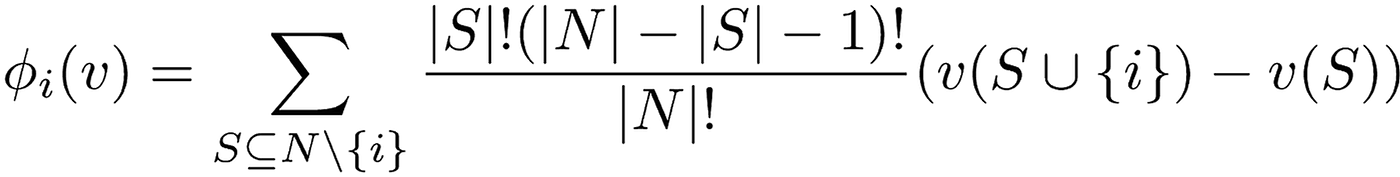On Tuesday, January 21, 2025, OpenAI CEO Sam Altman, SoftBank chief Masayoshi Son, and Oracle co-founder Larry Ellison issued a joint statement outlining a new project. The joint venture, also known as the Stargate Project, aims to develop AI data centers across the US.
This initiative has multiple tech partners joining in, including Microsoft, Arm, and Nvidia. Previous investors of OpenAI, Middle East AI Fund MGX, and SoftBank are collaborating to create investment strategies for effectively executing the Stargate Project.
The project is initially supposed to start in Texas and then expand to other states. The partner companies have agreed to invest $500 billion over the next five years.
In the press conference conducted at the White House, US President Donald Trump spoke about the investment plans to expand infrastructure. All the tech giants were invited to attend this conference.
The data centers could store AI-enabled chips developed by OpenAI, which is said to be building a team of chip designers and electronics engineers. To achieve this, OpenAI is continuously working with semiconductor companies like TSMC and Broadcom. The designed chips are expected to enter the market by 2026.
Earlier in December 2024, SoftBank pledged to invest $100 billion in the US over the next few years. SoftBank’s consistent interest in investing in companies like OpenAI and other startups and projects has fostered a close relationship with the current government.
Previously, OpenAI has negotiated with Oracle to lease a data center in Abilene, Texas. This data center is anticipated to reach a gigawatt of electricity by mid-2026. Estimated to cost around $3.4 billion, the Abilene data center would be the first Stargate site. The project would then scale up to 20 data centers by 2029.
According to Larry Ellison, “Each building is half a million square feet,” and “there are 10 buildings currently being built.”
AI, or artificial intelligence, is rapidly becoming an integral part of everyday life. From personal assistants like Siri to advanced algorithms that recommend movies or music on platforms like Netflix and Spotify, AI significantly impacts your daily interactions with technology.
However, the widespread adoption of AI has also raised potential concerns like privacy, bias, and accountability. To address these challenges, it is essential to confirm that AI systems are designed and implemented ethically. This is where AI ethics become important, guiding the responsible use of AI solutions.
In this blog, you’ll explore the significance of AI ethics and the steps involved in developing ethical AI systems.
What Is AI Ethics?
AI ethics refers to the principles that govern the use of artificial intelligence technologies. The primary focus is ensuring that AI systems reflect societal values and prioritize the well-being of individuals. By addressing ethical concerns, AI ethics promotes privacy, fairness, and accountability in AI applications.
Several prominent international organizations have established AI ethics frameworks. For instance, UNESCO released the Recommendation on the Ethics of Artificial Intelligence. This global standard highlights key principles like transparency, fairness, and the need for human oversight of AI systems. Similarly, the OECD AI Principles encourage the use of AI that is innovative and trustworthy while upholding human rights and democratic values.
Why Does AI Ethics Matter?
Ethical AI not only helps mitigate risks but also offers key benefits that can enhance your organization’s reputation and operational efficiency.
Increased Customer Loyalty
Ethical AI promotes trust by ensuring fairness and transparency in AI solutions. When users feel confident that your AI solutions are designed with their best interests in mind, they are likely more inclined to remain loyal to your brand. This fosters a positive experience that contributes to long-lasting customer relationships.
Encourages Inclusive Innovation
Incorporating varied perspectives, such as gender, culture, and demographics, in AI development helps you create solutions that address the varying needs of a broader audience. This inclusivity can lead to innovative solutions that resonate with diverse user groups.
Mitigates Legal and Financial Risks
Adhering to artificial intelligence regulations can help your organization avoid potential legal complications. Many regions have established data protection regulations like the California Consumer Privacy Act (CCPA) and the EU’s General Data Protection Regulation (GDPR). By complying with such data protection laws, you can ensure the ethical handling of data, reducing the risk of legal challenges and costly fines.
Facilitates Better Decision-Making
Ethical AI supports data-driven decision-making while ensuring that these insights are derived from fair and unbiased algorithms. This leads to more reliable and informed decisions, promoting trust and efficiency within your organization.
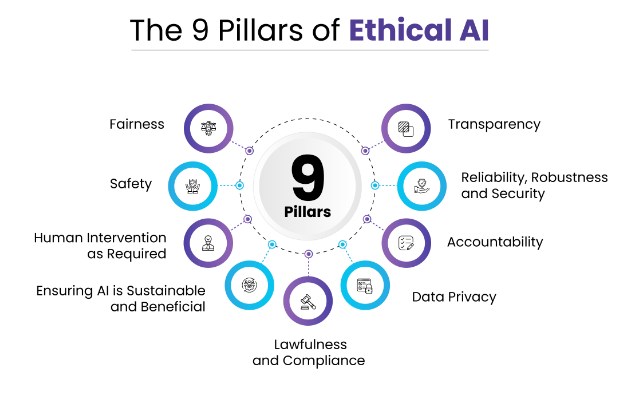
Key Pillars of AI Ethics
From fairness and safety to transparency and accountability, let’s look into the key pillars that AI ethics stand on.
Fairness
Fairness in AI ensures that the technology does not perpetuate bias or discrimination against individuals or groups. It is vital to design AI systems that treat all users equitably, regardless of factors like race, gender, or socio-economic status. To attain fairness, you must actively seek to identify and mitigate any biases that may arise in the data or algorithms.
Safety
Safety focuses on building AI systems that operate without harming individuals or the environment. It ensures AI behaves as intended, even in unpredictable scenarios. To maintain safety, you should rigorously test applications under diverse conditions and implement fail-safes for unexpected situations.
Human Intervention as Required
This emphasizes the importance of maintaining human oversight in AI operations, especially in critical decision-making processes. While AI can automate and augment many tasks, it is vital that you retain the ability to intervene when necessary. In cases where ethical, legal, or safety issues arise, human judgment should override AI decisions.
Ensuring AI Is Sustainable and Beneficial
You should develop AI solutions that promote long-term sustainability and offer benefits to society as a whole. It is important to consider the environmental impact of AI systems and ensure that applications contribute positively to social, economic, and environmental goals.
Lawfulness and Compliance
AI systems must operate within the bounds of legal and regulatory frameworks. Compliance with data protection regulations and industry-specific standards ensures lawful and ethical AI operations. Staying updated with evolving regulations helps ensure that AI systems respect human rights, privacy, and ethical standards, preventing misuse.
Transparency
Transparency is crucial to building trust in AI systems. You must enhance transparency by making your AI systems understandable to users. Provide clear documentation detailing how algorithms work, including the data sources used and the decision-making processes. This also facilitates accountability, enabling mistakes or biases to be traced and addressed more easily.
Reliability, Robustness, and Security
AI models must be reliable and robust so that they can function consistently and accurately over time, even in unpredictable environments. You should design AI systems with strong safeguard mechanisms to prevent tampering, data breaches, or failures, especially in critical applications like finance, healthcare, and national security.
Accountability
Accountability in AI ensures that systems are designed, deployed, and monitored with clear responsibility for their actions and outcomes. If an AI model causes harm or unintended consequences, there should be a process to trace the root cause. To achieve this accountability, you must have governance frameworks, thorough documentation, and regular monitoring.
Data Privacy
Data privacy is fundamental in AI development. AI systems often rely on large datasets, which may include sensitive personal information. This makes it critical to safeguard individual privacy by securely handling, processing, and storing data in compliance with privacy laws, such as GDPR. You should implement encryption, anonymization, and other robust security measures that prevent unauthorized access or misuse.
7 Key Steps to Develop Ethical AI Systems
Implementing ethical AI systems requires a systematic approach. Here are the seven essential steps to ensure ethical AI development and deployment:
1. Establish an Ethical AI Framework
The first step in implementing ethical AI is to create a structured framework. Begin by defining a set of ethical principles that align with your organization’s values. These should address core aspects such as transparency, fairness, accountability, and privacy. However, to ensure a broad perspective, you should involve various stakeholders, like customers, employees, and industry experts.
2. Prioritize Data Diversity and Fairness
AI models’ performance relies highly on the training data. A lack of diversity in the data can cause the model to generate biased results. To address this, you should use diverse datasets that accurately represent all user groups. This will enable the model to generalize across different scenarios and provide fair results.
3. Safeguard Data Privacy
AI often relies on large datasets, some of which may include personal information. As a safe measure, you can anonymize sensitive data and limit data collection to only what is strictly necessary. You must also employ techniques such as differential privacy and encryption to protect data. This safeguards user data from unauthorized access and ensures its use complies with privacy regulations like GDPR or CCPA.
4. Ensure Transparency and Explainability in AI Models
Make your AI system’s decision-making processes understandable to users. To achieve this, use explainable AI (XAI) techniques, such as LIME (Local Interpretable Model-Agnostic Explanations), which explains the prediction of classifiers by the ML algorithm. For example, if your AI system recommends financial loans, provide users with a clear explanation of why they were approved or denied.
