Learning Algorithms
Supervised learning involves learning by example. The algorithms train on labeled data, where each data point is linked to a correct output value. These algorithms aim to identify the underlying patterns or relationships linking the inputs to their corresponding outcomes. After establishing the logic, they use it to make predictions on new data.
Classification, regression, and forecasting are the three key tasks linked with supervised machine learning algorithms.
- Classification: It helps categorize data into predefined classes or labels. For example, classifying e-mails as “spam” or “not spam” or diagnosing diseases as “positive” or “negative.” Common algorithms for classification include decision trees, support vector machines, and logistic regression.
- Regression: Regression is used when you want to establish relationships between dependent and independent variables. For example, it can be used to evaluate housing prices based on location or temperature based on previous weather data.
- Forecasting: You can use forecasting and predict future values based on historical data trends. It is majorly used in time-series data. Some examples include predicting future sales or demand for specific products.
Semi-Supervised Machine Learning Algorithms
Semi-supervised machine learning algorithms utilize both labeled and unlabeled data. The algorithm uses labeled data to learn patterns and understand how inputs are mapped to outputs. Then, it applies this knowledge to classify the unlabeled datasets.
Unsupervised Machine Learning Algorithms
An unsupervised algorithm works with data that don’t have labels or pre-defined outcomes. It works by exploring large datasets and interpreting them based on hidden data characteristics, patterns, relationships, or correlations. The process involves organizing large datasets into clusters for further analysis.
Unsupervised learning is generally used for clustering, association rule mining, and dimensionality reduction. Some real-world examples include fraud detection, natural language processing, and customer segmentation.
Reinforcement Machine Learning Algorithms
In reinforcement learning, the algorithm employs a trial-and-error method and learns to make decisions based on its interaction with the environment. It gets feedback as rewards or penalties for its actions. Over time, the algorithm leverages past experiences to identify and adapt the best course of action to maximize rewards.
Such algorithms are used to optimize trajectories in autonomous driving vehicles, simulate gaming environments, provide personalized healthcare plans, and more.
Top 10 Algorithms for Machine Learning in 2024
Even though machine learning is rapidly evolving, certain algorithms are consistently effective and relevant across various domains. Here is the top ten machine learning algorithms list that every data analyst in 2024 should know about:
1. Linear Regression
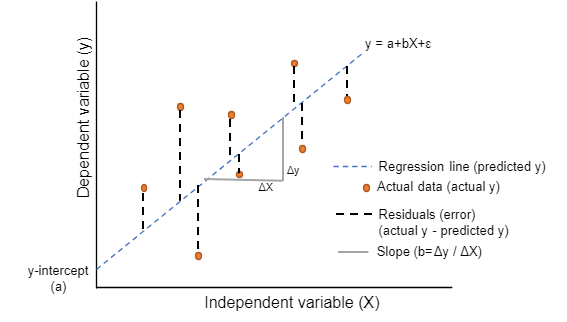
Linear regression, a supervised learning algorithm, is used for modeling relationships between a dependent and one or more independent variables. If one independent variable is involved, it is a simple linear regression; if there are multiple variables, it is called multiple linear regression.
The algorithm assumes the data points have a linear relationship and approximates them along a straight line, described by the equation y=mx+c.
Here:
‘y’ refers to the dependent variable.
‘x’ is the independent variable.
‘m’ is the slope of the line.
‘c’ is the y-intercept.
The objective is to find the best-fitting line that minimizes the distance between actual data points and predicted values on the line. Linear regression has applications in various fields, including economics, finance, marketing, and social sciences, to analyze relationships, make predictions, and understand trends.
