In computer programming, data type specifies a particular value that you can store in a variable. Understanding data type enables you to decide the operations that can be performed on it and the information that can be extracted from such data. Integer, date/time, and boolean are some of the common examples of data types.
Python is an extensively used programming language because of its simplicity and support for feature-rich libraries. Knowing the different Python data types is crucial to understanding how data can be queried in this computational language.
In this article, you will learn about various data types in Python with examples and how to find the type of any data point. It also provides methods to convert one data type into another, which will help you use Python more effectively for data-related tasks in organizational workflows.
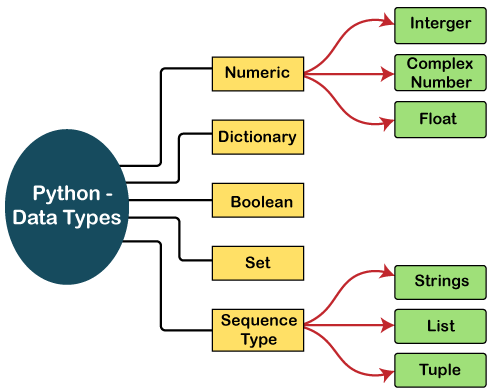
The Python data types are broadly categorized into five types as follows:
Numeric Data Type
Dictionary
Boolean
Set
Sequence Data Type
To know the data type of any entity in Python, you can use the built-in function type(). For example, to know the data type of x = 7, you can use the type() function in the following manner:
Now, let’s look at each one of these data types in detail.
Numeric Data Type
The numeric data type represents the data that has a numeric value. It is further classified into three types as follows:
Integer Data Type
The integer data type consists of positive and negative whole numbers without decimals or fractions. Python supports integers of unlimited length and you can perform various arithmetic operations on these integers. This includes operations such as addition, subtraction, multiplication, division, or modulus.
In the example below, you can see that when you check the data type of x = 5 and y = -11, you get output as an int type.
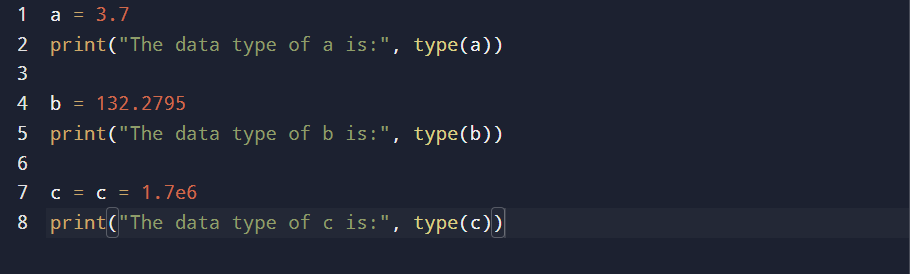
Float Data Type
The float data type comprises numbers with decimal points or scientific notation. Python supports float data with accuracy up to 15 decimal points.
This example shows different float data points supported by Python.
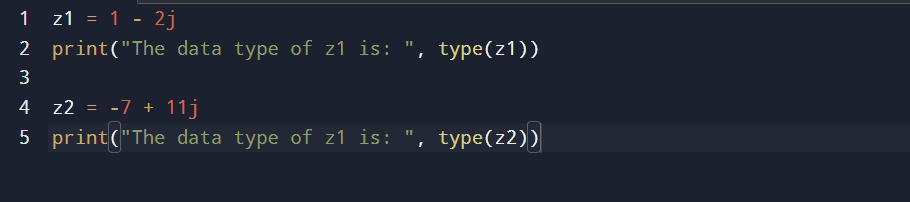
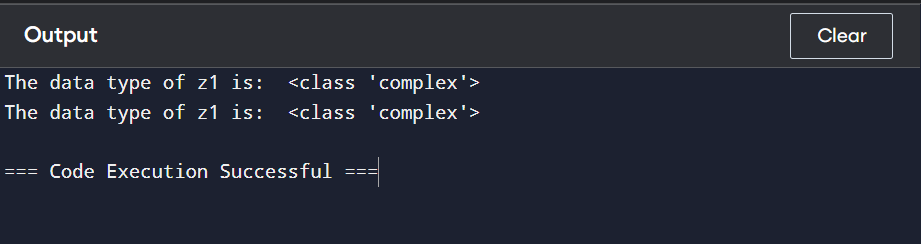
Complex Data Type
The complex data type contains real and imaginary parts. In Python, the imaginary part is denoted by j instead of i, as in mathematics. In the example below, 1 – 2j is a complex number where 1 is the real part, and 2 is the imaginary part.
Dictionary Data Type
A Python dictionary is an unordered collection of data stored as key-value pairs, enabling faster data retrieval. You can create a dictionary by placing data records within curly brackets {} separated by comma. The key and value together are one element and are represented as key: value.
Both key and value can be of any data type; however, values can be mutable, while keys are immutable. The syntax to write a Python dictionary is as follows:
Dict_var = {key1:value1, key2:value2, ….}
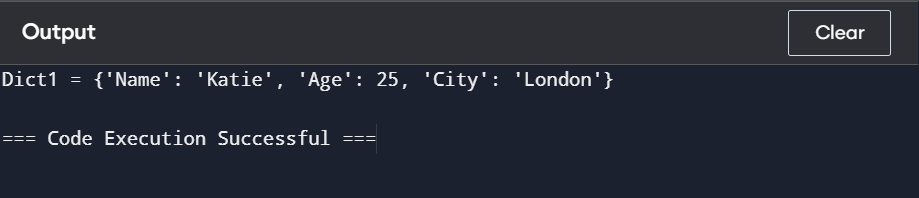
Consider the following example of a Python dictionary:
Here, “Name”, “Age”, and “City” are keys while “Katie,” 25, and “London” are corresponding values.
