Gemini is Google’s AI-powered assistant, developed in 2023. APK teardown is a technique developers use to examine the code within an APK (Android Packaging Kit) file. This helps them predict the features that can be introduced in an application in the future.
Android Authority published a report on October 21, 2024, on its new APK teardown of the latest beta version of the Google app. According to the report, Gemini could soon manage users’ calls and messages even if their phones were locked.
Android Authority has also shared a screenshot showing the new feature added to the Gemini settings. Users can turn on the toggle switch next to this menu, ‘make calls and send messages without unlocking,’ to enable Gemini to perform these functionalities. However, users will have to unlock the phone if the incoming message contains personal information.
Android Authority has also detected some new features that are likely to be introduced in the Gemini app. First, Google intends to make the floating overlay minimalistic and facilitate its expansion according to the number of words in the input prompt. This will help users view the maximum percentage of background UI.
Secondly, Google is increasingly supporting different extensions, and to help users manage them properly, it is likely to introduce different categories. These will include the ‘communication,’ ‘travel,’ ‘media,’ and ‘productivity’ categories.
Introducing a call and text management feature in Gemini with restraint for messages containing personal content aligns with Google’s strategy to promote responsible and user-friendly AI.
On Monday, 21 October, Honeywell announced a strategic partnership with Google that integrates artificial intelligence with industrial data to enhance operational efficiency. The collaboration aims to amalgamate AI agents with industrial assets, workforce, and processes to make them safer and more autonomous.
This partnership will combine the natural language processing capabilities of Alaphbet’s Google Gemini on Google Vertex with datasets on Honeywell Forge, the leading IoT platform. The combination of these technologies will create many opportunities across the industrial sector, including reduced maintenance costs, increased operational productivity, and employee upskilling. One of the first solutions built with Google Cloud AI will be available to the Honeywell customers in 2025.
Vimal Kapur, Chairman and CEO of Honeywell, said, “The path of autonomy requires assets working harder, people working smarter, and processes working more efficiently. By combining Google’s AI technology with Honeywell’s deep domain experience, customers will receive unparalleled and actionable insights, bridging digital and physical worlds.”
Echoing his vision, the CEO of Google Cloud said, “Our partnership with Honeywell represents a significant step forward in bringing the transformative power of AI to industrial operations.”He added, “With Gemini on Vertex AI, combined with Honeywell’s industrial data and expertise, we are creating new opportunities to optimize processes, empowering the workforce and driving meaningful business outcomes for industrial organizations worldwide.”
As the baby boomer generation is approaching retirement, the industrial sector will face significant labor and skill shortages. The demographic shift presents a considerable challenge, bringing a skill gap. Honeywell and Google’s collaboration aims to address this issue by providing solutions that enhance workforce productivity and streamline operations.
Alongside productivity gains, Honeywell and Google plan to enhance cybersecurity measures by integrating Google’s Threat Intelligence with Honeywell’s cybersecurity products. Honeywell might also explore Google’s AI capabilities with edge devices for more intelligent and real-time decision-making.
The constantly evolving apps, increasing number of consumers, and extensive digital connectivity have led to a significant increase in the volume of data generated. Sectors like e-commerce, the Internet of Things (IoT), and banks, among others, generate petabytes of data. Big data refers to the enterprise-level data that comes in a wide variety of formats.
Properly managing and analyzing this large-scale data to produce actionable insights that can enhance business performance becomes essential. Incorporating big data analytics tools into your daily workflow can help improve decision-making.
In this article, you will explore big data, its types, common challenges, and future opportunities that you must look out for.
What is Big Data?
Big data refers to the vast quantities of data generated every second by various sources such as social media, sensors, smartphones, and online transactions. This includes the millions of tweets, videos, posts, and transactions that occur globally. The real value of such big data lies in its potential to reveal hidden patterns and insights, enabling more informed business decisions.
“Big” in big data refers to the data’s volume, velocity, and variety. Such data is extensive, rapidly growing, and varied, making it difficult to process using traditional methods such as relational databases and spreadsheets.
History and Evolution of Big Data
When traditional methods of data storage and computation became inadequate for handling growing data volumes, the history and evolution of big data began.
Simple systems for managing data were first used by businesses in the 1960s and 1970s. When the internet came along in the 1990s, the amount of accumulated data went over the roof across search engines and social media platforms. This necessitated new techniques for data analysis and management.
‘Big data’ became popular in the early 2000s, indicating how hard it was to handle such huge amounts of data. Google and Amazon were among the first to develop tools like MapReduce and Hadoop to work with this data. These tools simplified the process of storing, organizing, and analyzing data.
Importance of Big Data
Big data is an essential component of the daily workflows of most organizations. Analyzing such large datasets can help optimize decision-making and identify trends. The data-driven approach of big data enables organizations to make better decisions and adapt quickly to changing situations.
Business Applications: Big data can be useful for improving services, developing new products, and optimizing your business processes. It empowers businesses to stay competitive, innovate, and enhance operational efficiency.
Governmental Use: Governments can use big data to allocate resources effectively and make better policies.
Healthcare: In healthcare, big data can help predict disease outbreaks and personalize treatment plans for individual patients.
Urban Management: Cities use image data from cameras, sensors, and GPS to detect potholes, enhancing road maintenance efforts.
Fraud Detection: With the analysis of transaction trends, big data is crucial for financial fraud detection.
The advancements in cloud computing and powerful analytic tools have made big data more accessible. These technologies enable small businesses to gain insights that were once only available to large corporations.
Big Data Types
Let’s explore the different types of big data and examples for each type to understand them better:
Structured Data
Structured data is information organized and formatted in a specific way, making it easily accessible. It is typically stored in databases and spreadsheets within tabular structures of rows and columns. This makes it easier to analyze with standard tools like Microsoft Excel and SQL.
Examples of structured data include transaction information, customer details, and sales records.
Semi-Structured Data
Semi-structured data does not follow the tabular structure of traditional data models. While semi-structured data is not as strictly organized as structured data, it still contains identifiable patterns. It often includes tags or markers that make it easier to sort and search the data.
Some common examples of semi-structured data include emails, XML files, and JSON data.
Unstructured Data
Most big data consists of unstructured data, which is complex and not immediately ready for analysis. Unstructured data is typically text-heavy but can also contain dates and numbers. You can analyze this data using advanced machine learning and natural language processing tools.
Some examples of unstructured data include text files, videos, photos, and audio files. Companies like Meta and X (formerly Twitter) extensively utilize unstructured data for their social media and marketing activities.
What Are the 5 V’s of Big Data?
The 5 V’s of big data represent key dimensions that can help you leverage your organizational data for superior insights and products. These dimensions include Volume, Velocity, Variety, Veracity, and Value. Each has a crucial role in the management and analysis of big data.
Volume
Volume indicates the amount of data generated and stored. While the volume of big data can be extensive, effective management is crucial to handling this data and deriving meaningful insights. As data volumes continue to grow, traditional analysis and storage solutions may be insufficient. Instead, scalable storage solutions like cloud-based services and specialized big data tools can significantly enhance your experience with large-scale data.
Velocity
Velocity refers to the speed at which the data is created. Such data is rapidly generated from numerous sources like high-frequency trading systems and social media platforms. To process this data, you must incorporate in-memory data processing tools with robust capabilities to analyze large amounts of data in real time for timely decision-making.
Variety
Variety describes the range of data types and formats. The data you encounter on a daily basis could be structured data in tabular formats, semi-structured data like XML or JSON files, or unstructured data like videos and audio. To manage and integrate disparate data types for analysis, you must use flexible data management systems. Tools like NoSQL databases, schema-on-read technologies, and data lakes provide the necessary flexibility to work with big data.
Veracity
Veracity defines the reliability and accuracy of your data. High-quality data is crucial for achieving accurate and trustworthy analytical results. To address data quality issues, you can employ techniques like data cleaning, validation, and verification, helping ensure data integrity and reduce noise and anomalies.