5. Perform Ethical Risk Assessments
Assess potential ethical risks, such as bias, misuse, or harm, before deploying your AI systems. To conduct a thorough analysis, you can utilize frameworks like the AI Risk Management Framework developed by NIST. It offers a structured approach to managing the risks associated with AI systems. You can also leverage tools, such as IBM AI Fairness 360 or Microsoft Fairlearn, to detect and mitigate biases in your AI models.
6. Incorporate Ethical AI Governance
AI governance involves setting up structures and processes to oversee ethical AI development and deployment. You should establish an AI ethics committee or board within your organization to evaluate AI projects against ethical standards throughout their lifecycle. This helps you effectively address potential biases and ethical challenges.
7. Continuous Monitoring and Feedback Loops
After deployment, you need to collect user feedback and monitor the AI system for unexpected behaviors. Use performance metrics that align with your ethical principles, such as fairness scores or privacy compliance checks. For example, if your AI system starts showing biased outcomes in hiring decisions, you should have mechanisms in place to identify and correct this quickly.
Case Studies: Top Companies’ Initiatives and Approach to Ethical AI
Let’s explore the initiatives taken by leading organizations to ensure their AI technologies align with ethical principles and societal values.
Google’s AI Principles
Google was one of the first major companies to publish AI Principles, guiding its teams on the responsible development and use of AI. These principles ensure the ethical development of AI technologies, especially in terms of fairness, transparency, and accountability. Besides, Google explicitly states areas where they will not deploy AI, such as in technologies that could cause harm or violate human rights.
Microsoft’s AI Ethics
Microsoft’s approach to responsible AI is guided by six key principles—inclusiveness, reliability and safety, transparency, privacy and security, fairness, and accountability. It also established the AETHER (AI and Ethics in Engineering and Research) Committee to oversee the integration of these principles into the AI systems.
Wrapping Up
Ethical AI is essential to foster trust, fairness, and the responsible use of technology in society. The key pillars of AI ethics include fairness, safety, transparency, accountability, and data privacy, among others.
By adhering to principles of accountability and transparency of AI systems, you can avoid risks while enhancing your organization’s reputation. AI ethics also brings several benefits, including increased customer loyalty and facilitating better decision-making.
FAQs
How many AI ethics are there?
There are 11 clusters of principles identified from the review of 84 ethics guidelines. These include transparency, responsibility, privacy, trust, freedom and autonomy, sustainability, beneficence, dignity, justice and fairness, solidarity, and non-maleficence.
What are the ethical issues with AI?
Some of the ethical issues with AI include discrimination, bias, unjustified actions, informational privacy, opacity, autonomy, and automation bias, among others.
On January 22, 2025, Databricks announced that Meta had joined as a strategic investor in a $10 billion funding round. The company intends to use the money raised through fundraisers for expansion and product development.
Qatar Investment Authority, Temasek, and Macquarie Capital are other investors who have contributed to the Series J funding round. Databricks has also acquired a credit facility of $5.25 billion from JP Morgan Chase, Barclays, Citi, Goldman Sachs, and Morgan Stanley.
Founded in 2013, Databricks is a San Francisco-based data analytics and artificial intelligence company. It is already a part of Meta’s Llama, a collection of LLMs developed by Meta.
Ali Ghodsi, Databricks’s CEO and Co-founder, said, “Thousands of customers are using Llama on Databricks, and we have been working closely with Meta on how to best serve those enterprise customers with Llama. It naturally made sense for both parties to deepen that partnership through this investment.”
Last year, Databricks released its own open-source LLM called DBRX. It initially performed better than Meta’s Llama and some other models but was soon surpassed by them in efficiency. Ghodsi added that it is reasonable for them to ally with Meta, which has plenty of money to spend on model training. Databricks can utilize its money in other ways.
There has been a surge in investment in AI startups due to the increasing adoption of AI after the success of OpenAI’s ChatGPT.
On January 21, 2025, Aravind Srinivas, CEO of Perplexity AI and ex-OpenAI engineer, took over the social media platform X. In his post, Srinivas expressed that India could be the country that provides cost-effective solutions in the domain of artificial intelligence. He cited ISRO—Indian Space Research Organization—as an example, which has provided the world with affordable space exploration.
The following day, January 22, Srinivas announced a personal investment of $1 million and 5 hours per week to support individuals who aim to revolutionize AI in India.
He further emphasized, “Consider this as a commitment that cannot be backtracked. The dedicated team has to be cracked and obsessed like the DeepSeek team and has to open source the models with MIT license.”
In his post, Arvind Srinivas highlighted the remarkable achievement of DeepSeek, which released its model r1, outperforming OpenAI on LLM benchmarks. The r1 model offers 1 million token output at a staggering price of just $2.19. For the same output, OpenAI’s o1 model costs $60.
The existing Indian tech industry is utilizing pre-built open-source LLMs to develop applications. Disagreeing with this perspective, Aravind strives to foster fundamental LLM training in India. His vision aims to promote AI model training, which could further be released as open-source solutions.
Many professionals appreciate the tech giant’s enthusiastic view on AI model training. The post gained over a million views within two days. This shows that many individuals are intrigued by this initiative to push the boundaries of artificial intelligence in India.
‘Data on its own has zero value,’ said Bill Schmarzo on the Data Chief podcast. The numbers, stories, and insights behind the data give it meaning. But how can you explore data to unlock its true potential? You need the right tools and strategies to visualize, analyze, and interpret data in a way that reveals actionable insights.
AI-powered visualization tools help you transform complex data into visually appealing formats that are easy to interpret. Using charts, graphs, and interactive dashboards, you can identify hidden patterns, trends, and outliers more quickly.
This article lists the top AI tools for data visualization and how they revolutionize how you interpret information.
Automatic Chart Recommendations: The tool’s AI algorithm can analyze data and recommend the best charts or visualizations. This helps you better represent your data visually through charts, scatter plots, or heatmaps without needing deep technical knowledge.
AI-Driven Insights: One of the key features of AI-powered data visualization tools is their ability to provide insights that allow you to interact with data more intuitively. For example, if you want pointers from a chart or a report, you can ask the tools specific questions like ‘What factors contribute to an increase in sales?’. AI will interpret your query, analyze the data, and directly highlight relevant trends and insights in the visualization.
Identifying Key Influencing Factors: Some data tools incorporate AI features that help identify the key influencing factors within the datasets. These features enable users to recognize hidden patterns and detect anomalies.
Top AI Tools for Data Visualization
Below is the list of best AI tools for data visualization:
Qlik
Qlik is a modern data analytics and visualization platform. Its unique associative engine allows for intuitive data discovery and helps uncover insight that traditional query-based tools might miss. With AI and ML built into its foundation, Qlik provides automated recommendations to help you quickly explore vast amounts of data.
Features of Qlik
The Associative Analytical Engine in Qlik brings all the data together and maps relationships within your data, creating a compressed binary index. This helps to explore data more interactively.
AI splits feature is present within the decomposition tree, where you can use algorithms to identify and highlight key contributors to metrics.
Qlik Answers is an AI assistant that provides personalized answers to your questions.
The Insider Advisor Search feature helps you create visualizations and analyze data by asking questions in natural language. You can ask the question in the search box or select fields from the asset panel. This feature interprets the question and provides visualizations from the data model.
ThoughtSpot
ThoughtSpot is a cloud-based BI and data analytics application that helps you analyze, explore, and visualize data. Its AI-driven search and automated insights simplify data discovery and improve business decision-making.
Key Features of ThoughtSpot
ThoughtSpot offers an AI agent called Spotter, which answers your questions and provides business-ready insights. It allows you to interact with the tool in natural language, where you can ask questions and get AI-generated insights. You can also ask follow-up questions or jump-start a conversation from an existing analysis with Spotter and get relevant visualized responses.
The SpotIQ is an AI-powered analysis feature that allows you to surface hidden insights within your data in seconds, providing a full view of what’s happening in your business. Each insight is described in a plain language narrative, making it easy for you to understand the findings.
The Live Dashboards feature of ThoughtSpot enables you to create personalized and interactive dashboards from your cloud data. You can customize these dashboards to display the most relevant insights and interact with data by drilling down and filtering, exploring trends in real time.
Looker
Looker is an AI-powered BI solution offered by Google that is used for analytics and data visualization. It provides a flexible UI that allows you to create customized dashboards and reports, making data accessible and actionable for decision-making across teams.
Key Features of Looker
LookML is a modeling layer that enables advanced data transformation by translating raw data into a language both downstream users and LLMs can understand. It helps you establish a central hub for data context, definitions, and relationships, enhancing all your BI and AI workflows.
Looker offers real-time dashboards built on governed data that enable you to perform repetitive analysis.You can explore functions like expanding filters, drill down to understand data behind metrics, and ask questions.
Looker Studio is another looker’s self-service capability. It allows you to create interactive dashboards and ad hoc reports, provides access to 800 data sources and connectors, and has a flexible drag-and-drop canvas.
Gemini is an AI assistant that helps to accelerate the analytical workflow. It assists you in creating and configuring visualizations, formulas, data modeling, and reports.
Microsoft Power BI
Microsoft Power BI is a cloud-based self-service analytical tool for visualizing and analyzing data. It allows you to connect your data sources quickly, whether Excel spreadsheets, cloud-based documents, or on-premises data warehouses.
Key AI Features of Power BI
The AI Insight feature in Power BI allows you to explore and find anomalies and trends in your data within the reports. The insights are computed every time you open or interact with a report, such as by changing pages or cross-filtering your data.
You can use bright narrative summaries in your reports to address the key takeaways. This feature provides automated and human-readable insights directly within your reports. The summaries are generated based on the data, offering clear and easily understandable descriptions of trends, patterns, and key metrics. You can even customize these summaries’ language and format for specific audiences, adding further personalization to your reports.