2. Logistic Regression
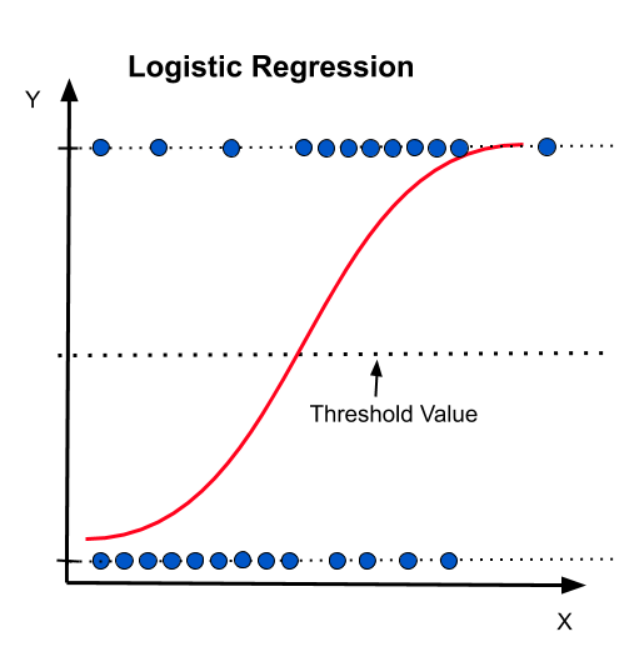
Logistic regression is a supervised classification algorithm. You can use it to predict binary outcomes (yes/no or 0/1) by calculating probabilities. The algorithm uses a sigmoid function that maps the results into an “S-shaped” curve between 0 and 1.
By setting a threshold value, you can easily categorize data points into classes. Logistic regression is commonly used in spam email detection, image recognition, and health care for disease diagnosis.
3. Naive Bayes
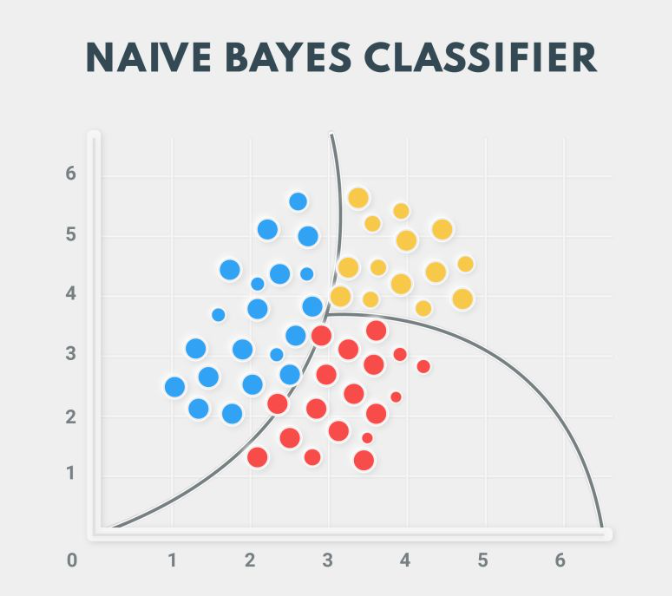
Naive Bayes is a supervised classification machine learning algorithm. It is based on Bayes’ Theorem and the ‘naive’ assumption that features in an input dataset are independent of each other. The algorithm calculates two probabilities: the probability of each class and the conditional probability of each class given an input. Once calculated, it can be used to make predictions.
There are several variations of this algorithm based on the type of data: Gaussian for continuous data, Multinomial for frequency-based features, and Bernoulli for binary features. Naive Bayes is mainly effective for applications such as sentiment analysis, customer rating classification, and document categorization due to its efficiency and relatively high accuracy.