Value
Value is the usefulness of your data. Effectively analyzing and utilizing data for business improvements brings out the true value of your data. The data holds potential value if you can transform it into actionable insights that can help improve business processes, enhance customer engagement, or aid with strategic decisions.
Big Data Analytics
Big data analytics is the process of examining varied datasets—structured, unstructured, and semi-structured—to find hidden patterns, correlations, trends, and insights. This analysis helps with informed business decisions, guiding strategy, streamlining operations, and improving customer satisfaction.
Companies that specialize in big data analytics use advanced technologies such as AI and machine learning (ML) to analyze extensive datasets across all data types. Major IT companies, like Wipro, Accenture, Genpact, etc., use big data analytics to harness their data.
Industries like logistics and manufacturing can use big data analytics to improve their supply chain efficiency and address equipment maintenance needs. This predictive capability enables you to review historical data and also predict future trends and outcomes.
Challenges in Big Data
Big data presents numerous opportunities but also introduces significant challenges that businesses must address.
Managing and Tracking Data: The effective management and tracking of the vast amounts of generated data is a primary challenge. As data grows exponentially, it needs to be stored, organized, processed, and analyzed in a timely manner. Traditional management systems often lag in processing such data volumes. This mandates new technologies and infrastructures, which can be expensive and complex to implement.
Data Quality: Data quality is yet another important issue. The data collected might not always be accurate, complete, or relevant, resulting in incorrect conclusions and poor decision-making. Maintaining the accuracy and consistency of data requires constant efforts in verification and validation. This requires substantial resources, adding to the operational costs.
Data Security: Privacy and security are two prominent concerns with increasing data volumes. This is primarily because data often includes sensitive personal information, which increases the risk of data breaches and unauthorized access. To protect sensitive information, businesses must invest in strong security measures and follow strict data protection regulations.
Unstructured Data Analysis: Analyzing unstructured data, such as videos and social media posts, comes with its own set of challenges. You require advanced analytical tools and specialized skills to extract valuable insights from unstructured data. This involves additional investments in technology and training, often creating a barrier for many organizations.
The Future of Big Data
As data generation continues to increase exponentially, the future of big data will pave the way for significant advancements. Integrating advanced tools such as AI, quantum computing, and machine learning will help simplify the collection, storage, and analysis of big data for a more efficient process.
Big data will become a significant part of our daily lives, making our experiences more personalized. A common example is the use of big data in smart cities to improve traffic flow and reduce energy consumption. Similarly, healthcare is beginning to leverage big data to create personalized medicines based on an individual’s genetic makeup.
Businesses are increasingly relying on big data to generate new ideas and methods for improving the quality of their products and services.
Despite the advancements, the challenges of data privacy, security, and ethical use will persist. As organizations collect more data, it becomes essential to ensure responsible use of the data. This requires protecting the data from unauthorized access and adhering to ethical standards to prevent misuse.
Summary
Big data comprises the vast amounts of data created daily from sources like social media, sensors, and online transactions. The proper utilization of this data can help with decision-making, prediction of trends, and enhancement of services. However, managing big data presents challenges, including ensuring data quality and safety.
While technologies like AI and machine learning improve data analysis, privacy and ethical issues remain. A key consideration is to secure customers’ sensitive information to prevent breaches.
While big data analysis offers benefits such as enhanced decision-making and operational improvements, you must adhere to strict governance and security protocols. This ensures responsible data usage and protection of the data from unauthorized access and exploitation.
FAQs
What is big data, and what are its use cases?
Big data is a collection of large volumes of structured, semi-structured, and unstructured data generated from multiple sources like social media, emails, and sensors. Its primary use cases involve creating effective marketing campaigns, analyzing customer churn, and conducting sentiment analysis. This helps understand consumer needs and behavior better.
What are the five pillars of big data?
The five pillars of big data, also known as the five Vs, are volume, velocity, variety, veracity, and value.
Is big data still relevant?
Yes, big data is still relevant. It is a critical asset for organizations that handle large amounts of data daily. Analyzing big data is still considered an essential business step to produce effective insights and enhance decision-making and business strategies.
Python is a robust programming language that provides multiple built-in functions. Among the popular methods is ‘split’. This method enables you to manipulate string data types effortlessly by converting them into a list. With Python split, you can modify the elements of a string and store them in another string variable.
This guide will help you understand the Python split method and how you can use it in different applications with the help of practical examples.
What Is the Python Split Method?
The Python split string method is an in-built function of the Python programming language. It enables you to convert strings to list data types. This method is useful, especially for applications that require optimal data allocation. Distributing data across different data types can enhance data accessibility and reduce time consumption while performing operations.
Converting string elements to a list provides you the flexibility to modify the individual characters of the generated list of substrings. This feature can be attributed to the mutability principle of lists. Mutable data structures allow you to modify their elements, which is absent in string datatype as it is immutable.
Syntax of Python Split
In Python, the split method follows the following syntax:
str.split(sep, maxsplit)
In this syntax snippet, ‘str’ represents the string that you want to split, whereas ‘sep’ and ‘maxsplit’ are the attributes of the split method.
Arguments of the Python Split Method
The split function has two arguments that you can use to specify how you want to break the string into different components. Here’s an overview of each:
sep: This parameter specifies the delimiter of the string, which separates the string into a list. For example, if sep is a hyphen character, sep = “-”, the split method returns a list of elements based on hyphens between the characters. If string = “Demonstration-of-split-method”, then string.split(sep= ‘-’) will return a list with values [ “Demonstration”, “of”, “split”, “method”].
maxsplit: This parameter lets you specify the number of elements in the resulting list. When you specify the value of maxsplit, the split method breaks down the string into (maxsplit+1) elements and stores them in a list. By mentioning the sep argument with the maxsplit, you can split a string using the delimiter as sep into a list of maxsplit+1 elements. For example, if string=“Demonstration of split method”, then string.split(maxsplit=3) will return [“Demonstration”, “of”, “split method”].
Examples of Python Split Method
Let’s explore a few examples that can help you better understand the capabilities of the split function.
print(f“Splitting a string using an alphabet: {string.split(sep= ‘a’)}”)
Output:
Splitting a string using an alphabet: [‘Apple, Pine’, ‘pple, Gu’, ‘v’, ‘, M’, ‘ngo, Kiwi, Or’, ‘nge’]
#6 Splitting user input into different components
userdata = input(“Please enter your first name and the genre of music you like in (name, genre) format: ”)
name, genre = userdata.split(sep=”,”)
print(f“Welcome, {name.strip()}. If you like {genre.strip()}, you are in the right place.”)
Output:
Please enter your first name and the genre of music you like in (name, genre) format: John, Jazz
Welcome, John. If you like Jazz, you are in the right place.
Python RSplit Method
Python rsplit method is another built-in function similar to the split method. However, the rsplit divides the string starting from the right end of the specified string. The rsplit function also has two arguments, ‘sep’ and ‘maxsplit’. The maxsplit divides the string into maxsplit+1 number of list elements starting from the right index of the string. For example, if
The resulting rsplit solution: [‘Apple#Pineapple#Guava’, ‘Mango’, ‘Kiwi’, ‘Orange’]
Combining Python Split and Join Methods
The join method is built-in and works the opposite of the Python split function. It converts a list to a string by joining all the elements of the list together and storing the result in a string. By combining the Python split and join methods, you can enhance the capabilities of strings, converting them into a mutable list and then modifying the content. This modified list can then be stored in a string using the join method.
Let’s explore an example of the join method and how it can be used with the Python split method.
You can also use the type method to know about the data type of the results produced.
print(f “The class the result of join function belongs to is {type(result)}.”)
Output:
The class the result of the join function belongs to is <class ‘str’>.
Modifying Strings with Joins
Let’s look at an example demonstrating how you can use the join method to modify string data types.
string = “This is an immutable string.”
newList = string.split()
newList.insert(4, “mutable”)
newString = “ ”.join(newList)
print(newString)
Output:
This is an immutable mutable string.
In this example, you can observe that a string can be converted into a list to update characters/words in the list. After manipulating the original string, you can use the join function to create a string out of the updated list.