Power BI integrates with Azure Cognitive Services, bringing advanced AI features such as text analytics, image recognition, and language understanding. These services help you improve data preparation by enabling better handling of unstructured data and enhancing the quality of your reports and dashboards.
Tableau
Tableau is an AI data visualization and analytics tool that you can use to analyze large datasets and create reports. With Tableau, you can organize and catalog data from multiple sources, including databases, spreadsheets, and cloud platforms. Its drag-and-drop functionality and real-time preview features make it intuitive and easy to use.
Tableau’s key feature:
Tableau Prep is a feature that uses AI to automate data cleaning and preparation tasks, allowing you to focus more on analysis. The AI algorithms help you detect data patterns and quickly transform raw data into usable format, making the preparation process more efficient.
Using the bins feature in Tableau, you can group data into discrete intervals, making it easy to understand and visualize data distribution more effectively. Using this feature, you can categorize numeric data into bins or buckets to better understand patterns such as frequency or trends across different ranges.
Data Stories is a tool for adding the Explain Data feature, which will enable you to create automated, plain-language explanations for your dashboards. The Explain Data feature allows you to inspect and locate key data points, diving deeper into visualization. It also provides AI-driven answers and explanations for the value of data points.
Sisense
Sisense is a BI and data analytics platform that assists your organization in gathering, analyzing, and visualizing data from various sources. It has a user-friendly interface where you can explore data and make reports. Sisense simplifies complex data and helps you transform it into analytical apps that you can share or embed anywhere.
Key Features of Sisense
With AI Trends in Sisense, you can add trend lines using statistical algorithms and compare trends with previous or parallel periods to identify patterns or anomalies.
Sisense offers data integration through Elastic Hub. This hub allows you to integrate data from multiple sources into ElasticCube or Live Models, which are abstract entities that organize your data.
Sisense Forecast is an advanced ML-powered function that you can apply through a simple menu option to any visualization based on time data, including area, line, or column. It allows you to see predictive movements in the future.
The Simply Ask feature in Sisense uses natural language processing to allow you to interact with data by asking questions in plain language. You can directly type your question in the Sisense interface, and the NLP engine within Sisense processes the query, providing automated suggestions and appropriate visualizations.
Conclusion
AI tools for data visualization help you interact with data more intuitively. The tools allow you to transform raw data into clear and actionable insights. These tools streamline decision-making and boost productivity by providing advanced features like predictive analytics, real-time insight, and natural language queries.
On January 21, 2025, Arthur Mensch, CEO and Co-founder of Mistral AI, a French AI company, announced during an interview with Bloomberg that they are working on an initial public offering (IPO). He was responding to a question about a potential IPO and said that the company is not for sale but is planning for an IPO.
Founded in 2023, Mistral AI is perceived as ‘France’s answer to Silicon Valley AI giants.’The founders, Arthur Mensch, Guillaume Lample, and Timothée Lacroix, are former employees of Meta and Google. They started Mistral AI with the intent to make GenAI more accessible and enjoyable for common users.
Despite being a newcomer, Mistral AI is already competing with major organizations like OpenAI’s GPT, Anthrpoic PBC’s Claude family, and Google’s Gemini. The major reason for this is that it releases all its models under open licenses for free usage and modifications. These models are trained on diverse datasets, including text, images, and codes, to facilitate better accuracy than those trained on a single data type. Mistral AI has released a GenAI chatbot called Le Chat and claims that it is faster than its competitors.
When asked about funding, Mensch said, “Startups are always raising money, but we have plenty.” Last Year, Mistral AI raised €600 million ($621 million) from investors such as General Catalyst, Andreessen Horowitz, and Lightspeed Venture Partners, reaching €5.8 billion valuation.
Mensch further added that Mistral AI is opening a new office in Singapore to target the Asia-Pacific market. The company also plans to expand its operations in Europe and the US.
An IPO could be a significant milestone for Mistral AI, allowing it to scale faster and positioning Europe as a prominent player in the AI landscape.
Huge volumes of data are generated every second by billions of devices, from smartphones and sensors to autonomous vehicles and industrial machines. As this data continues to grow, traditional cloud computing models are struggling to keep up with the demand for real-time processing and low-latency responses.
Edge computing addresses these limitations by processing data closer to its source, thereby reducing the distance it must travel and enabling real-time analytics. According to Gartner, by 2025, an astonishing 75% of enterprise data will be generated and processed at the edge, highlighting the growing importance of this technology.
In this article, you’ll understand the benefits of edge computing and discover how it operates through detailed use cases.
Understanding Edge Computing
Edge computing is a distributed computing framework that processes and stores data closer to the devices that generate it and the users that consume it. Traditionally, applications transmitted information from smart devices such as sensors and smartphones to a centralized data center for data analytics.
However, the complexity and volume of data have outpaced network capabilities. By shifting processing capabilities closer to the source or end-user, edge computing systems improve application performance and give faster real-time insights.
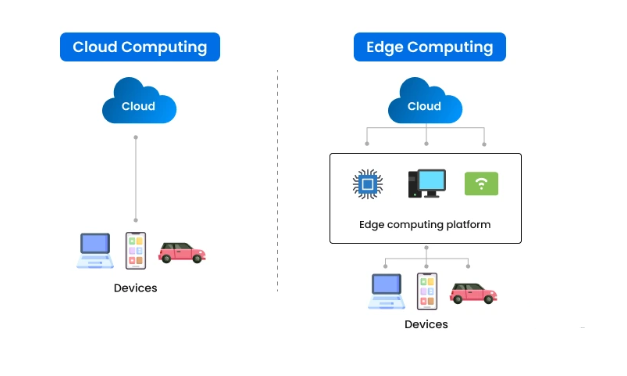
Edge Computing Vs Cloud Computing: Key Differences
Cloud and edge are two different computing models, each with its own characteristics, benefits, and use cases. While both serve the purpose of managing data, they do it in fundamentally different ways. Edge computing focuses on processing data closer to its source, which can improve real-time decision-making. In contrast, cloud computing centralizes data processing in remote data centers, offering scalability and extensive storage capabilities.
Here’s a breakdown of the key differences between edge computing vs cloud computing in a tabular format:
Aspect
Edge Computing
Cloud Computing
Data Processing
Processes data closer to the source of generation. (e.g., IoT devices).
Data processing occurs at a central location, such as a data center.
Latency
Minimal latency due to proximity to data sources.
Higher latency due to distance from data centers.
Bandwidth
Reduces bandwidth usage by processing data locally.
Can consume significant bandwidth for data transfer.
Scalability
More challenging to scale, as additional resources must be added locally.
Highly scalable; resources can be adjusted as needed.
Data Security
Enhanced security as data is processed locally, reducing exposure during transfer.
Security can be a concern due to data being transmitted over the internet.
Use Cases
Ideal for real-time analytics, IoT devices, and autonomous vehicles.
Suited for big data analytics, cloud storage, and streaming services.
Why is Edge Computing Important?
As the need for fast and efficient data processing increases, many companies are transitioning from traditional infrastructure to edge-computing setups. Let’s understand some of the key edge computing benefits in detail:
Enhanced Operational Efficiency
Edge computing helps you optimize your operations by rapidly processing huge volumes of data near the local sites where that data is generated. This is more efficient than sending all of the data to a centralized cloud, which might cause excessive network delays and performance issues.
Reduced Costs
By minimizing data transmission to cloud data centers, edge computing reduces the bandwidth requirements and storage costs. You can implement localized storage and computing solutions that offer cost-effective operations while minimizing latency and network dependency. This approach enhances operational efficiency by reducing delays in data processing and decision-making.
Enhanced Data Security
With data being processed locally on devices rather than transmitted over extensive networks to cloud servers, edge computing limits exposure to potential security threats. This is especially important for industries such as finance and healthcare, where data privacy is crucial.
Data Sovereignty
Your organization should comply with the data privacy regulations of the country or region where customer data is collected, processed, or stored. Transferring data to the cloud or to a primary data center across national borders can pose challenges for compliance with these regulations. However, with edge computing, you can ensure that you’re adhering to local data sovereignty guidelines by processing and storing data in proximity to its origin.
Improved Workplace Safety
In work environments where faulty equipment may lead to injuries, IoT sensors and edge computing can help keep people safe. For instance, on offshore oil rigs and other remote industrial settings, predictive maintenance and real-time data analyzed close to the equipment site can help enhance the safety of workers.
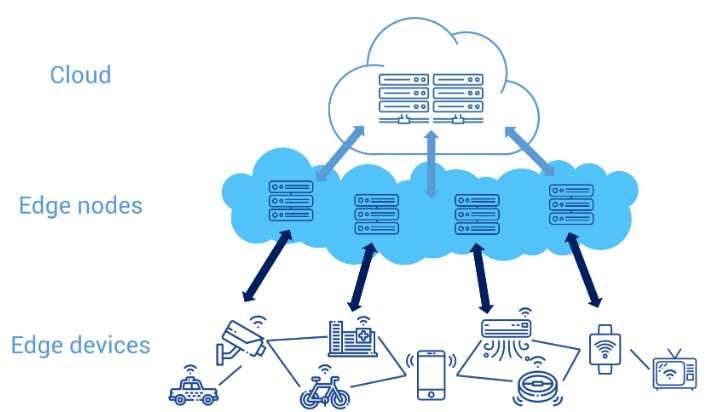
How Does Edge Computing Work?
Let’s understand how edge computing operates:
Data Generation: At the core of edge computing are devices like sensors, cameras, or other Internet of Things (IoT) devices. These devices gather data from their environment, such as temperature, motion, or video feeds.