Boolean Data Type
Python boolean data type represents one of the two values: True or False. It is used to determine whether a given expression is valid or invalid. Consider the following examples:
The output is:
To check the data type of the boolean value, you can use the following syntax:
This gives the following output:
Set Data Type
The set data type in Python represents an unordered collection of elements that are iterable but cannot be duplicated. It is created by enclosing individual elements in curly brackets {} separated by commas. The syntax to write set is as follows:
Set1 = {element1, element2, element3,….}
The following example shows a set data type in Python:
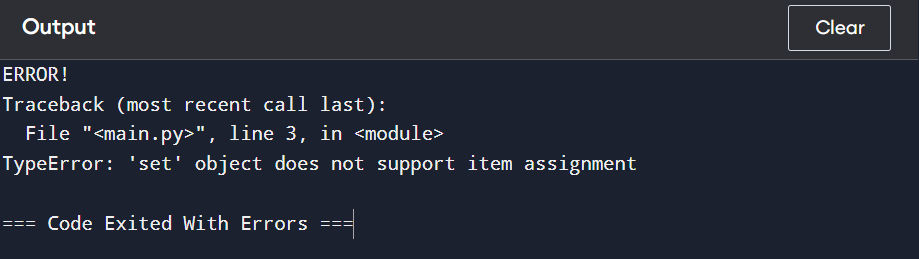
You can add or remove elements from sets as they are mutable.
However, you cannot directly change the individual elements in the set.
Sequence Data Type
The sequence data type allows you to store and query the collection of data points. There are three sequence data types in Python: string, lists, and tuple. Let’s look at each of these in detail.
String
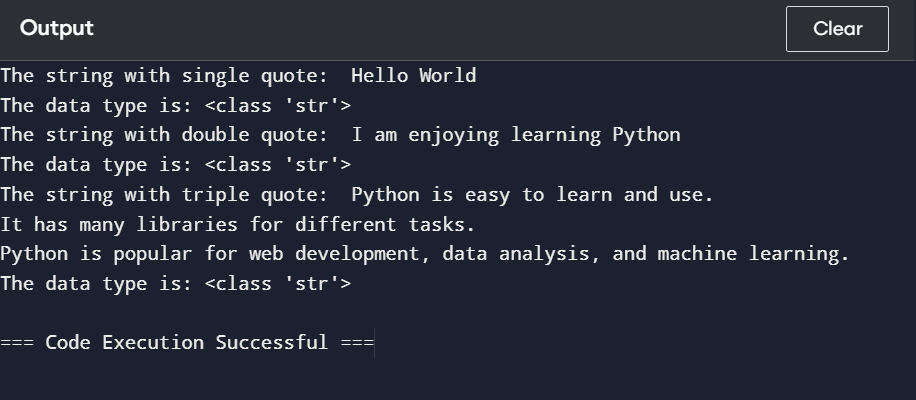
It is a sequence of characters enclosed within a single, double, or triple quotation.
This gives the following output:
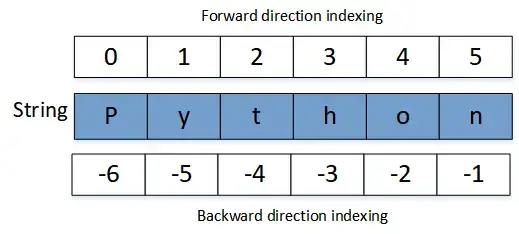
To access individual characters in a string, you can use a technique called indexing. In positive or forward indexing, you can create a string containing n number of elements from 0 to (n-1). On the contrary, negative indexing is a backward indexing technique where the last element is numbered as -1 and the first as (-n).
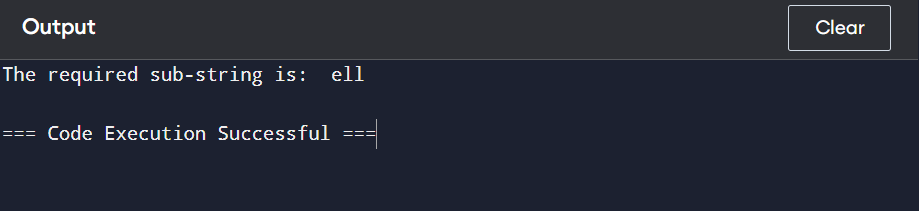
To get a sub-string from a string, you can opt for slicing operations as shown below:
String data types allow you to perform the following operations:
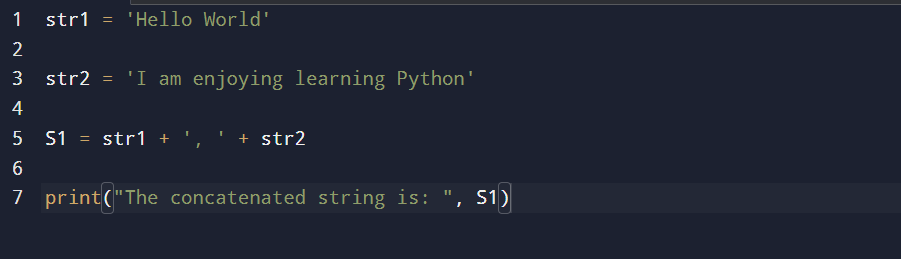
Concatenation: Using this process, you can join together two or more strings using the ‘+’ operator.
Repetition: You can multiply a string by an integer to create a specified number of copies.
Replace: The replace() allows you to replace a character in a string.
Upper and Lower Case: You can convert a string in upper or lower case using the upper() and lower() functions.
Output:
Checking the Case of a String: To check whether the string is in lower or uppercase, you can use the islower() or isupper() functions. The output is a boolean data type.
Output:
Split: You can split a string into individual characters separated by space using split().
Output:
Lists
Python lists are like arrays containing elements in an ordered manner. You can create a list simply by placing individual elements separated by commas within square brackets [ ]. Its syntax is:
List1 = [element1, element2, element3,…..]