Considerations While Using Python Split
When you are using the Python split method, multiple aspects can help you enhance your experience and produce expected results. This section will highlight some of the common best practices to follow and mistakes that you must avoid:
You must thoroughly understand how the sep argument works before defining it in an application. A small mistake with this parameter can lead to unexpected results. For example, you can check this Stack Overflow forum, where the user mistakenly defined sep.
It is possible to generate a list of sentences from a document using the split function. For that, you can specify “.” as sep. However, you must consider whether the sentence ends with other characters like “?” or “!”. To split semantic sentences, you can utilize advanced natural language processing (NLP) libraries like NLTK.
You might encounter sentences containing different regular expression (Regex) characters like “^”, “!”, and “?”, among others. Directly performing a split method on such sentences might produce unexpected results. To perform Python split on Regex, you can use the re.split() method. For example, if you want to split IP addresses into different components:
import re
ip = ‘192.168.0.1:8080’
tokens = re.split(r‘[.:]’, ip)
print(tokens)
Output:
[‘192’, ‘168’, ‘0’, ‘1’, ‘8080’]
Conclusion
Understanding data types is the first and most necessary step in developing an application. To enhance user experience, you must allocate different data to the best-fitting data type.
String and list are the most widely used data types in Python. Converting one to another can help you switch between the mutability and immutability principles of each. Python split method is an efficient way to convert a string to a list, which can then be modified according to your needs.
FAQs
What is split in Python?
Python split is an in-built method to break a string into elements and store them in a list.
Does the split method modify the string in place?
No, the Python split method does not modify the string in place. To see the results, you must assign the split method to a variable.
A draft guidance was released in England on October 22, 2024. In it, the National Institute for Health and Care Excellence (NICE) suggested using AI tools from TechCare Alert, BoneView, RBfracture, or Rayvolve for X-ray imaging of bone fractures.
This guideline has once again highlighted the relevance of AI in the healthcare sector. According to NICE, in 3-10% of bone fracture cases, diagnostic errors occur because of manual detection and a lack of trained experts.
An AI-powered X-ray diagnostic solution consists of algorithms that can analyze vast amounts of data. This helps medical practitioners identify patterns between historical trends and current medical queries with speed and high precision.
The Indian radiology sector is also witnessing rapid advancements, and utilizing AI solutions will further enhance X-ray diagnostics. The radiology market in India is expected to grow at a CAGR of 12-15% in the next five years.
By integrating AI into radiology workflows, medical professionals can automate processes such as image scanning, report generation, and healthcare data management. This improves the efficiency of clinical workflows, leading to better and more personalized treatment.
AI-based X-ray solutions produce high-quality images, enabling radiologists to ensure the accuracy of outcomes. They facilitate fast and precise identification of hairline fractures and diseases such as small tumors or pneumonia. Patients can make use of these results to take early-stage prevention and treatment in advance.
According to Business Standard, as per the recently published Health Dynamics of India 2022-23 report, many sub-centers in rural India do not have their own buildings. Sub-centers are the initial point of contact between rural communities and primary healthcare centers (PHCs).
Due to the lack of such infrastructure, it is not feasible to deliver high-quality and advanced healthcare services in rural and remote areas. The medical fraternity, especially radiologists, can utilize artificial intelligence and teleradiology to provide services in distant areas. AI can speed up the analysis and delivery of services in such geographies, reducing downtime and assuring timely mitigation of any medical issue.
While interacting with Express Healthcare, Dr Bilal Thangal T M, Medical Lead, NURA, said that AI-enabled X-ray imaging has a promising future in India. However, for effortless integration of these services into existing workflows, we need to work on resolving the current challenges. These include the absence of regulatory frameworks, data security, and the lack of skilled radiologists.
Once the concerns are resolved, India can develop a robust healthcare sector that offers a wide range of services to every nook and corner of the country.
Python is a versatile programming language used widely for data analytics, manipulation, and visualization. The rich ecosystem of Python libraries offers several functions, allowing you to handle different data structures and perform mathematical computations. It also helps you to train machine learning models and create advanced visualizations. This article enlists the top 10 Python libraries for data analytics that professionals can use to fulfill their data-related objectives.
Why Python is Preferred for Data Analysis?
Python is the most preferred programming language used by data analysts for the following reasons:
Simplicity
Python has a simple syntax, unlike other programming languages that have complex syntax. As a result, it is a very user-friendly language, allowing you to execute queries more easily. You have to use indentation to separate blocks of code in Python, which makes them well-structured and organized. This increases readability and lowers the learning curve for you if you are a beginner in coding.
Community Support
Python has a vast global community of developers who actively interact and contribute to promoting and developing the programming language. There are also documentation, tutorials, and forums that help you learn the language quickly and resolve your queries if required.
Extensive Libraries
Python offers a diverse set of libraries for different computational operations. For data manipulation or cleaning, you can use NumPy and Pandas. The programming language supports the Scikit-learn library for machine learning, while you can use the Matplotlib and Seaborn libraries for visualizations. For scientific computing, Python offers SciPy, which is used extensively by the scientific community.
As a result, Python offers a comprehensive set of libraries to perform most computational tasks, making it a popular coding solution. In the section below, let’s look at some of these libraries in detail.
Top 10 Python Libraries for Data Analysis
Some essential Python libraries for data science are as follows:
1.NumPy
The Numerical Python or NumPy Python library is one of the most preferred Python libraries for data manipulation. It facilitates seamless operations on arrays and is used extensively in science and engineering domains. NumPy offers an extensive library of functions that can operate on multidimensional array data structures such as homogenous, N-dimensional ndarrays.
You can import it into your Python code using the following syntax:
import numpy as np
You can access any NumPy feature by adding a prefix (np.) before them. NumPy enables you to perform various operations on entire arrays simultaneously, making it faster than the loops. Arrays also consume less memory than Python lists, as they store similar types of elements together. This speeds up computation further, especially when you are handling large datasets.
NumPy facilitates using various mathematical functions for operations such as trigonometry, statistical analysis, linear algebra, and random number generation. Several Python libraries, such as Pandas, SciPy, or Scikit-learn, are based on NumPy. It is an important library of the Python ecosystem that helps you with data analysis, machine learning, and scientific computing.
2. Pandas
Pandas is an open-source Python library that allows you to perform data manipulation, analysis, and data science operations. It supports data structures such as series and data frames, simplifying working with single—or multidimensional tabular data structures. The syntax to import Pandas into your Python ecosystem is as follows:
import pandas as pd
You can use the prefix (pd.) to access any feature or function in Pandas. It offers features for data cleaning that enable you to handle missing values, filter rows, and transform data according to your requirements. You can also easily remove or add rows and columns in Pandas data frame for efficient data wrangling. To perform these tasks, you can use labels of rows and columns to access data rather than using integer-based indexing.
The Pandas library supports various data types, including CSV, Excel, SQL, JSON, and Parquet. It performs in-memory operations on large datasets, enabling fast data processing.
3. Matplotlib
Matplotlib is a library that helps you create static and interactive visualizations in Python. You can use it to create simple line plots, bar charts, histograms, and scatter plots. Matplotlib also facilitates the creation of advanced graphics such as 3D plots, contour plots, and custom visualizations. The syntax to import the Matplotlib library is as follows:
import matplotlib.pyplot as plt
You can use Matplotlib’s predefined visual styles or customize the colors, line styles, fonts, and axes according to your requirements. It can also be directly integrated with NumPy and Pandas to create visuals of series, data frames, and array data structures. Matplotlib is the basis of Seaborn, another Python library for visualization that aids in developing statistical plots.
You can save the graphical plots created in Matlplotlib and export them in different formats such as PNG, JPEG, GIF, or PDF.
4. Seaborn
Seaborn is one of the important Python libraries used for data analysis and visualizations. It is based on Matplotlib and is helpful for creating interactive statistical graphs. Seaborn streamlines the data visualization process by offering built-in themes, color palettes, and functions that simplify making statistical plots. It also provides dataset-oriented APIs that enable you to transition between different visual representations of the same variables. You can import this library using the following command:
import seaborn as sns
The plots in Seaborn are classified as relational, categorical, distribution, regression, and matrix plots. You can use any of these according to your requirements. The library is handy for creating visualizations of data frames and array data structures. You can use several customization options available to change figure style or color palette to create attractive visuals for your data reports.