Data Processing at the Edge: Instead of sending this raw data directly to a cloud server, it is processed closer to the source. This is typically done by a local device such as routers, gateways, or specialized edge servers. For instance, a camera might analyze a video stream locally to detect motion instead of sending the entire feed to the cloud.
Data Filtering and Transmission: After processing, relevant data is filtered and transmitted to the cloud or a central data center. Only the most critical or summarized data is sent, reducing the amount of information that needs to travel over the network.
Further Analysis: The processed data that is sent to the cloud can be further analyzed, stored, or used for long-term decision-making. However, the key decisions are made at the edge, ensuring faster response times.
Edge Computing Use Cases
Here are some edge computing use cases transforming operations across key sectors.
Remote Patient Monitoring
Wearable devices, such as smartwatches or medical sensors, collect vast amounts of data, including heart rate and glucose levels. Traditionally, all this data would be sent to the cloud for processing, but that can take time and can be a security risk. Edge computing allows these devices to analyze the data locally, right on the device itself.
For example, a wearable device monitoring a patient with a heart condition can instantly detect irregular heart rhythms and alert healthcare professionals or trigger an emergency response.
Autonomous Vehicles
Self-driving cars have sensors, cameras, and radar systems that collect data about their surroundings. This data needs to be processed in real-time to ensure safety and efficient navigation. By using edge computing, the vehicle can process this sensor data locally, avoiding the delays that would occur by sending it to a distant cloud server.
For instance, when a pedestrian suddenly steps onto the road, the vehicle’s edge processors can immediately analyze the situation and apply the brakes. This rapid decision-making is vital as even a slight delay could lead to accidents.
Smart Manufacturing
With edge computing, manufacturers can monitor their equipment and production lines in real time. Sensors embedded in machines collect data, and edge devices process this information to provide instant feedback.
For instance, if a machine begins to overheat, an edge computing device can automatically reduce its operating speed or shut it down to prevent damage. This timely intervention reduces the likelihood of equipment failures, minimizes downtime, and helps maintain consistent production quality.
Agriculture
In smart farming, edge computing enables farmers to make data-driven decisions by processing data from IoT sensors placed across the fields. These sensors collect data on soil moisture, weather, and crop health and analyze this data to provide insights.
For example, edge computing can automate irrigation by processing soil moisture and weather data. The system can instantly adjust water usage based on the current needs of the crops, optimizing growth conditions.
Best Practices for Edge Computing
Here are some of the best practices to consider for effectively implementing edge computing solutions:
Define Clear Objectives and Use Cases: Start by identifying the specific problems you want to solve with edge computing. A clear strategy will help guide your deployment and avoid unnecessary complexity.
Identify Suitable Edge Locations: Selecting optimal locations for edge nodes is crucial. These should be strategically placed near data sources, such as IoT devices or remote facilities, to ensure efficient data processing and minimize latency.
Implement Robust Security Measures: Security is paramount in edge computing environments due to the distributed nature of operations. Encryption, access control mechanisms, and compliance with data privacy laws can help secure data at the edge.
Leverage Edge Hardware and Resources: Choose edge hardware that matches your use cases. You may use specialized hardware, accelerators, and GPUs to ensure that edge devices effectively handle the computational loads.
Optimize Data Management: Minimize the amount of data sent to the central cloud by processing as much as possible at the edge. Techniques such as data aggregation, compression, and filtering can help manage bandwidth effectively while ensuring that only valuable insights are transmitted.
Implement Edge Intelligence: Develop applications that can perform intelligent processing locally to reduce the need for constant cloud communication. This enables real-time decision-making, which is particularly beneficial for applications that require immediate responses.
Ensure Redundancy and Reliability: Plan for redundancy and fault tolerance in your edge computing infrastructure. Edge nodes may experience connectivity or hardware failures, so make sure that your applications can handle such scenarios without major disruptions.
Emphasize Scalability and Flexibility: Design your edge computing architecture to scale based on changing requirements. Ensure that the system can manage an increasing number of edge devices and handle the growing volume of data generated.
Test Thoroughly and Iterate: Before full deployment, test your edge computing applications thoroughly. Pilot projects will help you evaluate performance and make adjustments based on real-world usage.
Final Thoughts
This article has explored the numerous benefits and practical use cases of edge computing. Processing data closer to the origin or source enhances performance, reduces latency, and improves security. These advantages make it an essential technology for various industries, from healthcare to manufacturing, where real-time data analysis is critical for decision-making and operational efficiency.
FAQs
What is the difference between edge computing and fog computing?
In edge computing, data processing happens directly at the source where it is created. On the other hand, fog computing acts as a mediator between the edge devices and the cloud. This intermediate layer provides additional processing and filtering of data before it is sent to the cloud, thus optimizing bandwidth and storage needs.
What are some popular edge computing platforms?
Popular edge computing platforms include Google Distributed Cloud Edge, Microsoft Azure IoT Edge, Amazon Web Services (AWS) IoT Greengrass, and IBM Edge Application Manager.
What are the metrics of edge computing performance?
You can evaluate edge computing performance through KPIs, such as network bandwidth utilization, latency, data processing speed, device uptime, and overall system reliability.
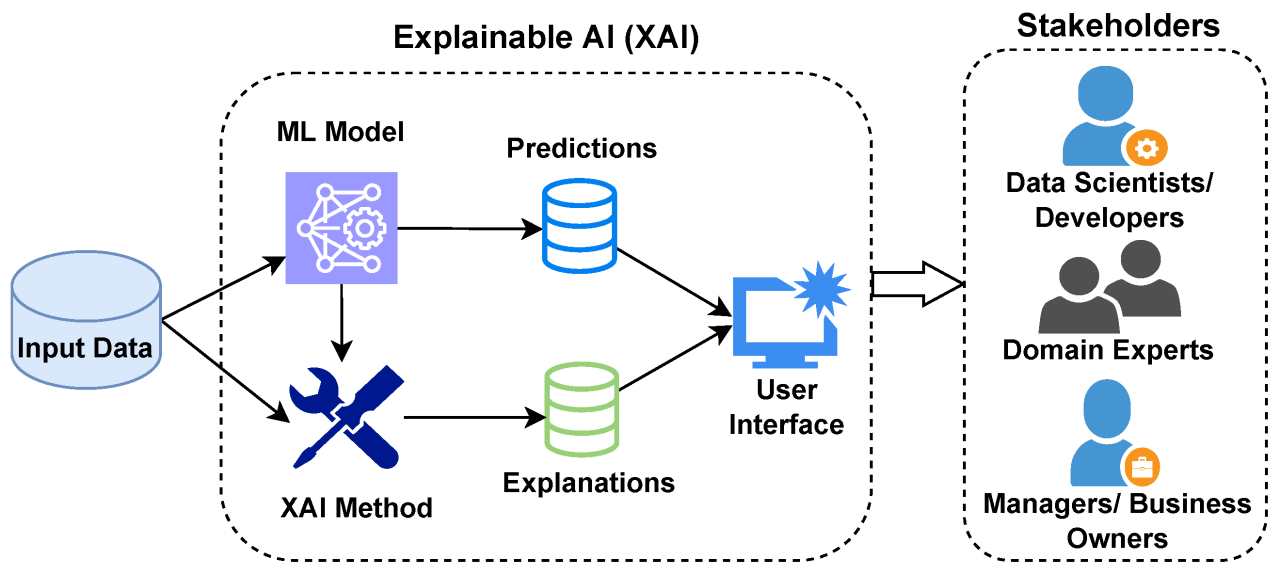
Businesses are increasingly relying on data and AI technologies for operations. This has made it essential to understand how AI tools make decisions. The models within AI applications function like black boxes that generate outputs based on inputs without revealing the intermediary processes. This lack of transparency can result in trust issues and impact accountability.
To overcome these drawbacks, you can use explainable AI techniques. These techniques help you understand how AI systems make decisions and perform specific tasks, helping foster trust and transparency.
Here, you will learn about explainable AI in detail, along with its techniques and challenges associated with implementing explainable AI within your organization.
Explainable AI (XAI) is a set of techniques that makes AI and machine learning algorithms more transparent. This enables you to understand how decisions and outputs are generated.
For example, IBM Watson for Oncology is an AI-powered solution for cancer detection and personalized treatment recommendations. It combines patient data with expert knowledge from Memorial Sloan Kettering Cancer Center to suggest tailored treatment plans. During its recommendations, Watson provides detailed information on drug warnings and toxicities. This offers transparency and evidence for its decisions.
There are several other explainable AI examples in areas such as finance, judiciary, e-commerce, and autonomous transportation. XAI methods also help you debug your AI models and align them with privacy and regulatory regulations. As a result, by using XAI techniques, you can ensure accountable AI usage in your organization.
Benefits of Explainable AI
Traditional AI models are like ‘black boxes,’ providing minimal insight into their decision-making processes. However, the adoption of explainable AI methods can eliminate this problem.
Here are some of the reasons that make explainable AI beneficial:
Improves Accountability
When you use explainable AI-based models, you can create detailed documentation for AI workflows, mentioning the reasons behind important outcomes. This makes employees involved in AI-related operations answerable for any discrepancies, fostering accountability.
Refines the Working of AI Systems
Using explainable AI solutions enables you to track all the steps within the AI-based workflow. This simplifies bug identification and quick resolution in case of system failures. Using these instances, you can continuously refine and enhance the efficiency of your AI models.
Promotes Ethical Usage
Explainable AI-based platforms facilitate the identification of biases in datasets that you use to train AI models. Following this, you can work to fine-tune and improve the quality of datasets for unbiased results. Such practices encourage ethical and responsible AI implementation.