Here is an example of a Python list:
Not all the elements in the list need to be of the same data type. For example, the below list contains a mix of string, integer, and float data types.
To fetch elements in a list, you can follow the indexing method as in a string. Similarly, you can also perform concatenation and repetition by multiplying with an integer on lists. Some of the other operations that you can perform on a list are as follows:
Append: You can use append() to add a new element to the list.
Output:
Extend: extend() is used to add all elements from an iterable, such as a list, tuple, or set, to the end of a given list.
Output:
Pop: To remove the last element from the list, you can use pop().
Output:
Tuple
A tuple is a sequential data type similar to a list as it supports indexing, repetition of elements, and nested objects like a list. However, unlike a list data type, a tuple is immutable. You can easily create a tuple by placing elements in round brackets separated by commas, as shown below:
Tuple1 = (element1, element2, element3,….)
The operations supported by the tuple are similar to those supported by the Python list. Now, in the next section, you will learn how to convert one Python data type to another.
Python Data Type Conversion
Python allows you to convert one data type to another using the following two methods:
Python Implicit Type Conversion
Python Explicit Type Conversion
Let’s look at each one of these conversion techniques in detail:
Python Implicit Type Conversion
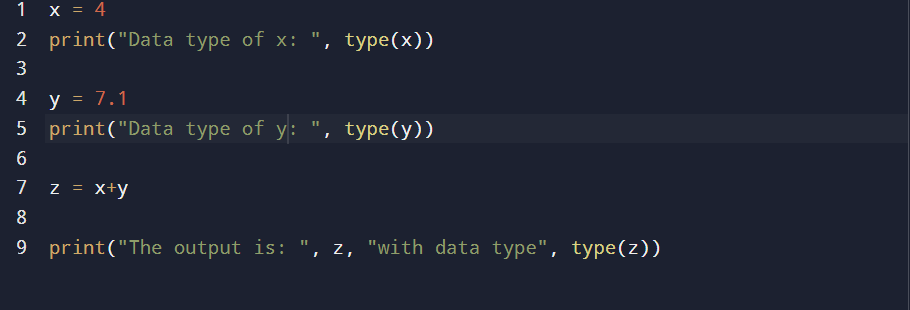
In implicit type conversion, the Python data type of output obtained through an operation automatically gets converted to another form. For example, you want to add x = 4 with an int data type and y = 7.1 with a float data type. The data type of output z will be float as shown below:
Python Explicit Type Conversion
You can manually change the Python data type according to your requirements using the explicit type conversion method. Some of the functions that can be used for explicit type conversion are as follows:
Function
Conversion
int()
string, float -> int
float()
string, int -> float
str()
int, float, list, tuple, dictionary -> string
list()
string, tuple, dictionary, set -> list
tuple()
string, list, set -> tuple
set()
string, list, tuple -> set
complex()
int, float -> complex
Here is an example of explicit conversion of int data into float data type:
Final Thoughts
Python’s support for different data types makes it a rich and versatile programming language. Understanding these data types is crucial for coding and efficient problem-solving in Python. It simplifies managing large datasets and performing complex calculations.
This article explains Python basic data types in a comprehensive way, along with data type conversion methods. You can utilize this guide to leverage Python capabilities to the maximum extent and become an effective programmer.
Cloud computing is transforming the way you handle IT needs. Regardless of your organization’s size, it allows you to save time, reduce storage costs, and increase efficiency.
As cloud computing is becoming popular, there is a huge increase in cloud-based applications and services. Cloud computing makes it all possible, whether you’re streaming your favorite show, managing business operations, or collaborating with your team globally.
If you want to learn more about cloud computing, you are in the right place. This article guides you through the cloud computing architecture, types, benefits, limitations, and use cases. Explore leading cloud service providers and the latest trends in cloud computing.
What Does Cloud Computing Define?
Cloud computing is the on-demand availability of resources like storage, processing power, networking, and software apps delivered as services via the Internet. It is also referred to as Internet-based computing and helps you eliminate the need to access and manage an on-premise infrastructure.
Instead of purchasing expensive IT services and products, cloud computing lets you rent these resources without large upfront costs. This allows you to quickly access the cloud services you need and pay only for what you use.
How Cloud Computing Can Help Your Organization?
Cloud computing has become essential for advanced application development and research. It provides scalable solutions without initial investment or outdated infrastructure. Let’s take a look at how cloud computing can help your business:
Infrastructure Scaling: Cloud computing enables you to scale your cloud infrastructure when your business needs become more demanding.
Resource Optimization: Cloud computing helps you optimize the storage and compute resources by providing exactly what you need and when you require it.
Reduced Costs: You can minimize your computing costs by reducing expensive physical hardware and maintenance expenses.
Faster Development Cycles: Cloud computing provides the latest tools and technologies, enabling you to build products and services quickly according to your requirements.
High-Performance: Cloud servers provide high-performance computing power, which helps you to complete the processing tasks in seconds.
Large Storage: Cloud computing offers vast storage capacity that enables you to efficiently manage large amounts of data.
Global Collaboration: With the support of the global or mobile team, you can access computing resources from anywhere in the world, making collaboration easier.