5. Scikit-learn
Scikit Learn, also known as Sklearn, is a Python library known for its machine learning capabilities. It allows you to deploy different supervised and unsupervised machine learning algorithms, including classification, regression, clustering, gradient boosting, k-means, and DBSCAN. Scikit-learn also offers some sample datasets, such as iris_plant or diabetes, that you can use to experiment and understand how machine learning algorithms work.
To install the Scikit-learn library, you must first install the NumPy and SciPy libraries. After installation, you can import specific modules or functions according to your requirements rather than importing the whole Scikit-learn library. You can use the following command to import Scikit-learn:
import sklearn
After extraction, you can preprocess your data effectively using splitting, feature scaling, and selection features of Scikit-learn. You can then use this data to train your machine learning models. The models can be evaluated with functions that can track certain metrics. This involves calculating accuracy, precision, and F1 scores for the classification model and mean squared error for regression models.
6. SciPy
SciPy is a scientific Python library that enables you to perform scientific and technical operations. It is built on NumPy and aids in performing complex data manipulation tasks. While NumPy provides functions that help you work on linear algebra, or Fourier transforms, SciPy contains comprehensive versions of these functions. The command to import SciPy in your Python notebook is as follows:
import scipy
SciPy offers the required functions in the form of several scientific computational subpackages. Some subpackages are cluster, constants, optimize, integrate, interpolate, and sparse. You can import these subpackages whenever you want to use them for any task.
7. TensorFlow
TensorFlow is an open-source Python library that simplifies conducting numerical computations for machine learning and deep learning. It was developed by the Google Brains team and has simplified the process of building machine learning models using data flow graphs. You can call TensorFlow in Python notebook using the following command:
import tensorflow as tf
TensorFlow facilitates data preprocessing, model building, and training. You can create a machine learning model using a computational graph or eager execution approach. In the computational method, data flow is represented as a graph. In a graph, mathematical operations are represented as nodes, while the graph edges represent data as tensors that flow between the operations. Tensors can be understood as multidimensional data arrays.
In eager execution, each operation is run and evaluated immediately. The models are trained on powerful computers or data centers using GPUs and then run on different devices, including desktops, mobiles, or cloud services.
TensorFlow consists of several additional features, such as TensorBoard, which allows you to monitor the model training process visually. The library supports Keras, a high-level API for accomplishing various tasks such as data processing, hyperparameter tuning, or deployment in machine learning workflows.
8. PyTorch
PyTorch is a machine learning library based on Python and Torch library. The Torch library is an open-source machine learning library written in Lua scripting language and is used to create deep neural networks. To use PyTorch in your Python ecosystem, you have to import the Torch library using the following command:
import torch
PyTorch was developed by Facebook’s AI research lab and is used especially for deep learning tasks like computer vision or natural language processing. It offers a Python package to compute tensors using strong GPU support. PyTorch also supports dynamic computational graphs that are created simultaneously with computational operation executions. These graphs represent the data flow between operations and facilitate reverse-automatic differentiation.
In machine learning, differentiation measures how a change in one variable can affect the model’s outcome. In automatic differentiation, you can find derivatives of complex functions using the chain rule of calculus. In this differentiation technique, the function is broken down into simpler components whose derivatives are known and then combined afterward to get the overall derivative. Forward and reverse are two modes of automated derivates, and PyTorch supports reverse-automatic differentiation.
9. Requests
Requests is an HTTP client library for Python that is used to send HTTP requests and handle responses. You can use it to interact with websites, APIs, or web services while using the Python ecosystem. Python provides an interface to send and retrieve data from such sources using HTTP methods such as GET, POST, PUT, or END.
You can use the below command to import the requests library in Python:
import requests
After installing and importing the requests library, you can make a simple HTTP request using the requests. get () function. This function takes a URL as an input argument and returns a response object.
The response object contains all the information returned by the server, which is a data source. It contains the status code, header, and response body, which you can access and then make the next request again. As a result, the Requests library enables you to perform web-related tasks effectively in Python.
10. Beautiful Soup
Beautiful Soup is a web-scraping Python library for extracting data from HTML and XML files. It is a simple library and supports various markup formats, making it a popular web scraping solution. While using Beautiful Soup, you can create parse trees for the documents from which you want to extract data. A parse tree is a hierarchical representation of the derivation process of an input program. You can use the code below to call the Beautiful Soup library:
from bs4 import BeautifulSoup
Beautiful Soup library enables you to navigate, search, and modify the tags, attributes, and texts in the parse trees using various methods and functions. You can use this library along with Requests to download web pages for faster parsing.
How to Choose a Python Library
You can keep the following things in mind while choosing Python libraries for data analytics:
Define Clear Objectives
You should clearly understand the purpose for which you want to use a Python library. You can use Python libraries for data analytics, manipulation, visualization, machine learning operations, or web scraping. You should list these functions to identify the specific library or set libraries that will help you achieve your goals.
Ease of Use
Evaluate the library’s learning curve, especially if you are working on tight deadlines. You should always try to prioritize ease of use and how well the library integrates with other tools or libraries. The library should also have detailed documentation and tutorials to help you better understand its functions.
Performance and Scalability
For high-performing libraries, you should compare the features of the one you intend to use with those of other libraries with similar functionality. As your organization grows, you have to deal with large amounts of data. The library should be scalable to accommodate this increase in data volume.
Community Support
Active community support is essential for troubleshooting and quick resolution of any queries. A responsive user base contributes regularly to updating the functionalities of any library. They also guide you if you are a new user to overcome challenges and become proficient in using the library.
Conclusion
The extensive set of libraries offered by Python makes it highly useful for data-driven operations. The 10 Python libraries for data analytics explained here have their unique capabilities and contribute to the efficient functionalities of Python. Leveraging these libraries can help you handle complex datasets and retrieve meaningful insights.
Data is an essential asset for every organization. However, possessing large volumes of data cannot help you make informed business decisions. Translating this complex information into a format your stakeholders can understand is crucial. By leveraging data visualization, you can make your data accessible and actionable.
This article will explore data visualization in detail, including its advantages and the top five tools you can use for visualizing your data. It will also introduce you to several real-world data visualization examples to help you understand the scope of this technique.
What Is Data Visualization?
Data visualization involves graphically representing raw data by transforming it into visual elements like charts, graphs, or maps. This makes it easier to explain and interpret complex information. Data visualization helps you identify patterns, trends, and outliers within your data that might be difficult to spot in numerical form.
Using a visual approach, you can quickly gain insights from your data and make informed business decisions. Data visualization is widely used across industries, such as business, science, geography, and technology, to communicate new findings to a broader audience.
Why Is Data Visualization Important?
With data visualization, you can compress the information residing in large volumes of data into a digestible, easy-to-remember format. It helps you create compelling narratives that convey your ideas while keeping your audience engaged. Data visualization promotes a data-driven culture within your organization by making data more accessible and understandable.
Here are five reasons why data visualization is crucial:
Facilitates Compliance and Reporting: Visual reports can simplify compliance processes by enabling easier tracking and reporting on key metrics.
Bridges Communication Gaps: Visual data can be leveraged to break down communication barriers between technical and non-technical stakeholders, fostering better collaboration.
Encourages Exploration: Interactive visualizations allow you to explore data from multiple perspectives, leading to new insights and discoveries.
Contrasting Datasets: By graphically comparing multiple datasets, you can discover unexpected relationships, differences, and correlations that might not be apparent.
Supports Real-Time Monitoring: Dashboards with real-time data visualization allow your organization to monitor performance and react swiftly to disruptions.
Types of Data Visualization
When you think of data visualization, some of the most common types are bar graphs, pie charts, and line graphs created using Microsoft Excel. However, many data visualizations are now available based on their usage and requirements.