4. k-Means
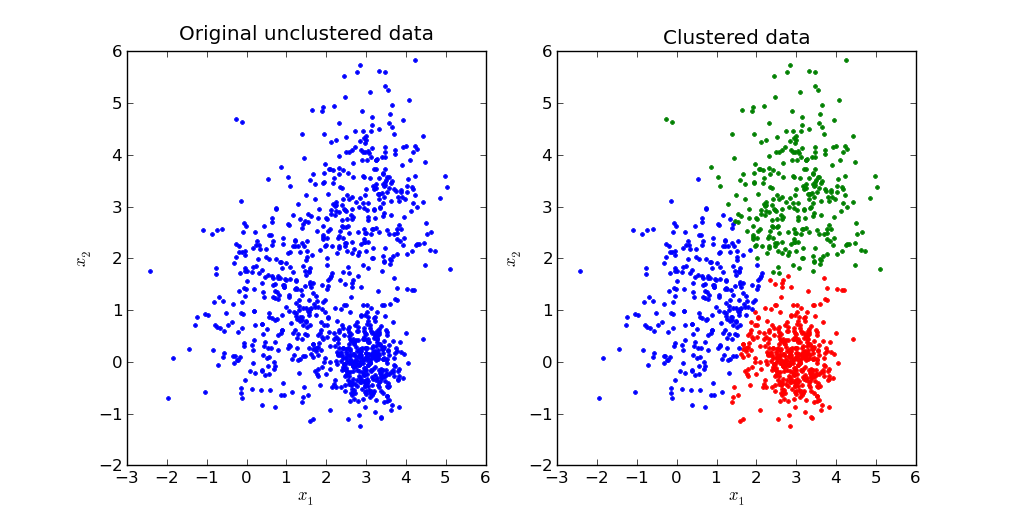
K-means is an unsupervised learning algorithm that groups data into ‘k’ clusters such that the variances between data points and the cluster’s centroid are minimal. The algorithm begins by assigning data to separate clusters based on Euclidean distance and calculating their centroids.
Then, if a cluster loses or gains a data point, the k-means model recalculates the centroid. This continues until the centroids stabilize. You can utilize this clustering algorithm across various use cases, such as image compression, genomic data analysis, and anomaly detection.
5. Support Vector Machine Algorithm
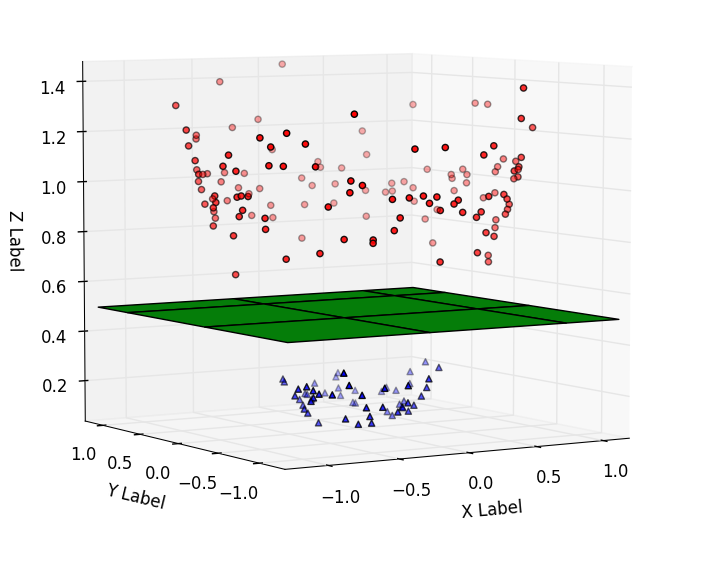
SVM is a supervised learning algorithm that you can use for both regression and classification tasks. It lets you plot a graph where all your data is represented as points in n-dimensional space (‘n’ is the number of features). Then, several lines (2D) or planes (higher dimensions) that split the data into different classes are found.
The decision boundary, or the hyperplane, is selected such that it maximizes the margin between the nearest data points of different classes. Common kernel functions such as linear, polynomial, and Radial Basis Functions (RBF) can be employed to enable SVM to handle complex relationships within data effectively.
Some real-world applications of the SVM algorithm include hypertext classification, stenographic detection in images, and protein fold and remote homology detection.