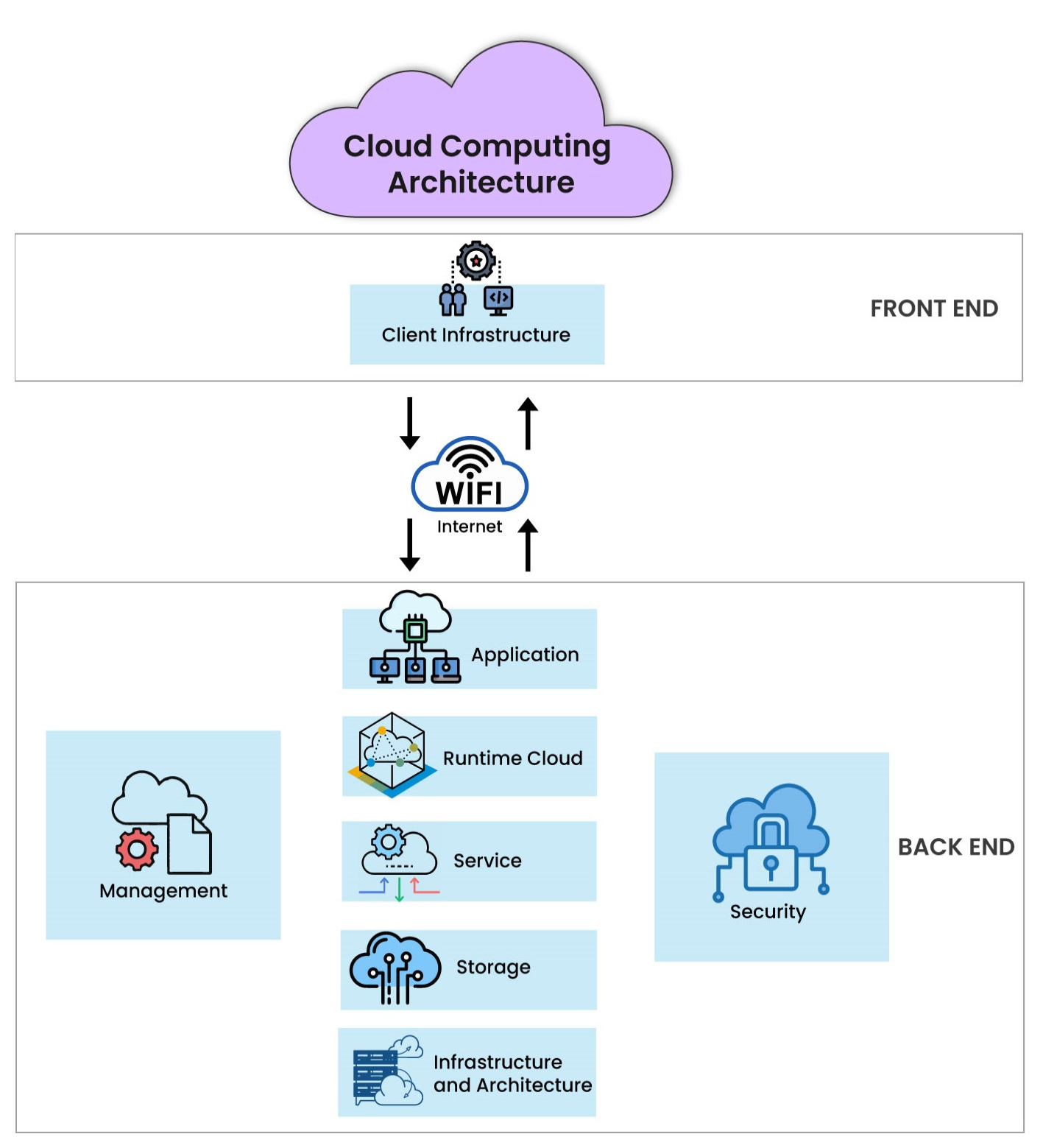
Cloud Computing Architecture
Cloud computing architecture combines the strengths of Service-Oriented Architecture (SOA) and Event-Driven Architecture (EDA). This hybrid design provides higher bandwidth, allowing you to access your data stored in the cloud from anywhere.
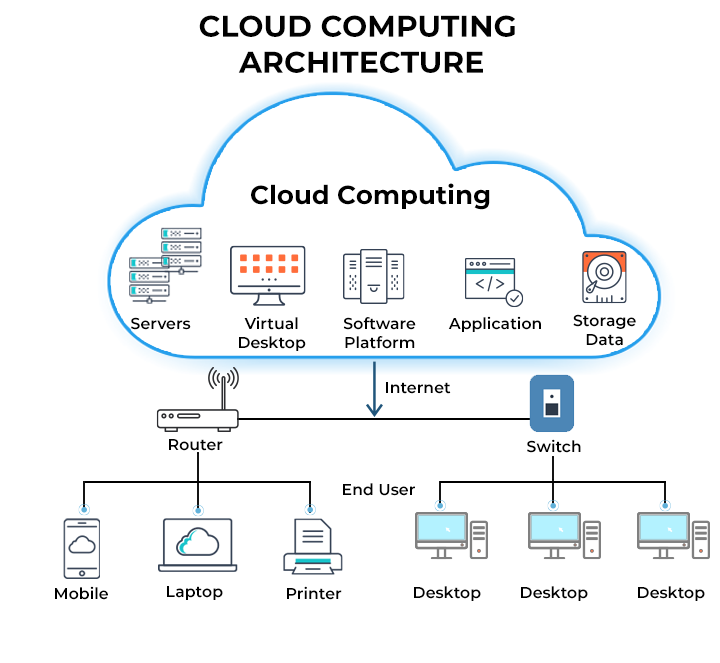
Here is the graphical representation of a cloud computing architecture:
As illustrated, cloud computing architecture is partitioned into two parts:
Front-End Cloud Architecture
Front-end architecture is one of the major components of the cloud computing system that allows you to access cloud computing services. It is a client infrastructure comprising various web applications, user interfaces, local networks, and mobile devices. You can send requests through the front-end system over the Internet, which lets you connect with the back-end architecture for data storage and processing.
Back-end Cloud Architecture
The cloud service provider handles the back-end architecture to manage and administer all the resources required for cloud services. It includes middleware, which connects the front-end interfaces to the back-end infrastructure. The provider also uses middleware to improve the front end’s functionality and safeguard the data. Back-end architecture includes different subcomponents to deliver cloud services to users easily. Let’s discuss about each of them:
Application: An application can be a software or platform that you need to access the cloud services.