In this section, you will explore some of the most effective and interesting types of data visualizations.
Treemaps: A treemap displays hierarchical data in a nested format in rectangles, where each rectangle’s size represents a proportional percentage of data value. They help visualize your file systems or organizational charts.
Gantt Charts: Gantt charts are bar charts that visualize the timelines of projects and their dependencies. You can use them for project management tasks to track progress and identify potential bottlenecks.
Heat Maps: A heat map uses color gradients to represent data such as temperature distributions or geographical patterns across a two-dimensional grid. It showcases the intensity or frequency of data points, making it easier for you to spot trends or outliers.
Box-and-Whisker Plots: These are also known as box plots. They help summarize a dataset’s distribution by showing the median, quartiles, and potential outliers. You can use them to identify variability and skewness in your data.
Population Pyramids: With population pyramids, you can visualize and analyze demographic trends and patterns, such as existing age groups, gender imbalances, and future population growth prediction.
Area Charts: Area charts are like line charts, but the area beneath the line is filled in. You can utilize them to track changes over time and visualize cumulative totals or trends across multiple data series.
Highlight Table: Highlight tables are simple tables with conditional formatting applied to highlight specific values or data points using color, shading, or other visual cues. They are beneficial for quickly drawing attention to important information within a table.
Bullet Graphs: Bullet graphs are a simplified version of bar charts that help you compare a single value to a target or benchmark. They are often used to visualize performance metrics, such as sales targets or customer ratings.
Advantages and Disadvantages of Data Visualization
Data visualization is a powerful technique that enhances data comprehension using graphical representations. However, like any other technique, it has advantages and disadvantages. Understanding them is crucial to maximizing the potential of data visualization.
Advantages
Data visualization allows you to easily share the crux of complex data, enabling stakeholders to grasp essential details quickly and collaboratively plan the next steps.
You can interact with your data more effectively, explore various perspectives, and drill down into specific details to gain a deeper understanding.
Data visualization offers a clear and concise overview of your data, enabling you to identify opportunities, risks, and potential areas for improvement.
Disadvantages
Data visualizations can be misleading or oversimplified if not designed carefully or lack the necessary context, leading to incorrect conclusions and poor decisions.
Complex visualizations with too much information can be overwhelming. This makes extracting meaningful insights or understanding the key message difficult.
Data visualization is heavily dependent on the quality of the underlying data. If your data is inaccurate, incomplete, or biased, the visualizations will also be flawed.
Examples of Data Visualization
Many advanced techniques, such as infographics, bubble clouds, and time series charts, are available to help express your data in the most efficient way. Below are some real-world data visualization examples:
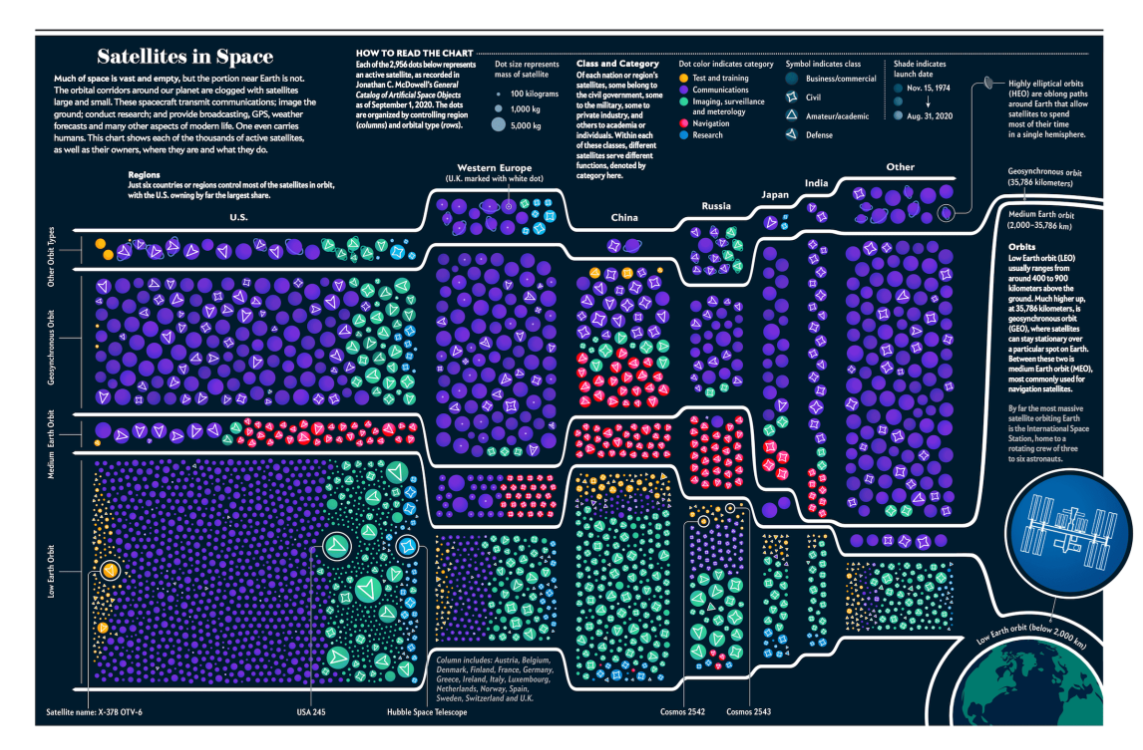
Active Satellites in Space
This data visualization was created for Scientific American to showcase the diverse population of satellites orbiting Earth. The satellites are clustered and arranged in grids based on country, orbit, and type—business/commercial, civil, amateur/academic, or defense.
The graphic provides detailed information about each satellite, including its mass, category (e.g., Communications, Surveillance and Meteorology, Navigation and Research), and launch date. The data used for this visualization spans from November 1974 to August 2020.
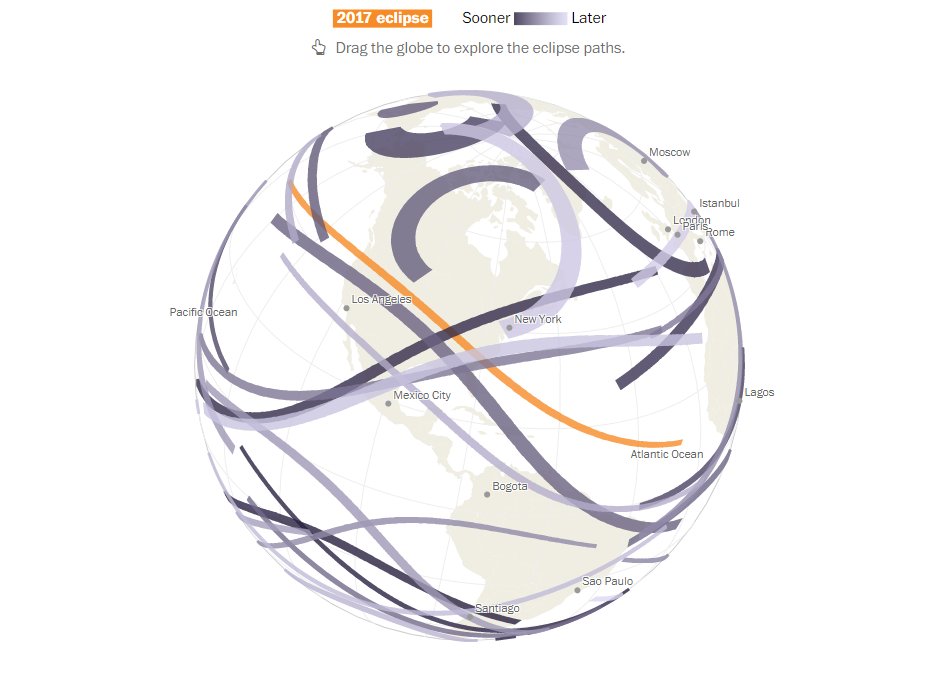
Every Total Solar Eclipse Until 2080
After the August 2017 coast-to-coast solar eclipse, the Washington Post created an interactive globe visualization showing eclipse paths up to 2080. The spinning globe highlights areas of total eclipse.