6. Decision Trees
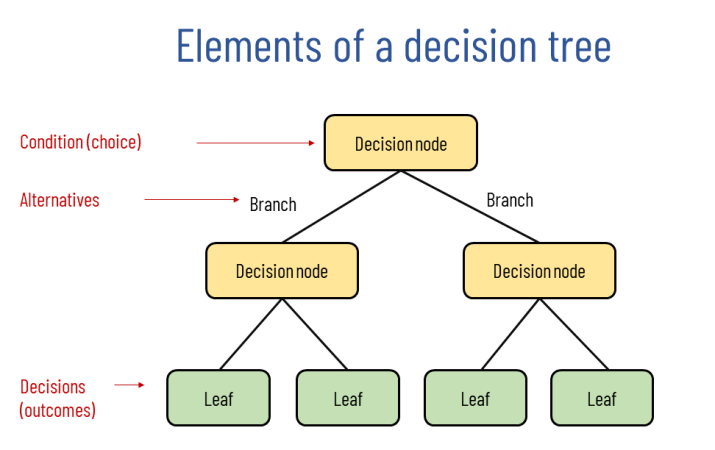
Decision trees are a popular supervised machine learning method used for classification and regression. It recursively splits the dataset based on attribute values that maximize information gain and minimize the Gini index (a measure of impurity).
The algorithm uses the same concept to choose the root node. It starts by comparing the root node’s attribute to the real dataset’s attribute and follows the branch to jump to the next node. This forms a tree structure where internal nodes are decision nodes and leaf nodes are final outputs at which you cannot segregate the tree further.
Decision trees effectively handle both categorical and continuous data. Some variants of this algorithm include Iterative Dichotomiser 3 (ID3), CART, CHAID, decision stumps, and more. They are used in medical screening, predicting customer behavior, and assessing product quality.
7. Artificial Neural Networks (ANNs)
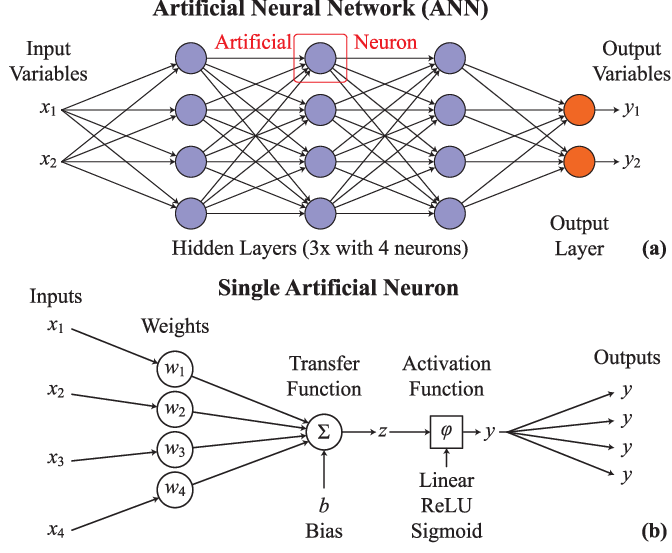
Artificial neural networks are computational algorithms that work with non-linear and high-dimensional data. These networks have layers of interconnected artificial neurons, including input, hidden, and output layers.
Each neuron processes incoming data using weights and activation functions, deciding whether to pass a signal to the next layer. The learning process involves adjusting the weights through a process called backpropagation. It helps minimize the error between predicted and actual values by tweaking connections based on feedback.
Artificial neural networks support many applications, including research on autism spectrum disorder, satellite image analysis, chemical compound identification, and electrical energy demand forecasting.