Runtime Cloud: Runtime cloud is a virtual environment that serves as an operating system, enabling the back-end system to run programs simultaneously.
Service: A service component that helps the back-end interface manage each operation that executes on the cloud.
Storage: A component that provides a scalable way to store and handle data in the cloud.
Infrastructure: Cloud infrastructure includes hardware and software resources, such as servers, networking, or databases, needed to provide on-demand computing services via the Internet.
Management: A component that helps manage all the back-end components and establish the connection between front-end and back-end systems.
Security: Security is integrated at the front-end and back-end architecture to prevent data loss and secure the entire cloud computing system.
Top Three Cloud Computing Service Providers
Amazon Web Services (AWS)
AWS, a subsidiary of Amazon, is one of the most popular cloud computing platforms. Statista, a statistical portal for market data, reported that around 48% of professional software was developed using AWS as of 2024.
AWS provides over 200 fully featured services, including storage, networking, compute, development tools, databases, IoT, security, analytics, and enterprise applications. This makes AWS an all-in-one solution for businesses of any size on a pay-as-you-go basis.
Microsoft Azure
Microsoft Azure is ranked as the second most popular cloud computing solution by Statista, right after AWS. It provides 200+ scalable cloud services to help you develop and manage applications through Microsoft’s global network of data centers.
Azure allows you to connect with Microsoft products like SQL Server or Visual Studio, making it a great choice for businesses heavily invested in Microsoft technologies.
Google Cloud Platform (GCP)
GCP is a cloud platform launched by Google with a suite of computing services that help you with everything from data management to app development. It focuses on big data analytics, machine learning, and generative AI using the same infrastructure that powers Google services like Search, Gmail, and YouTube.
Once you build your applications, you can automatically deploy and scale them efficiently using the fully automated Google Kubernetes Engine. GCP’s Google Security Operations (SecOps) also helps you secure your applications from threats faster.
Types of Cloud Deployment Models
Cloud deployment models help you understand how cloud services are available to users and organizations. Here are four types of cloud models:
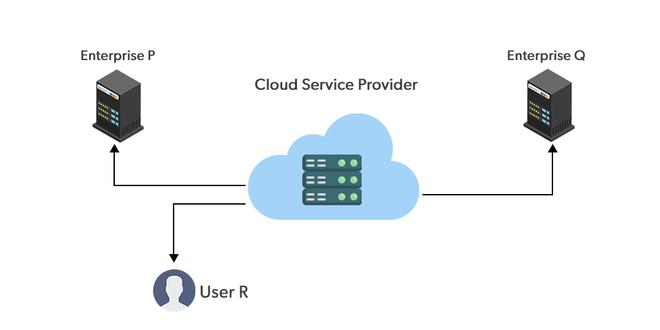
Public Cloud
Third-party cloud service providers such as AWS, Azure, and GCP own and operate public clouds. These providers offer scalable resources and services over the Internet to multiple clients without significant upfront investment. However, public clouds can sometimes present few security risks as they are open to everyone. By properly configuring the cloud settings and implementing strong security measures, you can still protect your data and maintain a secure environment.
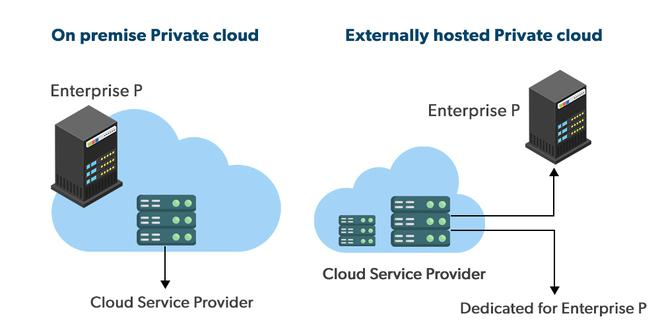
Private Cloud
In a private cloud, only a single user or organization can use the entire environment. It can be hosted on-premises or through a third-party provider but does not share resources with anyone else. A private cloud is set up in a secure environment with strong firewalls and authentication. Unlike public clouds, private clouds can help users customize resources to meet their specific demands.
Hybrid Cloud
Hybrid clouds allow you to combine the benefits of public and private cloud environments. This enables you to deploy your app on a secure platform and use the public cloud to save costs. With a hybrid solution, your organization can easily move data and applications across different combinations of cloud models. It helps your business to choose the best option you need at the moment. However, it is difficult to maintain as it involves both public and private clouds.
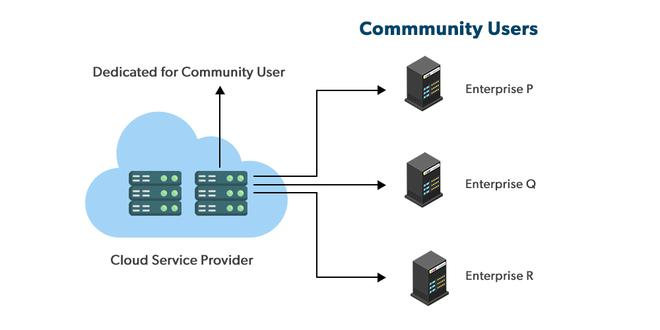
Community Cloud
The community cloud is similar to the public cloud. However, it is only available to a limited number of users or organizations with the same goals and needs. This cloud model can be managed and hosted either by a community or by a third-party provider. Since data and resources are shared among different organizations, changes made by one organization can affect others. As a result, the community cloud is limited in customization.
Types of Cloud Computing Services
Cloud computing provides three cloud services, each with different levels of control and flexibility. Choose one that best suits your business requirements.
Infrastructure as a Service (IaaS)
IaaS offers resources and services such as virtual machines, storage, networks, and more required for a cloud IT infrastructure over the Internet. It provides full management control over the operating systems, applications, and storage configurations, just like your own on-premise data center.