The visualization also provides information about the timing of these eclipses, using light and dark shades and interactive tooltips. A unique feature of this visualization is that it allows you to input your birth year, and the tool calculates the number of eclipses you can see in your lifetime.
Top 5 Data Visualization Tools
Many data visualization tools are available in the market. By selecting the tool that fits your use case, you can simplify the process of turning raw data into compelling visuals. Here are the five most versatile data visualization tools for you to explore:
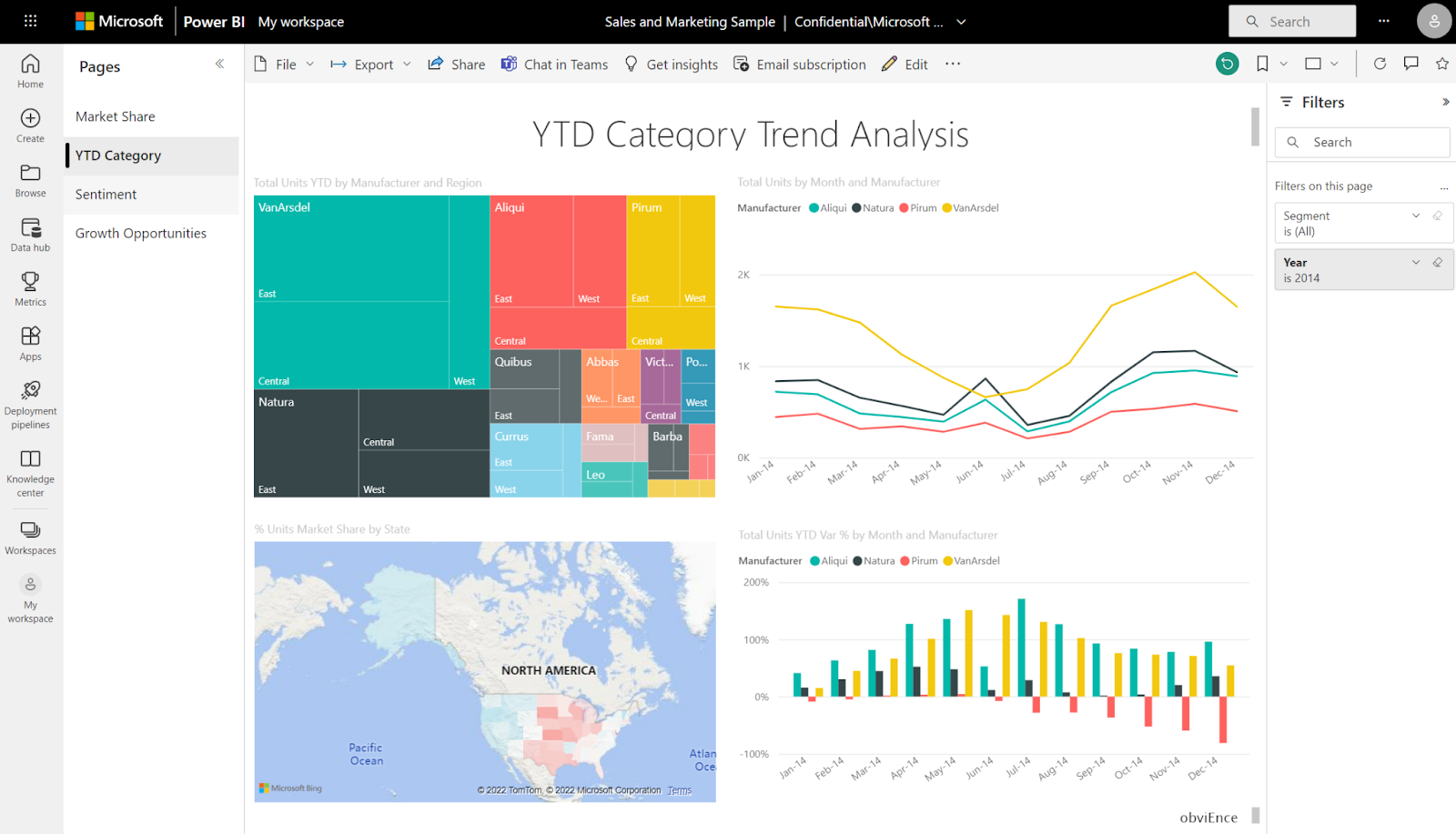
PowerBI
Power BI, a comprehensive business intelligence platform, empowers you to transform data into actionable insights. It offers a user-intuitive interface and integrates with data sources, including Salesforce, PostgreSQL, Oracle, Google Analytics, Github, Adobe Analytics, Azure, SQL Server, and Excel.
Key Features
Customizable Visuals: Beyond the vast library of pre-built visualizations, Power BI offers a marketplace where you can discover and download custom visualizations created by the community. This flexibility enables you to tailor your visualizations to specific data types or industries.
Natural Language Queries: Power BI supports natural language queries, enabling you to ask questions about your data in plain English. This allows even your non-technical teams to explore and analyze data without requiring extensive knowledge of data modeling or query languages.
Tableau
Tableau is a powerful data visualization tool with an extensive library of visualization types and an easy-to-use drag-and-drop interface. It offers desktop, server, and web-based versions to suit different needs and provides CRM software for managing customer relationships. You can directly connect Tableau to various sources, including databases, spreadsheets, and cloud applications.
Key Features
Geo-Spatial Visualization: Tableau’s powerful mapping capabilities enable you to create interactive maps displaying data points on a geographic canvas. These maps help you identify trends, analyze spatial distribution, and discover valuable insights into spatial patterns and relationships.
Live Dashboards: You can create interactive dashboards that update instantly as new data arrives, giving you access to the most recent information. Tableau also has extensions for integrating external tools or APIs for real-time processing and improving functionality.
Zoho Analytics
Zoho Analytics is a data visualization and business intelligence tool you can integrate with online reporting services to create and share extensive reports in minutes. It allows you to ingest data from over 250 sources, such as local files, web URLs, cloud drives, business applications, and custom applications.
Key Features
Blended Data Visualizations: Zoho Analytics allows users to combine data from multiple sources and create blended visualizations, enabling cross-functional analysis and a holistic view of business performance.
Dynamic and Interactive Exploration: You can view underlying data to explore specific details, use drill-downs for granular analysis, and apply contextual filters to focus on relevant data. These features enable you to perform ad-hoc data exploration.
Datawrapper
Datawrapper is a free, open-source data visualization platform. This GDPR-friendly tool allows you to create interactive charts or maps that can be embedded within your websites or reports. Its interface is beginner-friendly and has a drag-and-drop facility, enabling people with non-technical backgrounds to easily explore data.
Key Features
Responsiveness and Accessibility: The visualizations created by Datawrapper are responsive and optimized for different devices. They meet the web accessibility standards and are compatible screen readers, accommodating people with color blindness and visual impairment.
Documentation and Support: Datawrapper offers comprehensive documentation and support to help you create effective visualizations. You can access step-by-step tutorials, guides, and a supportive community to learn and get assistance.
Qlik Sense
Qlik Sense is a business intelligence tool that leverages artificial intelligence to help you explore data effectively. It allows you to create interactive dashboards, visualizations and reports to gain broader context and deeper insights. Qlik Sense is available as a software-as-a-service (SaaS) or a hybrid service that extends SaaS analytics to your on-premises data.
Key Features
Associative Model: Qlik Sense automatically connects data relationships across different datasets and offers a comprehensive view of insights. You can visualize all relevant associations by making interactive selections or using the smart search.
Data Storytelling: This feature allows you to combine charts and narratives, making it easier to communicate data analytics results. It provides intelligent and in-context commentary that helps you convey data in a more understandable way.
Closing Thoughts
Data visualization is a powerful technique that can completely change how you interact with and understand data. By representing data visually, you can discover hidden trends and patterns, communicate complex ideas, and make informed decisions.