8. Dimensionality Reduction Algorithms
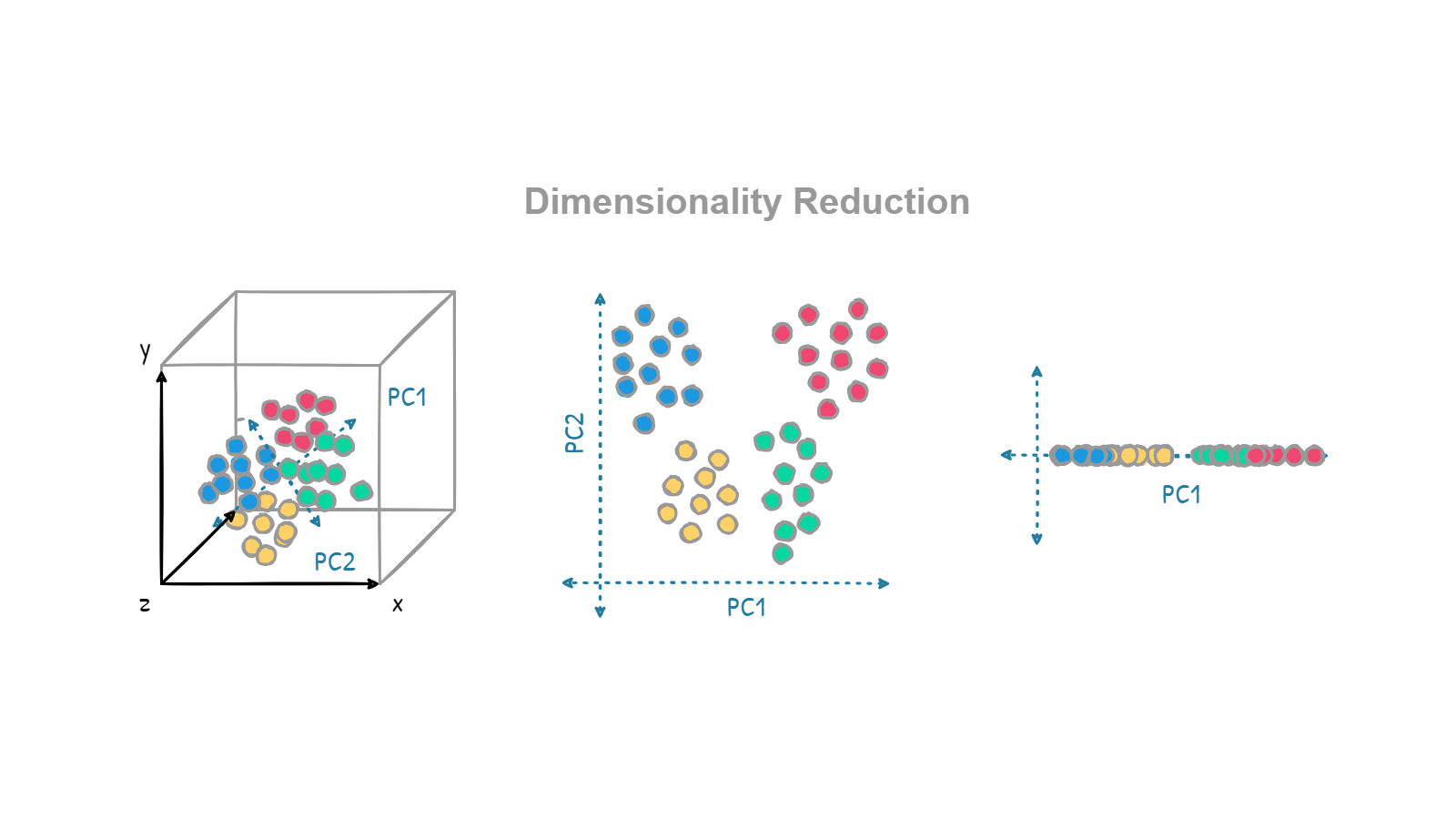
Data with a large number of features is considered high-dimensional data. Reducing the dimensionality refers to reducing the number of features while preserving essential information.
Dimensionality reduction algorithms help you transform high-dimensional data into lower-dimensional data using techniques like linear discriminant analysis (LDA), projection, feature selection, and kernel PCA. These algorithms are valuable for video compression, enhancing GPS data visualization, and noise reduction in datasets.
9. kNN Algorithm
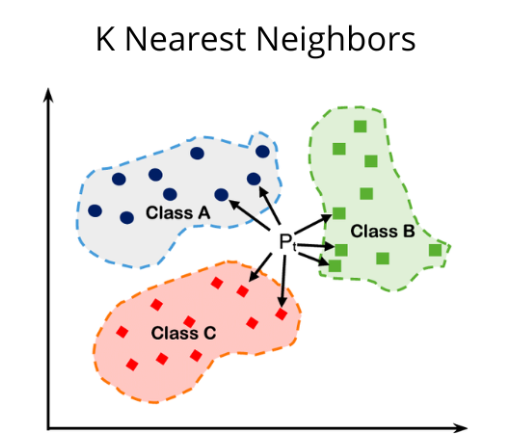
kNN stands for k nearest neighbor. This algorithm operates on proximity or similarity. To make predictions using KNN, you should first specify the number (k) of neighbors. The algorithm then uses distance functions to identify the k nearest data points (neighbors) to a new query point from the training set.