An example of IaaS is AWS EC2 (Elastic Cloud Compute). It allows you to rent virtual servers to run your large-scale applications instead of purchasing expensive physical hardware. You can even scale the server during peak traffic times.
Platform as a Service (PaaS)
PaaS provides a platform with built-in development platforms and tools to help you build, test, and deploy your applications. It streamlines the development process without worrying about patching, resource allocation, software maintenance, or other server administration routines.
Microsoft Azure App Service is a PaaS solution that lets you quickly develop websites, mobile apps, and APIs using different programming languages. Using such solutions, your development teams can collaborate on building without managing the underlying infrastructure.
Software as a Service (SaaS)
SaaS vendors deliver you software applications over the Internet on a subscription basis. You can access these applications via a web browser, eliminating the need to install the service and understand how it is maintained. As a result, you can reduce IT overhead and ensure you have access to the latest software versions without manual updates with SaaS solutions.
Google Workspace is a popular SaaS offering that provides tools like Gmail, Docs, Drive, and more. With it, you can collaborate in real-time without maintaining the operating systems on which the SaaS application is running.
How Cloud Computing Works?
In the previous sections, you explored cloud service providers, deployment models they used, and primary services they offer. Let’s now look at how cloud computing works:
Initially, you must log in to a cloud platform like AWS, Azure, or Google Cloud Platform through a front-end interface like a web browser or mobile app.
You can send a request to the cloud service provider to access services like storage, networking, or computing to load data or build and run applications.
The cloud provider’s remote servers receive your request and process it to grant you access to the requested resources.
If you want to handle large-scale needs, cloud infrastructure can scale dynamically to accommodate the increased demand.
Throughout the process, the cloud provider continuously monitors and manages the resources.
Finally, you must pay for the services you use, either monthly or annually, depending on your provider and subscription plan.
Benefits of Cloud Computing
Greater Efficiency: You can quickly build new applications and deploy them into production without heavy infrastructure management.
Improved Strategic Value: Cloud providers stay updated with the latest innovations, helping you remain competitive and achieve a better return on investment rather than purchasing a soon-to-be outdated technology.
Security: Cloud security is considered stronger than on-premise data centers due to the robust security measures implemented by cloud providers.
Increased Speed: With cloud computing, your organization can access enterprise applications over the Internet in minutes. As a result, you may not need to wait a longer time for the IT team to respond and set up an on-premise infrastructure.
Enhanced Scalability: Cloud computing provides self-service provisioning, allowing you to scale capacity up or down based on traffic fluctuations. This eliminates purchasing excess capacity that remains unused.
Limitations of Cloud Computing
Internet Dependency: Accessing cloud services requires a stable internet connection and compatible devices. Using public Wi-Fi can also lead to security risks if appropriate measures are not taken.
Financial Commitment: Unlike public cloud providers’ pay-as-you-go pricing model, private and hybrid cloud solutions require significant upfront investments and ongoing maintenance costs. They may require you to commit to monthly or annual subscription fees for certain services, which can lead to more expenses in the long run.
Downtime: Outages are a common challenge for cloud users. It results from technical glitches at the cloud service provider’s back-end servers due to the high volume of users.
Cloud Computing Use Cases
Big Data Analytics: The cloud provides the unlimited computing power and storage resources required for big data analytics. This helps your business gain valuable insights in real-time without investing in expensive on-premise hardware.
Data Storage: Cloud services offer secure, scalable, and cost-effective storage options for your organization. Whether you are storing real-time data, backups, or archives, cloud storage ensures quick access and efficient management.
Quick Application Development: Cloud platforms accelerate application building, testing, and deployment by providing on-demand development tools and environments.
Disaster Recovery: Cloud computing provides affordable disaster recovery solutions by storing backups in multiple regions. This ensures business continuity with minimal downtime in case of data loss or system failure.
Five Cloud Computing Trends
Here are some of the evolving trends in the cloud computing industry:
1. Enhanced AI and Machine Learning
AWS is actively advancing its AI and machine learning technology with innovations like the AWS DeepLens camera. DeepLens is a deep learning-enabled video camera that enables you to build and deploy machine learning models directly within your applications. As a result, you can quickly recognize objects, activities, and faces in real-time.
Google is also investing in machine learning applications. Google Lens is one of its most cutting-edge technologies, which allows you to point your camera at objects to gather more information. This feature is expected to expand into other Google products soon. Similarly, many companies like IBM and Microsoft are continuously enhancing their cloud product offerings by integrating AI and machine learning capabilities.
2. Improved Data Management
The cloud is evolving to help your organization store and analyze data in ultra-larger, distributed computing environments in the future. Instead of storing large volumes of data in databases, major companies are already utilizing Graphics Processing Units (GPUs) to enable massive parallel computing as data grows. Your organization can introduce new computer architectures to reshape how you compute, store, and utilize data in the cloud.
3. Favoring Multi-Cloud and Hybrid Solutions
Multi-cloud and hybrid cloud platforms are becoming popular as modern businesses want to spread their workflows across different cloud platforms and their servers. This allows every organization, including yours, to use the best features of various cloud providers while controlling the business data and applications. By using both public and private clouds, your businesses can be more flexible, improve performance, and remain safe from service outages.
4. Opting for Serverless Computing
In serverless computing, the cloud provider helps you to automate infrastructure management activities, such as scaling, provisioning, and maintenance. You only need to focus on writing code and developing business logic to deploy your applications. With serverless computing, you only pay for the resources consumed during application execution, eliminating the costs for idle capacity. These cloud computing services are more suitable for building event-driven architectures or microservices.