Ensures Regulatory Compliance
Regulations such as the EU’s AI Act and GDPR mandate the adoption of explainable AI techniques. Such provisions help ensure the transparent use of AI and the protection of individuals’ privacy rights. You can also audit your AI systems, during which explainable AI can provide clear insights into how the AI model makes specific decisions.
Fostering Business Growth
Refining the outcomes of AI models using explainable AI helps you to increase your business’s growth. Through continuous fine-tuning of data models, you uncover hidden data insights, which help frame effective business strategies. For example, the explainable AI approach allows you to enhance customer analytics and use its outcomes to prepare personalized marketing campaigns.
Understanding the techniques of explainable AI is essential for interpreting and explaining how AI models work. These techniques are broadly categorized into two types: model-agnosticmethods and model-specific methods. Let’s discuss these methods in detail:
Model-Agnostic Methods
Model-agnostic methods are those that you can apply to any AI or machine-learning model without knowing its internal structure. These methods help explain model behavior by perturbing or altering input data and observing the changes in the model’s performance.
Here are two important model-agnostic XAI methods:
LIME
LIME, or Local Interpretable Model-Agnostics Explanations, is a method that provides explanations for the predictions of a single data point or instance instead of a complete model. It is suitable for providing localized explanations for complex AI models.
In the LIME method, you first need to create several artificial data points slightly different from the original data point for which you want an explanation. This is known as perturbation. You can use these perturbed data points to develop a surrogate model. It is a simpler, interoperable model designed to approximate the local behavior of the original model. You can compare the outcomes generated by the surrogate model with those of the original model to understand how a particular feature affects the model’s performance.
For example, to obtain an explanation for an image segmentation app, you can deploy the LIME method. In this process, you should first take an image, which will be divided into superpixels (clusters of pixels) to make the image interpretable. The creation of new datasets follows by perturbing these superpixels. The surrogate model can help analyze how each superpixel contributes to the segmentation process.
SHAP
The SHAP (Shapley Additive Explanations) method uses Shapley values for AI explainability. Shapley values are a concept of cooperative game theory that gives information about how different players contribute to achieving a final goal.
In explainable AI, SHAP implementation helps you understand how different features of AI models contribute to generating predictions. For this, you can calculate approximate Shapley values of each model feature by considering various possible feature combinations.
For each combination, you need to calculate the difference between the model’s performance when a specific feature is included or excluded from the combination. Use the formula below:
S: Number of combinations that can be formed for N number of features.
|S|: Number of features in combination S, excluding the feature for which the Shapley value is calculated.
This process is repeated for all combinations, and the average contribution of each feature across these combinations is its Shapley value.
For example, consider you have to use the SHAP method for a housing price prediction model. The model uses features such as plot area, number of bedrooms, age of the house, and proximity to school. Suppose that it predicts a price of ₹ 17,00,000 for some house.
First, obtain the average cost of the houses in the dataset on which the AI model is trained. Let’s assume it is Rs. 10,00,000. Then, calculate SHAP values for each feature, which are found to be as follows:
This explains how the plot area, number of bedrooms, and proximity to school features contributed to the model-predicted house price.
Model Specific Methods
You can use model-specific methods only on particular AI models to understand their functionality. Here are two model-specific explainable AI methods:
LRP
Layer-wise relevance propagation (LRP) is a model-specific method that helps you understand the decision-making process in neural networks (NN). The NN consists of artificial neurons that function similarly to biological neurons. These neurons are organized into three layers: input, hidden, and output. The input layer takes data, processes and categorizes it, and passes it on to the hidden layer.
There are several hidden layers in NN. A hidden layer takes data from the input layer or previously hidden layer, analyzes it, and passes the result to the next hidden layer. Lastly, the output layer processes the data and produces the final outcome. The neurons impact each other’s output, and the strength of the connection between different neurons is measured in terms of weights.
In the LRP method, you calculate the relevance value sequentially from the last neuron, starting from the output layer and working back to the input layer. These relevance values indicate the contribution of a particular feature. You can then create a heatmap of all the relevant values. In the heatmap, the areas with higher relevance values represent high contributing features.
For example, you want to obtain an explanation of an AI software-generated MRI report showing a tumor. When you use the LRP method, it involves:
Generation of a heatmap from the model’s relevance values.
The heatmap highlights areas with abnormal cell growth, showing high relevance values.
This provides an interpretable explanation for the model’s decision to diagnose a tumor, enabling comparison with the original medical image.
Grad-CAM
Gradient weighted class activation map (Grad-CAM) is a model-specific method for explaining convolution neural networks (CNN). A CNN consists of a convolution layer, a pooling layer, and a fully connected layer. The convolution layer is the first layer, followed by several pooling layers, and finally, the fully connected layer.
When you give an image input to a CNN model, it categorizes different objects within the image as classes. For example, if the image contains dogs and cats, CNN will categorize them into dog and cat classes.
In any CNN model, the last convolution layer consists of feature maps representing important image features. The Grad CAM method enables computing the gradient of the output classes with respect to the feature maps in the final convolutional layer.
You can then visualize the gradients for different features as a heatmap to understand how various features contribute to the model’s outcomes.
Challenges of Using Explainable AI
The insights obtained from explainable AI techniques are useful for developers as well as non-experts in understanding the functioning of AI applications. However, there are some challenges you may encounter while using explainable AI, including:
Complexity of AI Models
Advanced AI models, especially deep learning models, are complex. They rely on multilayered neural networks, where certain features are interconnected, making it difficult to understand their correlations. Despite the availability of methods such as Layer-wise Relevance Propagation (LRP), interpreting the decision-making process of such models continues to be a challenge.
User Expertise
Artificial intelligence and machine learning domains have a steep learning curve. To understand and effectively use explainable AI tools, you must invest considerable time and resources. If you plan to train your employees, you will have to allocate a dedicated budget to develop a curriculum and hire professionals. This can increase your expenses and impact other critical business tasks.
Biases
If the AI model is trained on biased datasets, there is a high possibility of biases being introduced in the explanations. Sometimes, explanatory methods also insert biases by overemphasizing certain features of a model over others. For instance, in the LIME method, the surrogate model may impart more importance to some features that do not play a significant role in the original model’s functioning. Due to a lack of expertise or inherent prejudices, some users may interpret explanations incorrectly, eroding trust in AI.
Rapid Advancements
AI technologies continue evolving due to the constant development of new models and applications. In contrast, there are limited explainable AI techniques, and they are sometimes insufficient to interpret a model’s performance. Researchers are trying to develop new methods, but the speed of AI development has surpassed their efforts. This has made it difficult to explain several advanced AI models correctly.
Conclusion
Explainable AI (XAI) is essential for developing transparent and accountable AI workflows. By providing insights into how AI models work, XAI enables you to refine these models and make them more effective for advanced operations.
XAI techniques can be model-agnostic methods like LIME and SHAP. The other type is model-specific methods, such as LRP and Grad-CAM.
Some of the benefits of XAI include improved accountability, ethical usage, regulatory compliance, refined AI systems, and business growth. However, the associated challenges of XAI result from the complexity of AI models, the need for user expertise, inherent biases, and rapid advancements.
With this information, you can implement robust AI systems in your organization that comply with all the necessary regulatory frameworks.
FAQs
How explainable AI is used in NLP?
Explainable AI has a crucial role in natural language processing (NLP) applications. It provides the reason behind using specific words or phrases in language translation or generation of any text. While performing sentiment analysis, NLP software can utilize XAI techniques to explain how specific words or phrases in a social media post contributed to a sentiment classification. You can also implement XAI methods in customer service to explain the decision-making process to customers through chatbots.
What is perturbation in AI models?
Perturbation is a technique of manipulating data points on which AI models are trained to evaluate their impact on model outputs. It is used in explainable AI methods such as LIME to analyze how specific features enhance or deteriorate a model’s performance.
AI has become more than just a buzzword—it’s a transformative technology that shapes how you interact with devices. From smart assistants answering our questions to complex algorithms helping doctors diagnose diseases, AI is everywhere, enhancing daily life.
But behind these advancements lies a complex yet fascinating process that allows machines to think and learn in unimaginable ways. Understanding how artificial intelligence works provide valuable insight into the future of technology.
What is Artificial Intelligence?
Artificial intelligence refers to the capability of systems to execute tasks that typically need human intelligence. These tasks include problem-solving, decision-making, learning, and understanding language. AI relies on advanced algorithms and large datasets to recognize patterns, make predictions, and improve over time without explicit programming for every scenario.
AI powers numerous applications, from virtual assistants to complex systems in several industries, including healthcare, finance, and robotics. From enhancing customer interactions to assisting you in complex data analysis, AI continually reshapes the way you approach challenges and innovate solutions.
Key Components of AI
AI comprises various technologies that enable machines to simulate human intelligence. Let’s explore them in detail:
Machine learning (ML)
ML is a subset of AI that empowers machines to learn from data without being programmed. It uses algorithms that find patterns in data to make predictions or decisions based on new input. Machine learning is classified into three types:
Supervised Learning: In this type, the algorithm learns from labeled data, using input-output pairs to make predictions.
Unsupervised Learning: Here, the algorithm recognizes patterns in data without labeled responses, which is useful for clustering and association tasks.
Reinforcement Learning: The algorithm learns by interacting with an environment and receiving feedback through rewards or penalties to optimize its actions.
Deep Learning
Deep learning, a subset of ML, uses neural networks with several layers to process data. These networks can automatically extract features from raw data, making them effective for complex tasks such as image and speech recognition. The architecture typically includes:
Input Layer: Receives the initial data.
Hidden Layers: Processes the received data from previous layers.
Output Layer: Generates the final prediction or classification.