Eucledian, Hamming, Manhattan, and Minkowski distance functions are commonly used in the kNN algorithm. While Hamming is used for categorical data, the other three are used for continuous data. The predicted class or value for the new point depends either on the majority class or the average value of ‘k’ nearest neighbors.
Some applications of this algorithm include pattern recognition, text mining, facial recognition, and recommendation systems.
10. Gradient Boosting Algorithms
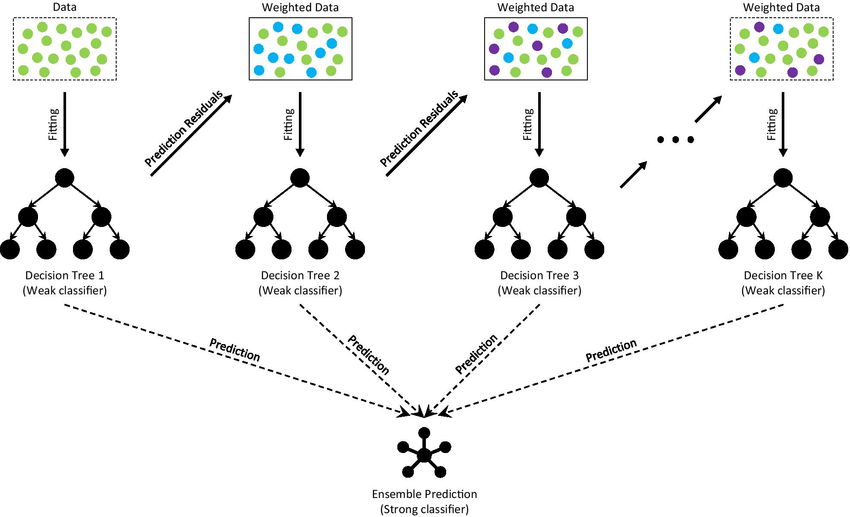
Gradient boosting machine learning algorithms employ an ensemble method that combines multiple weak models, typically decision trees, to create a strong predictive model. It works by optimizing a loss function, such as log loss for classification or mean squared error for regression.
Many data analysts prefer this algorithm as it can be tuned using hyperparameters such as number of trees, learning rate, and maximum tree depth. It has many variants, including XGBoost, LightGBM, and AdaBoost, which can help you improve the system’s training speed and performance.
You can use gradient boosting for image/object recognition, predictions in finance, marketing, and healthcare industries, and natural language processing.
Final Thoughts
With the top ten algorithms for machine learning, you can extract valuable insights from complex datasets, automate data operations, and make informed decisions. These algorithms provide a strong foundation for building accurate and reliable data models that can drive innovation.
However, when selecting an algorithm, you should consider the specific nature of your data and the problem at hand. Experimenting with different types of machine learning algorithms and fine-tuning their parameters will help you achieve optimal results. Staying up-to-date with the recent advancements in machine learning and artificial intelligence enables you to make the most of your data and maintain a competitive edge in the field.
FAQs
How is linear regression different from logistic regression?
With linear regression, you can predict continuous numerical values and model the relationship between variables. On the other hand, logistic regression allows you to predict probabilities for binary outcomes using a logistic function.
How to avoid overfitting in ANNs?
To avoid overfitting in ANNs, you can employ techniques like:
- Dropout layers to randomly deactivate neurons during training.
- Early stopping to halt training when the performance deteriorates on a validation set.
- Regularization to reduce overfitting by discouraging larger weights in an AI model.
Is k-means sensitive to the initial cluster centroids?
Yes, the k-means algorithm is sensitive to the initial cluster centroids. Poor initialization can lead to the algorithm getting stuck at the local optimum and provide inaccurate results.