5. Concept of Citizen Developers
A key trend in cloud computing is the rise of the concept of citizen developers. These concepts ensure that non-technical users can connect with APIs and automate tasks using tools like If This Then That (IFTTT). IFTTT is a web-based service that helps you create simple conditional statements to automate workflows across different applications and services without extensive programming knowledge. Google, AWS, and Microsoft are expected to launch user-friendly tools that allow technical and non-technical users to build complex applications using drag-and-drop interfaces.
Final Thoughts
As you explore cloud computing, you now have a clear understanding of how it can change the way many organizations, including yours, work. By understanding its simple architecture, various cloud computing models, and top cloud providers, you can efficiently use cloud services for your business enhancements.
Whether you want to reduce costs, increase efficiency, or build innovations, cloud computing offers the tools and flexibility to help your organization succeed in competitive markets. Despite a few challenges, new cloud computing trends like advanced genAI and serverless computing will transform your business in the future.
FAQs
What should I consider before moving to the cloud?
Before moving to the cloud, consider your organization’s specific needs, including scalability, data security, and compliance requirements. Evaluate the costs, integration challenges, and how the cloud aligns with your long-term goals.
Can I integrate my existing infrastructure with cloud services?
Yes, you can integrate existing infrastructure with cloud services using a hybrid deployment model. This allows you to maintain some workloads on-premises while utilizing the cloud’s benefits.
How does billing work in cloud computing?
Cloud computing usually uses a pay-as-you-go model, where you are billed based on resource usage. Costs mainly depend on factors like storage, processing power, and data transfer.
With a significant increase in the generation of unstructured data, including text documents, images, audio, and video files, there is a need for effective data management. Traditional relational databases are mainly designed to handle structured data, leaving this option out for unstructured data. Vector databases are a more suitable choice, especially for various AI-based applications.
Let’s understand what a vector database is, its use cases, and the challenges associated with its use.
What is a Vector Database?
A vector database is a system that allows you to store and manage vector data, which is a mathematical representation of different data types. The data types can be audio, video, or text in the form of multidimensional arrays. While the representation changes the format, it retains the meaning of the original data.
Weaviate, Milvus, Pinecone, and Faiss are some examples of vector databases. These databases are useful in fields such as natural language processing (NLP), fraud detection, image recognition, and recommendation systems. You can also utilize vector databases for LLMs (Large Language Models) to optimize outcomes.
How Does Vector Database Work?
To understand how a vector database works, you need to know the concept of vector embeddings. These are data points arranged as arrays within a multidimensional vector space, which are typically generated through machine learning models. Depending upon the data type, different vector embeddings, such as sentence, document, or image embeddings, can be created.
The vector data points are represented in a multidimensional vector space. The dimensions of this vector space vary from tens to thousands and depend on the data type, such as video, audio, or image.
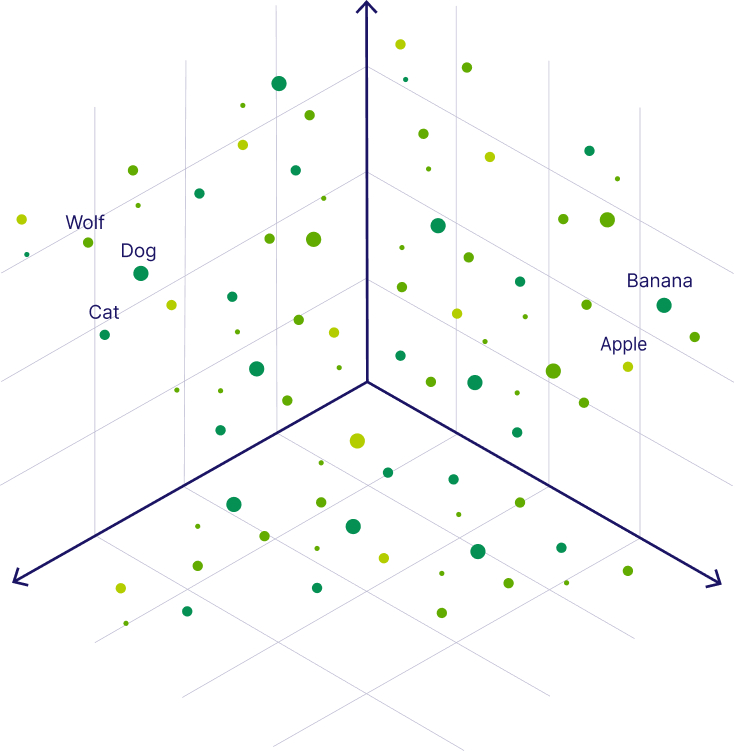
Consider an example of a vector space illustrated in the above image. Here, the data points ‘wolf’ and ‘dog’ are closer to each other as they come from the same family. The data point ‘cat’ might be slightly farther but still in proximity to ‘dog’ as it also comes under the animal category. On the other hand, data points ‘banana’ and ‘apple,’ while close to each other, are placed away from wolf, dog, or cat data points as they both belong to the fruits category.
When you execute queries in a vector database, it provides results by identifying the closest matches to the input query. For this, the database uses a specialized search technique called Approximate Nearest Neighbor (ANN) search. In this method, an algorithm finds data points very close to your input query point but not with exact precision.
The ANN algorithms facilitate the calculation of distance between vector embeddings and store similar vector data together in clusters through a process called vector indexing. This helps in faster data retrieval with efficient navigation of the multidimensional vector space.
Top 5 Popular Vector Databases
Now that we know how a vector database works, let’s look at some of the popular vector databases.
Chroma is an AI-based open-source vector database that allows you to generate and store vector embeddings. You can integrate it with LLMs and use the stored vector embeddings along with metadata for effective semantic searches. Chroma provides native support for models like HuggingFace and OpenAI and is also compatible with various LLM frameworks like LangChain.
Metadata filtering, full-text search, multi-modal retrieval and document storage are some of the other features offered by Chroma. It also supports SDKs for different programming languages, including Python, Ruby, JavaScript, PHP, and Java, to help you develop high-performing AI applications.