Neural Networks
These are the essential building blocks of deep learning models. Inspired by the human brain, they are networks of interconnected nodes (neurons) stacked in layers. Each neuron processes input and passes it to the next layer. Different types of neural networks include:
Feedforward Neural Networks: Data flows in a single direction from input to output.
Recurrent Neural Networks (RNNs): These networks can process sequences of data by keeping a memory of previous inputs, which is ideal for tasks like language modeling.
Convolutional Neural Networks (CNNs): CNNs are used for image processing. They utilize a series of convolutional layers to extract features from images automatically.
Natural Language Processing (NLP)
NLP is the bridge between human and computer understanding. It encompasses the application of algorithms to interpret and react to human input in a significant manner. Important uses include:
Text Analysis: Deriving valuable information from content.
Sentiment Analysis: Identifying the emotional tone behind words.
Machine Translation: Converts text from one language to another.
Computer Vision
It includes techniques that allow computers to process images and videos to extract meaningful information. Key tasks in computer vision include:
Image Classification: Identifying the category of an object within an image.
Object Detection: Locating and identifying multiple objects in an image.
Facial Recognition: Recognizing individuals based on facial features.
Cognitive Computing
Cognitive computing refers to systems that emulate human thinking in a computerized model. These systems aim to mimic human reasoning and decision-making capabilities, allowing them to understand context, learn from experiences, and interact naturally with users. A notable example of this technology is IBM’s Watson, which utilizes cognitive computing to transform natural language queries into an understandable format. This empowers Watson to analyze complex questions and provide insightful responses effectively.
Why Does AI Matter?
Businesses of all sizes are increasingly utilizing AI to enhance efficiency and drive innovation. In fact, according to the latest global survey on AI, 65% of organizations are integrating AI into their operations. Here are the major advantages of adopting artificial intelligence:
Automation of Repetitive Tasks: With AI, you can automate the mundane and repetitive tasks that take up more time and resources. From data entry to customer service, AI-powered solutions like chatbots and virtual assistants streamline processes so you can focus on more complex value-added tasks.
Enhanced Decision Making: AI can process big data and derive actionable insights. It can analyze complex information faster and more accurately than humans. These insights help you refine operations, optimize marketing strategies, and be more efficient.
Cost Efficiency: AI systems reduce operational costs by automating tasks, enhancing productivity, and minimizing errors. They are better at quickly and accurately analyzing information than humans, particularly in areas like data processing. Therefore, implementing AI in predictive maintenance and supply chain management leads to significant savings by preventing costly failures and optimizing inventory.
Enhanced Security: AI algorithms detect anomalies, flag suspicious activity, and mitigate potential breaches. For example, AI powers fraud detection systems in industries like finance, where it can detect irregular transactions and prevent losses.
Personalization: AI allows you to personalize customer experiences at scale. AI algorithms analyze user behavior, preferences, and interactions to create bespoke recommendations, messages, and services. For example, AI-driven e-commerce platforms can suggest products based on past purchases or browsing history to increase customer engagement and conversion rates.
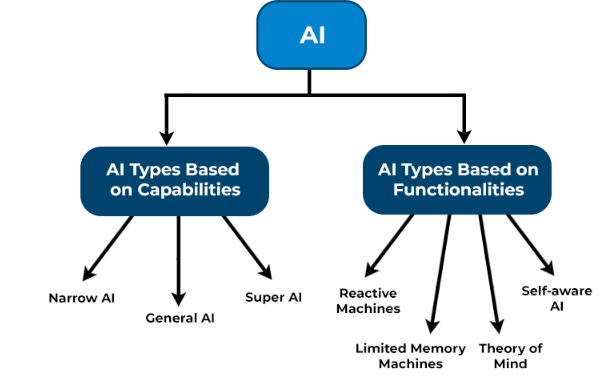
Types of AI
In this section, let’s explore the main types of AI, categorized by their capabilities and functionalities.
Based on Capabilities
The capabilities of AI refer to the scope of tasks the AI system can perform. Based on this, AI is divided into three distinct categories:
Narrow AI (Weak AI)
Narrow AI performs a specific task. It operates under predefined constraints and doesn’t possess general intelligence beyond its programmed functions. Examples include voice assistants like Siri or Alexa, which can recognize speech and execute commands but cannot think or reason beyond their scope.
General AI (Strong AI)
The Artificial General Intelligence (AGI) market size was USD 3.01 Billion in 2023 and is expected to reach USD 52 Billion by 2032. AGI is a type of AI that can understand, learn, and perform any intellectual task that a human can. Unlike narrow AI, which can be specialized for specific tasks, AGI would have the capability to generalize knowledge across different domains and improve itself over time. In January 2024, Meta declared its ambition to become the first company to develop AGI that surpasses human intelligence.
Super AI
Super AI (Artificial Super Intelligence) is a system with an intellectual scope beyond human intelligence. Super AI would not only perform tasks better than humans but also possess self-awareness and the ability to understand human emotions. Unlike current AI, which is designed for specific tasks, Super AI would combine multiple cognitive functions like a human but on a larger scale.
Based on Functionalities
AI can also be divided based on its functionalities or how it processes and acts upon data. These types include:
Reactive Machines
Reactive machines represent the simplest form of AI. They operate solely on the present data they receive without any memory or ability to learn from past experiences. A classic example is IBM’s Deep Blue. It defeated chess champion Garry Kasparov by evaluating countless possible moves in real-time but had no understanding of previous games or strategies.
Limited Memory Machines
Unlike reactive machines, limited memory AI can learn from historical data to some extent. It retains information from past interactions to improve its responses in future encounters. Self-driving cars are a prime example; they use data from previous trips along with real-time input from sensors to navigate safely and efficiently.
Theory of Mind
This type of AI aims to understand human emotions, beliefs, intentions, and social interactions. Still, in the research stages, the Theory of Mind AI would enable machines to interact with humans more naturally by recognizing emotional cues and responding appropriately.
Self-Aware AI
Self-aware AI is a type of artificial intelligence (AI) that has consciousness, self-awareness, and an understanding of its own existence. Researchers are working on ways to create self-aware AI by integrating complex algorithms that mimic human cognitive processes.
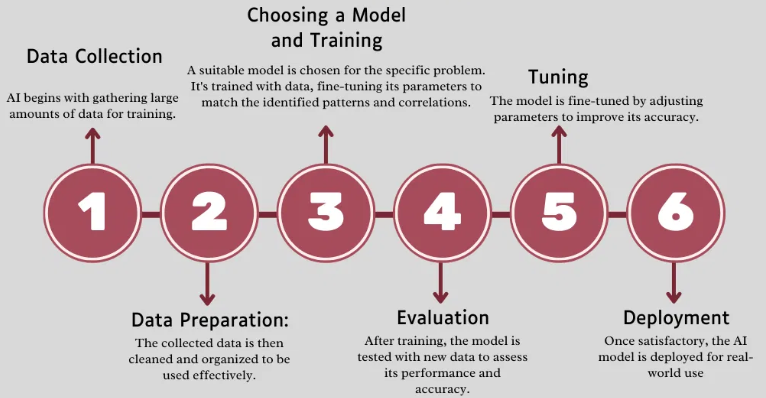
How AI Works
Let’s look at how artificial intelligence works step-by-step.
1. Data Collection
Data collection is the first step in your AI project, as it is used to extract patterns and relations. This data can come from various resources, such as databases, online repositories, sensors, etc. For example, autonomous vehicles collect input data from the environment through cameras, radar, and other sensors.
2. Data Preparation/ Preprocessing
The quality of the data you use to train your AI model is crucial. You need to preprocess this data, which involves removing outliers, noise, and inconsistencies. The data processing stage involves cleaning, normalizing, and dividing it into training and test sets.
3. Model Selection and Training
Once your data is ready, the next step is to choose an appropriate model for your task. Depending on the problem (e.g., classification, regression, clustering), you can consider different models like decision trees, neural networks, or support vector machines. The model is then trained by feeding it the preprocessed data, enabling it to learn patterns and make predictions.
4. Model Evaluation
After training your model, you should evaluate its performance using metrics like accuracy and precision. Evaluation should be done on a separate test dataset that wasn’t used during training. This helps you assess how well the model generalizes to unseen data and identifies potential areas for improvement.
5. Model Tuning
Model tuning is a critical step in refining your model to enhance its performance. This involves adjusting hyperparameters—settings that govern the training process, such as learning rate, batch size, and the number of layers in a neural network. You may use grid or random search techniques to determine the optimal hyperparameter values. Additionally, you can implement regularization techniques to prevent overfitting so the model performs well on training and new datasets.
6. Deployment
Once the model performs well, it’s ready for deployment. In this stage, the model is integrated into a production environment, interacting with real-time data and users. For example, an e-commerce website may incorporate a trained AI model for product recommendations to make suggestions to users based on browsing history.
Artificial Intelligence Examples
Artificial Intelligence is integral to your lives, enhancing convenience, efficiency, and decision-making across various domains. Here are some prominent examples:
Chatbots
Chatbots are widely used in customer service to handle common queries. For example, when you contact a business, an AI-powered bot might assist you in troubleshooting or guide you through product options. It utilizes natural language processing to simulate human conversations, offering quick, accurate responses.
Recommendation Algorithms
AI powers recommendation systems across various platforms. For instance, Netflix uses algorithms to analyze your viewing habits and suggest shows or movies tailored to your preferences. Similarly, Google’s search algorithm personalizes results based on your previous searches and interactions, making it easier to find relevant information quickly.
Digital Assistants
AI-driven virtual assistants like Siri, Alexa, and Cortana help you perform tasks like setting reminders, playing music, or controlling smart home devices through voice commands. They learn from your preferences and adapt to provide better suggestions over time.