While numerous data visualization tools are available in the market, make sure you choose the right tools and techniques relevant to your specific needs. Data visualization enables you to get the most out of your data and helps you leverage the information gained to stay ahead of the curve.
Data generation has increased in the past few decades due to technological advancements, social media, and interconnected devices. According to a Statista report, global data creation will increase to more than 180 zettabytes by 2025. With large-scale production, there should be a mechanism to handle and interpret this data effectively.
Data science provides the essential tools and techniques for managing and utilizing data to gain meaningful insights and make informed decisions. You can also leverage it to improve operational efficiency, foster innovation and risk management, and gain a competitive advantage in your business domain. In this article, let’s explore the components, applications, and career opportunities of data science.
What is Data Science?
Data science is an interdisciplinary field that allows you to study unstructured and structured data to perform data-driven activities. It involves interpreting or analyzing large volumes of data with knowledge of statistics, computer science, mathematics, and specific domain expertise.
The conclusions drawn using data science can help you make informative decisions for the growth of your organization. As a result, the subject has found applications in marketing, e-commerce, education, policy-making, and even the healthcare sector.
Key Components of Data Science
The key components or processes involved in data science are as follows:
Data Collection
The first and most important step in leveraging data science is gathering data relevant to your intended problem. For this, you have to collect data from various sources, which may be structured or unstructured.
Structured data is stored in tabular format in relational databases, Excel, or CSV files. You can gather this data using ELT or ETL data integration. Alternatively, you can use APIs or directly load them into programming consoles like Jupyter or R Studio.
Unstructured data, on the other hand, is not organized in a pre-defined manner. Examples of unstructured data are PDF files, photos, videos, audio files, or log files. Depending on the type of unstructured data, you can use data scraping, crawling, optical character recognition, and speech-to-text translation techniques for extraction.
Data Engineering
The data you have collected can be in raw format, and you must prepare it before utilizing it for analysis. The practice of developing and maintaining a system for managing and converting raw data into usable format is called data engineering.
It involves data cleaning and transformation techniques such as deletion, normalization, aggregation, and feature engineering. These procedures help resolve issues like missing values, duplicate data points, outliers, and inconsistent data formats.
Statistics
Statistics enables you to uncover patterns and relationships within datasets to make informed decisions. Descriptive and inferential approaches are two important statistical approaches used by data scientists.
In descriptive statistics, you can use mean, mode, median, variance, and standard deviation to get a comprehensive overview of datasets. Inferential statistics involves sampling large datasets and using hypothesis-testing techniques to make accurate predictions. You can use any of these two statistical methods as per your requirements.
Machine Learning
Machine learning is a subset of artificial intelligence that uses specialized models to perform specific tasks. These models are built using algorithms trained on large volumes of datasets. Machine learning models facilitate pattern recognition and predictive analysis based on historical data.
You can leverage ML capabilities to automate data-driven decision-making in your organization. It is used extensively for fraud detection, speech recognition, product recommendations, and medical diagnosis.
Programming Languages
Learning programming languages such as Python, SQL, or R is the fundamental prerequisite for becoming a data scientist. Python is the most commonly used language because of its simplicity and support for feature-rich data manipulation libraries such as NumPy and Pandas. The Scikit-learn library offers machine learning features to enable pattern recognition. You can also leverage Python’s visualization libraries Matplotlib and Seaborn to create interactive data visualizations.
Structured Query Language (SQL) is appropriate for querying data in relational databases. It supports a wide range of operations to insert, update, and delete data. You can use functions like COUNT, SUM, MIN, MAX, or AVG in SQL to aggregate your data. SQL also offers join operations such as LEFT, RIGHT, INNER, or OUTER to combine data from multiple tables.
R is a specialized programming language used for statistical computational analysis. It offers several statistical packages and visualization libraries that help in exploratory data analysis and hypothesis testing.
Big Data
Big data refers to huge datasets of terabytes or petabytes in size that traditional databases cannot handle. It is characterized by high volume, variety of sources from which it is extracted, and velocity with which it is received. Big data facilitates raw material for data science operations. These operations enable you to analyze and interpret big data easily to draw useful conclusions for making strategic decisions.
Applications of Data Science
Here are some prominent applications of data science:
Finance
In finance, data science is used for fraud detection by analyzing suspicious patterns in transaction datasets. You can also use it for portfolio optimization and risk management by analyzing market trends and stock prices. Credit scoring is another important application that allows you to check a borrower’s creditworthiness by using data science to analyze financial history.
E-Commerce
You can use data science to segment customers of your e-commerce portal based on their browsing behavior, purchase history, and demographics. With this information, you can develop a product recommendation system to suggest personalized products according to customer preferences. Data science also helps analyze market trends and competitor pricing for optimal pricing strategy.
You can streamline inventory management using data science to track overstocking or understocking. It further aids in performing sentiment analysis based on customer reviews and feedback.
Healthcare
Using data science to analyze patient data to create a personalized treatment plan is now feasible. In drug discovery, data science can identify useful chemical compounds from a vast dataset, making the process fast and efficient. Managing pandemic outbreaks has also become easier with the use of data science. It helps track infection rates, identify hotspots, and perform predictive analyses of symptoms to understand disease development.
Nowadays, data science has found applications in wearable devices like smartwatches to track health metrics for preventive care.
Aviation Industry
In the aviation industry, data science is helpful in analyzing factors such as weather, fuel consumption, and air traffic to optimize flight operations. It helps manage ticket prices and seat availability for better operational efficiency and customer experience. You can also implement data science for maintenance purposes using algorithms that predict and prevent potential mechanical failures, ensuring safety.
Education
You can use data science in education for curriculum development by optimizing course content and teaching strategies. It can track students’ performance and help you to identify students who are falling behind to provide them with targeted support. Data science also helps with administrative processes such as enrollment management and budgeting.
How to Start a Career in Data Science
Data science has emerged as a critical field, and there is a high demand for professional experts in this domain. The data science salary trends show that the domain rewards highly competitive remuneration as the demand is rising with the increasing importance of data. To start a career in data science, you can follow the below roadmap:
Understand the Basics
First, you should gain a comprehensive understanding of the data science domain. Then, start learning a programming language such as Python, SQL, or R. Along with this, develop a good understanding of statistics, mathematics, and theoretical concepts related to data science.
Specialize in a Niche
You should determine the area of data science that interests you most, such as machine learning, data analysis, or data engineering. Then, focus on acquiring specialized skills and knowledge related to your selected niche. Several online platforms offer specific data science courses that you can subscribe to enhance your capabilities.
Gain Practical Experience
After equipping yourself with essential skills, you should start working on personal or open-source projects. There are numerous online competitions in which you can participate to build a good portfolio. This will help you gain hands-on experience in the field and build a portfolio you can showcase to recruiters.
Network
You should attend industry events or meetups to connect with data professionals and understand the latest industry trends. There are online forums, discussion groups, and social media communities that you can join to exchange thoughts with like-minded people and experts. You can also ask questions, resolve queries, and showcase your skillset to grab the attention of hiring companies.
Search for Jobs
To begin the search for data science jobs, you should create a resume highlighting all your necessary data science skills. While applying, first understand the job role and tailor your resume according to the skills demanded by that role. This will increase your chances of getting a call for an interview. Prepare for data science questions and reach out to professionals who have faced similar interviews to understand the hiring process.
Stay Updated
Data science is continuously developing, and you must keep learning to stay relevant in this domain. Try to stay informed by reading about the latest developments, attending conferences, and researching emerging trends in data science.
Types of Data Scientist Roles
Professionals working in the data science domain can fulfill one or more of the following roles and responsibilities:
Data Scientist
Data scientists are experts who use modeling, statistics, and machine learning to interpret data. They create predictive models that can forecast future trends based on historical data. Moreover, data scientists also develop algorithms that can simplify various complex processes related to product development. They are also involved in research to explore new methodologies to help organizations enhance their data processing capabilities.