Face Recognition
Face recognition is most commonly found in smartphones. For example, Apple’s FaceID lets you unlock your iPhone by looking at it. It utilizes advanced algorithms to map your facial features, offering a secure and convenient way to access your device.
Social Media Algorithms
Social media applications like Twitter, Instagram, and Facebook utilize AI algorithms to curate content for their users. By analyzing user behavior, such as likes, shares, and comments, these algorithms determine which posts are most relevant to each individual. As a result, users see a personalized feed that keeps them engaged and encourages them to spend more time on the platform.
Wrapping Up
This article has explored in detail how artificial intelligence works alongside real-time applications, demonstrating its transformative potential across various industries. As organizations increasingly embrace AI, understanding its capabilities and implementations will be crucial for future success.
Artificial intelligence (AI) has transformed industries worldwide. OpenAI, a leading AI research company, has played a big role in this transformation. From developing innovative tools to advancing machine learning, OpenAI is a prominent name in the AI market. However, you might want to know exactly what OpenAI does and why it is so significant for the future of AI.
Interested in learning more about OpenAI? This article will provide you with all the information you need.
What Is OpenAI?
OpenAI is an American AI research and deployment company with a focus on ensuring that AI benefits everyone. Initially, it was established as a non-profit organization to prioritize focus on the long-term positive impact of AI rather than short-term profits.
As the demand for AI solutions grew, OpenAI transitioned to a capped-profit model. This approach allows the organization to attract substantial funding for future research and development while maintaining its commitment to its mission.
What Does OpenAI Do?
OpenAI focuses on the research and development of various AI tools and technologies. Here are some key activities:
Creating Large Language Models (LLMs): OpenAI develops advanced language models, such as GPT (Generative Pre-trained Transformer), which can understand and generate human-like text.
Developing Image Generators:Image generator tools like DALL-E can help you effortlessly generate unique images from text descriptions.
Assisting Developers: OpenAI’s Codex offers assistance for software development by suggesting code snippets and providing solutions to programming challenges.
Conducting Research: OpenAI explores ways for the safe and ethical use of AI in society.
Collaborating with Companies: OpenAI partners with leading organizations, like Microsoft, to integrate its technologies into products and services.
OpenAI Timeline
2015: OpenAI is founded in San Francisco by Sam Altman, Elon Musk, Ilya Sutskever, Greg Brockman, and John Schulman.
2016: OpenAI releases Gym, an open-source platform that allows you to develop and compare reinforcement learning algorithms. It also launches Universe, a software program that helps you measure and train an AI’s general intelligence across various websites, games, and applications.
2017: OpenAI develops OpenAI Five, a bot that defeats professional human players in the popular and complex video game Dota 2. This represents a significant advancement in AI capabilities for real-time decision-making.
2018: OpenAI launches GPT-1, the organization’s first LLM, which uses a neural network architecture inspired by the human brain. It was trained on vast amounts of human-generated text, enabling capabilities such as question generation and answering.
2019: GPT-2, a larger model with 1.5 billion parameters, is released. It has improved capabilities in natural language understanding and generation.
2020: OpenAI introduces GPT-3, a landmark model with 175 billion parameters.
2021: Development of DALL-E, an AI model capable of generating images from text descriptions, and Codex, a toolthat helps translate natural language into code.
2022: OpenAI builds Whisper, a robust automatic speech recognition system, and ChatGPT, a conversational AI model. ChatGPT is based on GPT-3.5 and has gained widespread popularity for its interactive functionalities.
2023: OpenAI launches GPT-4, a multi-modal model capable of processing both text and images. It is estimated to have around 1 trillion parameters, significantly enhancing its reasoning and contextual understanding.
2024: Open AI introduces GPT-4o mini, a lightweight and efficient model for fast, simple tasks. It also launches the high-intelligence flagship LLM—GPT-4o—for complex and multi-step problem-solving tasks. Following this, the platform released Sora, an AI video generation model that enables users to create videos through text prompts.
Most Recent Launch in 2024: On December 21st, 2024, the OpenAI announced its o3 series that builds upon the o1 model for advanced reasoning tasks. However, these models are undergoing testing, with early access available only to safety and security researchers.
Insights into the Latest OpenAI Advancements
Let’s look at OpenAI’s top research and developments that are shaping the future of AI:
GPT-4o
The GPT-4 series represents the latest advancement in OpenAI’s efforts to scale up deep learning capabilities. Trained on Microsoft Azure AI supercomputers, GPT-4o can handle multi-modal inputs like text and videos. Azure’s AI-powered infrastructure helps OpenAI to deliver GPT-4 features to millions of users across the world.
Despite its advancements, GPT-4 has limitations, including social biases, hallucinations, and vulnerability to adversarial prompts. OpenAI is actively working to solve such issues to improve the model’s reliability and expand its user base.
However, the GPT-4 version is available only on ChatGPT Plus and as an API for developers to integrate its features into applications or services.
GPT-4o Mini
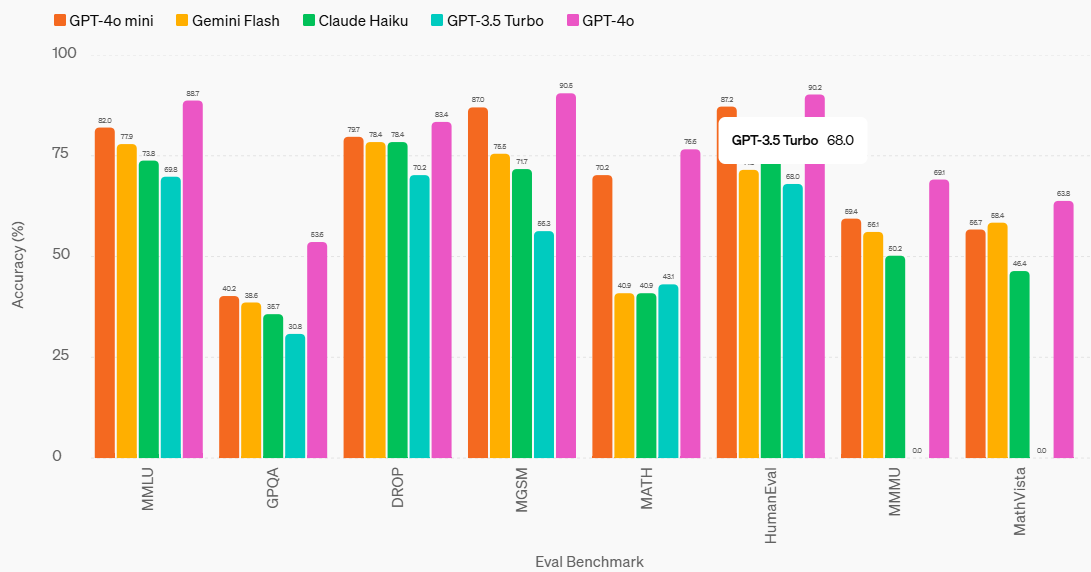
GPT-4o mini is OpenAI’s most cost-efficient small model. It outperforms the GPT-3 series and other small models across benchmarks like MMLU, GPQA, or DROP for textual intelligence and multi-modal reasoning tasks.
Another benefit of GPT-4o mini is that it uses OpenAI’s instruction hierarchy method in the API to prevent prompt injections, system prompt extractions, and jailbreaks. This makes the model more reliable and safer to use in large-scale applications.
To access the GPT-4o mini version, you can choose any ChatGPT plan—Free, Plus, Team, or Enterprise.
OpenAI o1
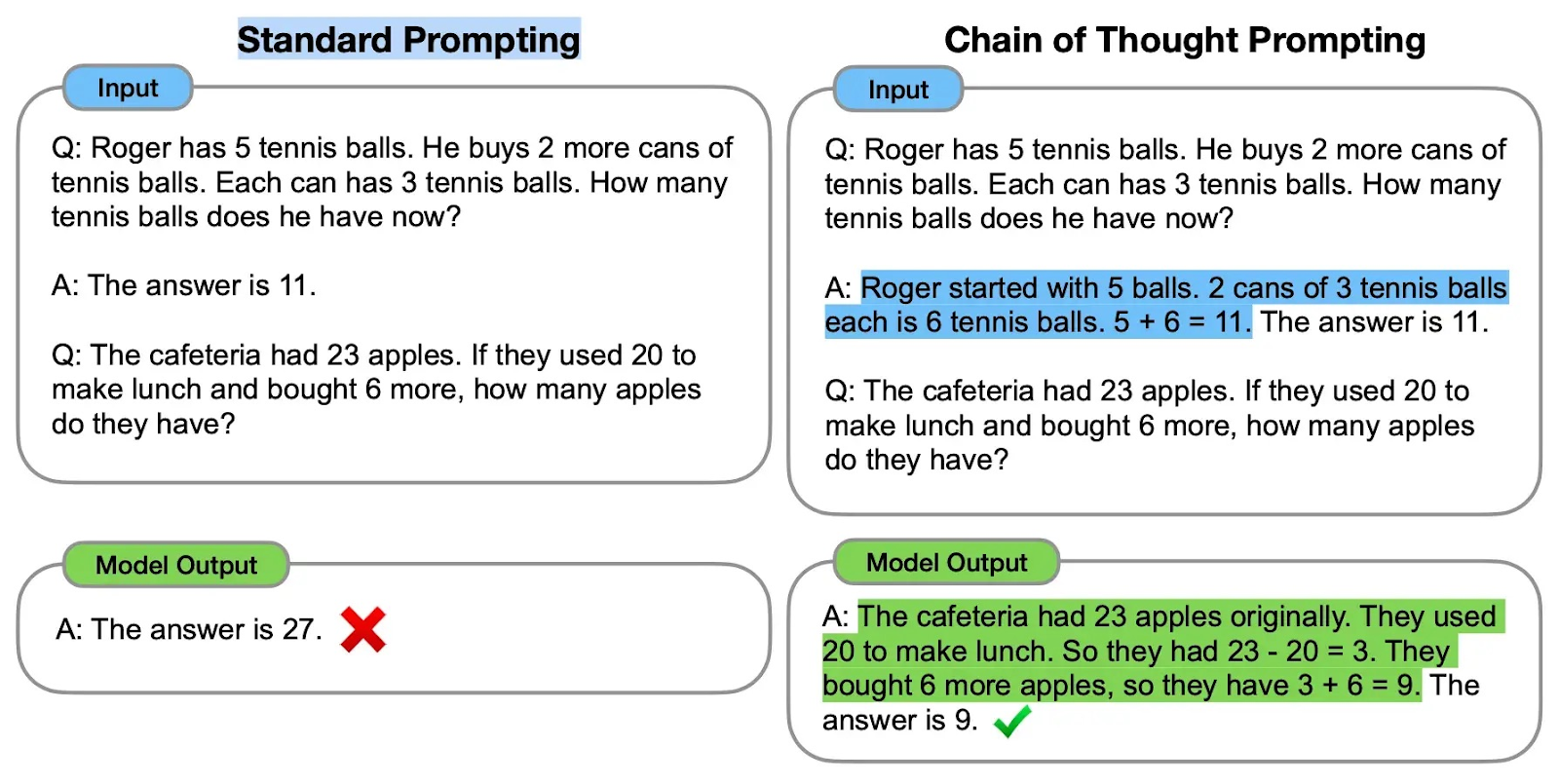
OpenAI o1 is built to solve complex mathematical and scientific reasoning problems. It is trained using large-scale reinforcement learning algorithms to improve the model’s reasoning skills. When you input a reasoning task, the o1 model can internally simulate the detailed reasoning process by following a Chain-of-Thought (CoT) prompting technique. This technique helps the model to break down problems into sequential steps for more accurate responses.
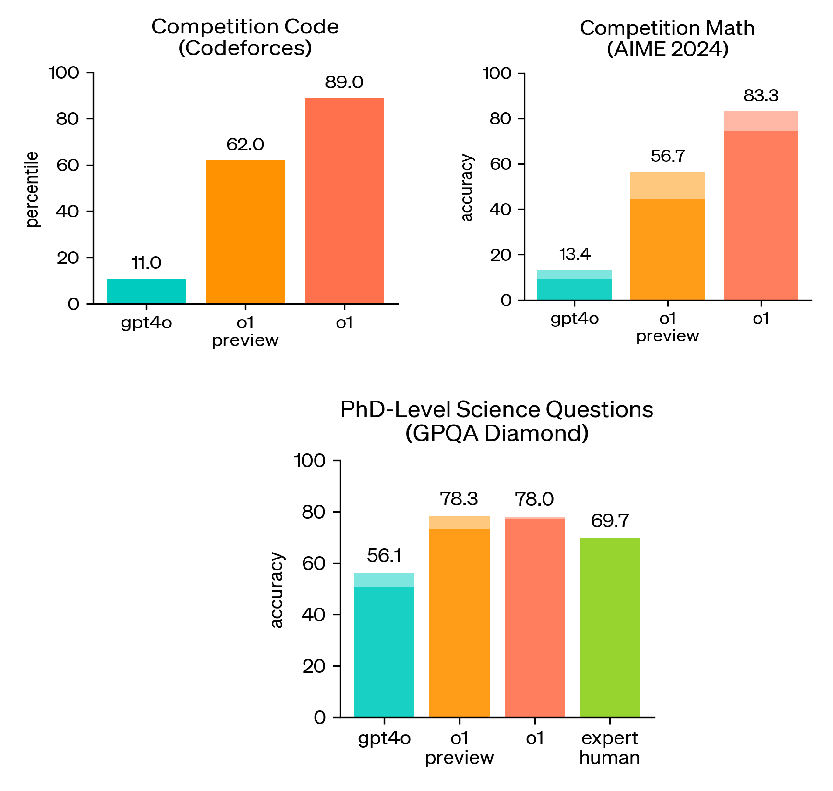
Through this learning approach, the o1 model ranks in the 89th percentile on Codeforces competitive programming and AIME 2024 math exams. It also surpasses human Ph.D.-level expertise on benchmarks like GPQA, which assesses problem-solving skills in physics, biology, and chemistry.
OpenAI o1-mini is a cost-effective reasoning model that works well for STEM fields, particularly in mathematics and coding during pretraining. Like the o1 model, OpenAI o1-mini undergoes additional training using a reinforcement learning pipeline to optimize its performance across several reasoning tasks.
Despite its lower cost, o1-mini performs better than o1-preview and o1 on multiple academic benchmarks. However, it isn’t well-suited for non-STEM topics like biographies or historical dates.
DALL-E 3
DALL-E 3 is OpenAI’s latest text-to-image model. It is capable of generating highly detailed and nuanced images directly from text prompts. Integrated with ChatGPT, it enables you to describe a scene conversationally and generate corresponding images.
One of the core capabilities of DALL-E 3 is its inpainting functionality, which aids you in editing specific parts of an image by providing targeted prompts. Once you generate an image in ChatGPT using the DALL-E 3 model, you can reprint, sell, or distribute it.
Sora
Sora is OpenAI’s diffusion-based text-to-video model, built to create high-quality videos from detailed text prompts. It can interpret complex text descriptions and transform them into visually engaging full-length videos or extend existing ones efficiently. This model maintains both visual quality and adherence to prompts, ensuring that the video aligns closely with your input.
Sora uses advanced deep learning and generative AI to create realistic visuals in educational content, advertisements, creative projects, and more. Like GPT models, it leverages transformer architecture for superior scaling to handle various durations, resolutions, and aspect ratios.
Key Tools and Capabilities of OpenAI
Here are some OpenAI tools and capabilities to help you build AI-enabled experiences in your applications:
Knowledge Retrieval (File Search): OpenAI’s File Search tools enhance the Assistant by integrating external knowledge, including proprietary product details or user-provided documents. These documents are processed, split into small chunks, and stored as embeddings in a vector database. The Assistant then uses vector and keyword search methods to retrieve relevant content and respond to user queries.
Code Interpreter: The Code Interpreter helps Assistants write and execute Python code in a secure sandbox execution environment. It supports various data file formats, generates new files, and creates visualizations like graphs. If the initial program fails to run, the Assistant can debug and reattempt execution autonomously.
Function Calling: You can integrate OpenAI’s function calling within external APIs or databases. For this, you must create custom functions for executing API calls or database queries based on the arguments from the model. This makes the AI model intelligently identify which functions to invoke and provide the necessary arguments for each call.
Vision: Many OpenAI models have vision capabilities, enabling them to process images and respond to related queries. You can provide images to the model by either including the image link or by submitting it as a base64-encoded string within the request.
Structured Outputs: JSON is one of the most used formats for data exchange across applications. The Structured Outputs feature ensures that the model produces responses that comply with your specified JSON schema. This reduces concerns about missing keys or invalid values.
Streaming: The OpenAI API supports response streaming, enabling clients to receive partial results for specific requests in real-time. This is useful for applications requiring incremental data delivery and is implemented via the Server-Sent Events (SSE) standard.
Fine-tuning: You can customize the model’s existing knowledge and functionality for specific tasks by using Supervised Fine-Tuning (SFT). This process allows the model to adapt to unique requirements while building on its existing training.
A Brief Overview of OpenAI APIs
OpenAI offers several APIs to help you integrate its advanced AI models into your applications. Here’s the list of these APIs:
Chat Completions API: This API allows you to use OpenAI’s language models in your applications to generate human-like text from user prompts. It supports creating prompts for varied tasks, including image descriptions, code snippets, structured JSON data, or mathematical explanations.
Realtime API: The Realtime API helps you create fast, multi-modal conversational experiences. It supports text and audio as both input and output. With the Realtime API, the models can adapt to vocal characteristics such as laughing, whispering, or adjusting voice tone based on the sentiment.
Assistants API: This API enables you to build AI-powered virtual assistants capable of performing tasks like answering questions, scheduling appointments, and offering recommendations. It supports code interpreters, file search, and function calling to enhance assistant capabilities.
Batch API: With the Batch API, you can send asynchronous groups of requests with higher rate limits, lower costs (50% savings), and a 24-hour turnaround time. This API is useful for efficiently processing large-scale operations.
The Next Frontier for OpenAI
The future of OpenAI is to develop Artificial General Intelligence (AGI), which aims to perform any intellectual task a human can do, enhancing creativity and innovation. AGI can potentially revolutionize our understanding of natural language and generative capabilities, offering assistance with a range of cognitive tasks.
However, AGI also carries significant risks, such as misuse, accidents, and societal disruption. To overcome these risks, OpenAI emphasizes the importance of a gradual and responsible approach to AGI development.
To read more about OpenAI’s plan to AGI, click here.
Final Thoughts
OpenAI is helping transform the future by making artificial intelligence useful, accessible, and responsible. Its tools and research enable people to work smarter, learn faster, and solve problems in innovative ways.
By focusing on safe and responsible technology, OpenAI is ensuring that AI improves our lives and creates a better future for all. With a strong specialization in AGI, OpenAI aims to build highly capable AI systems that mimic human understanding and learning. This emphasis opens doors for advanced AI technologies that can assist in almost every part of daily life.
FAQs
Can I make money using OpenAI?
Yes, you can earn money using OpenAI through the GPT Store, a marketplace for selling applications or services that utilize OpenAI’s capabilities.
Does Microsoft own ChatGPT?
No, Microsoft does not own ChatGPT. However, it has invested in OpenAI and partnered with the company.