Data Strategist
Data strategists are professionals who develop strategies to help organizations use their data optimally to generate value. They work with different departments, such as marketing, administration, and sales, along with data scientists and analysts to help them efficiently use their domain data. Generally, companies outsource experts for data strategist roles, and they should clearly understand the company’s objectives before devising a data strategy.
Data Architect
A data architect designs and manages an organization’s data infrastructure according to objectives set by a data strategist. They create the structure of the data system, ensure seamless data integration from various sources, and oversee the implementation of databases. The data architect also selects tools and technologies for data management and security.
Data Engineer
The work of data architects and data engineers is slightly similar, but there are some major differences. While data architects design the data infrastructure, it is the responsibility of the data engineer to implement and maintain this infrastructure. They perform the data integration process and clean and transform the integrated data into a suitable format.
Data Analyst
Data analysts evaluate integrated and standardized data to discover hidden patterns and trends. To achieve this, they use visualizations and techniques such as descriptive analysis, predictive analysis, exploratory data analysis, or diagnostic analysis. These processes help data analysts generate essential insights for organizations to make better business decisions.
Business Intelligence Analyst
To some extent, the job roles of data analysts and business intelligence analysts overlap. However, a data analyst’s main job is to understand data patterns related to specific business processes. BI analysts, on the other hand, are responsible for aiding the growth of the overall business by creating interactive reports that summarize the business performance across the entire organization.
ML Ops Engineer
ML Ops engineers are responsible for deploying and managing machine learning models to automate different processes in an organization. They conduct model retraining, versioning, and testing to ensure that the ML models provide accurate outcomes over time. ML Ops engineers can collaborate with data scientists, data engineers, and software developers to ensure effective model integration and operation.
Data Product Manager
Data product managers are responsible for overseeing the development of data products. Some examples of data products are LLMs like ChatGPT or applications like Google Maps. By studying market trends, data product managers define the objectives and create a roadmap for data product development. They lead the product development process from concept to launch and ensure data governance and quality management.
Depending upon your interest and skill set, you can opt for any of these roles and pursue a highly rewarding career in the data science domain.
Future of Data Science
The data science industry will see rapid advancement in the coming years due to the increasing reliance of different sectors on data for decision-making. With AI and machine learning becoming integral to human lives, data science will become more relevant, uncovering previously unattainable insights.
You can expect to see data science playing a pivotal role in healthcare, finance, marketing, and even policy-making sectors. Advancements in generative AI and natural language processing will help data scientists extract deeper insights from complex datasets to develop innovative solutions. Integrating data science with technology such as blockchain will also help create a robust security framework across different sectors.
Conclusion
Data science is driving innovation in different domains and reshaping human lives by enabling the extraction of data-driven insights from vast amounts of datasets. The elevation of machine learning and artificial intelligence will only deepen the impact of data science, facilitating even more sophisticated analyses and predictive capabilities. This will create many career opportunities for the talented and skilled young generation.
Despite such versatile applications, there have been instances where inaccurate data was used to encourage biases, discrimination, or privacy violations. However, the growing emphasis on data privacy and ethical considerations is introducing much-required transformations. Regulatory frameworks like GDPR and HIPAA are compelling practitioners to use data responsibly. However, there is still a long way to go, and promoting ethical usage through educating society and strong governmental frameworks is the need of the hour.
Meta released Llama 3.2 on September 25, 2024, two months after Llama 3.1 launch. This new version includes both vision and text models which are tailored to enhance various applications from image understanding to summarizing tasks.
Llama 3.2 vision models 11B and 90B are designed for image reasoning tasks like document-level understanding, including charts and graphs, captioning, and visual analysis. These models bridge the gap between vision and language by extracting specific details from an image, understanding it, and then generating an answer. You can use Llama 3.2 11B and 90B for custom applications using Torchtune, deploy them locally using Torchchat, and also connect through the smart assistant Meta AI.
The lightweight models of Llama 3.2, 1B, and 3B support context lengths of 128k tokens and are utilized for tasks like summarization, rewriting tasks on edge, or instruction following. Meta uses two methods for these models: pruning and distillation, which makes them highly lightweight and able to fit on devices efficiently.
These models can also run locally, ensuring privacy and instantaneous responses, as the data does not need to be sent to the cloud for processing. This makes Llama 3.2 1B and 3B ideal for applications requiring strong privacy protection.
In conjunction with the model release, Meta is also offering a short course on Llama 3.2, taught by Amit Sangani, Director of AI Partner Engineering at Meta. The course deep dives into the capabilities of Llama 3.2. You can find the course on DeepLearning.AI, an online education platform that released the course in partnership with Meta. Here’s what you can learn from it:
Features of Meta’s four new models and when to use which Llama 3.2 model.
Best practices for multimodel promoting and application to advance the image reasoning with many examples.
Know the different user roles used in Llama 3.1 and 3.2, including system, user, assistant, and ipython, and the prompts used to identify these roles.
Understand how Llama uses the Tiktoken tokenizer and how it expands the vocabulary size to 128k to improve encoding and multilingual support.
Learn about Llama Stack, a standardized interface for toolchain components like fine-tuning and synthetic data generation that is useful for building agentic applications.
This launch demonstrates Meta’s commitment to open access and responsible innovation. By offering the short course, Meta ensures that developers can access the necessary tools and resources to build applications.
Zeta Alpha is a premier neural discovery platform that allows you to build advanced AI-driven enterprise solutions. It leverages the latest Neural Search and Generative AI to help improve how you discover, organize, and share internal knowledge with your team. This approach enables you to enhance decision-making, avoid redundant efforts, stay informed, and accelerate the impact of your work.
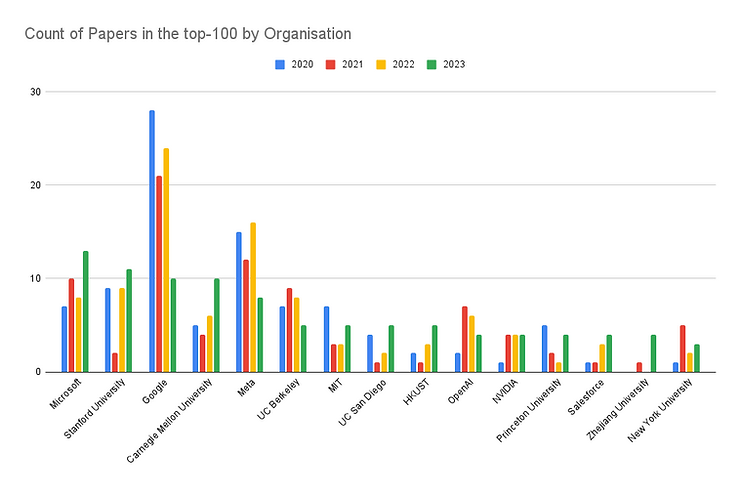
On October 9, 2024, Zeta Alpha announced the top 100 most cited AI papers in 2023. Meta’s publications on LLaMA, Llama 2, and Segment Anything secure the first three spots in AI research.
The paper LLaMA: Open and Efficient Foundation Language Models, which has 8534 citations, introduces a collection of foundation models ranging from 7 billion to 65 billion parameters. The paper also shows that LLaMA-13B outperforms the 175B parameter GPT-3 model on most benchmarks.
Ranking second, the Llama 2: Open Foundation and Fine-tuned Chat Models paper has 7,774 citations. It presents a set of pre-trained and fine-tuned language models with parameters ranging from 7B to 70B. These are Llama 2-Chat models specifically optimized for dialogue use cases to enhance conversational AI capabilities.
Gaining the third position, the meta paper on Segment Anything discusses a new model for image segmentation with zero-short performance. The paper also noted that the model is released with a large dataset (SA-1B) of 1B masks and 11M images. This initiative aims to advance research in foundation models for computer vision.
Although Meta’s papers hold the top three positions, Microsoft leads with 13 papers in the overall top 100 compared to Meta’s eight.
Following Microsoft, Stanford University has 11 papers, while Carnegie Mellon University and Google each have 10. This demonstrates a strong presence of different industries in AI research. For more insights on these rankings, visit the Zeta Alpha post by Mathias Parisol.