Pinecone is a fully managed, cloud-based vector database used extensively in NLP, recommendation systems, and computer vision. It eliminates the need for infrastructure maintenance and is highly scalable, allowing you to manage large volumes of vector data effectively.
Pinecone supports SDKs for programming languages such as Python, Java, Node.js, and Go. Using these SDKs, you can easily access the Pinecone API and use the API key to initialize the client application. After this, you can create indexes and write vector data records using the upsert operation.
The stored embeddings can be queried using similarity metrics such as Euclidean distance, cosine similarity, or dot product similarity. These metrics should match those used to train your embedding model for maintaining effectiveness and accuracy of search results.
Weaviate is a vector database—open-source and AI-native—that can store vectors as well as objects, allowing you to perform vector search along with structural filtering. It facilitates semantic search, classification, and question-answer extraction.
The database enables you to retrieve data at a very high speed, with a search time of less than 100ms. You can use its RESTful API endpoints to add and retrieve data to Weaviate. Apart from this, the GraphQL interface provides a flexible way to work with data. Weaviate also offers various modules for vectorization, extending the database’s capabilities with additional functionality.
4. Faiss
Facebook AI Similarity Search (Faiss) is an open-source library that provides efficient search and clustering of large-scale vector data. The AI research team at Meta developed this library, which offers nearest-neighbor search capabilities for billion-scale datasets.
With Faiss, you can search vector data at speeds 8.5x faster than many other high-performance databases because of the k-selection algorithm on GPU architectures. To optimize search performance further, Faiss allows you to evaluate and tune parameters related to vector indexing.
Qdrant is an AI-native vector database and semantic search engine that helps you extract meaningful information from unstructured data. It supports additional data structures known as payloads, which facilitate optimized search performance by allowing you to store extra information with vector data. With the help of these payloads and suitable API, Qdrant offers a production-ready service to help you store, search, and manage vector data points.
For effective resource usage, Qdrant supports scalar quantization, a data compression technique to convert floating data points into integers. This results in 75% less memory consumption. You can also convert integer data points back to float, but with a small precision loss.
Use Cases of Vector Database
With the advancement of GenAI applications, there has been a significant rise in the use of vector databases. Here are some prominent use cases of vector dbs:
Natural Language Processing
Vector databases are integral to NLP tasks like semantic search, sentiment analysis, and summarization. It includes converting the words, phrases, or sentences in the textual data into vector embeddings and storing in the vector databases.
Anomaly and Fraud Detection
You can use vector databases for fraud detection. It allows you to store transaction data as vector embeddings. In case of transaction anomalies, a similarity search in the vector space can help quickly identify discrepancies; there is a distance between anomalous transaction data points and the normal data points in vector space. This facilitates rapid responses to potential fraud.
Image and Video Recognition
Vector databases can help you perform similarity searches on a large collection of images and videos. Deep learning models enable you to convert images or videos into high-dimensional vector embeddings that you can store in vector databases. When you upload an image or video in the application, its embeddings are compared to those stored in a vector database, giving you visually similar content as output.
Customer Segmentation
You can use vector databases on e-commerce platforms to segment customers based on their purchase behavior or browsing patterns. The vector database allows you to store embeddings of customer data, and with the help of clustering algorithms, you can identify groups with similar behavior. This helps in developing a targeted marketing strategy.
Streaming Services
Vector databases are useful for providing recommendations and personalized content delivery in streaming platforms. These platforms utilize the vector embeddings of user interaction and preferences data to understand and monitor user behavior. The vector database facilitates conducting similarity searches to find content that is most aligned with your preferences for an enhanced viewing experience.
Challenges You May Face While Using Vector Databases
While vector databases are highly functional data systems, they require high technical expertise, and managing vector embeddings can be complex. Here are some of the challenges that you may encounter while using vector dbs:
Learning Curve
It can be challenging to understand vector database operations, such as similarity measures and optimization techniques, without a strong mathematical background. You must also familiarize yourself with the functioning of machine learning models and algorithms to know how various data points are converted into vector embeddings.
Data Complexity
As the dimensionality of data increases, the space between clusters in high-dimensional vector spaces can result in increased data sparsity or latency issues. The complexity of storing and querying vector data also increases with the rise in data volumes.
Approximate Results
Vector databases support ANN for faster data searching and querying. However, prioritizing speed over precision often leads to less accurate results. In high-dimensional vector space, the data sparsity further degrades the accuracy of these results. This can be detrimental in applications such as medical imaging or fraud detection, where precision is critical.
Operational Costs
Maintaining vector databases can be costly, especially for higher data loads. You have to invest in software tools, hardware, and expert human resources to utilize these databases efficiently. This can be expensive and, if not implemented properly, can lead to unnecessary expenditure.
Summing It Up
With the advancements in AI, the usage of vector databases is bound to increase for effective data management. Techniques such as quantization and pruning can enhance these databases’ ability to handle large volumes of data efficiently. As a result, the development of better-performing and high-dimensional vector databases is expected in the future.
Some popular vector databases include Chroma, Pinecone, Weaviate, Faiss, and Qdrant. Such databases can contribute to use cases such as NLP, anomaly and fraud detection, customer segmentation, and streaming services, among others. However, from a steep learning curve and data complexity to higher operational costs, you need to be aware of the challenges associated with vector databases.
FAQs
How to choose a vector database?
To choose a suitable vector database, you should first identify your specific use cases, scalability, and performance requirements. You should also evaluate the availability of documentation and the ease with which the vector store integrates with your existing infrastructure.
What are the best practices for using vector databases?
To effectively use vector databases, you should choose the appropriate indexing technique for accuracy and speed. For better results, ensure clean, high-quality datasets. You must also regularly monitor and fine-tune the performance of the applications using the vector database and make necessary adjustments before public deployment.
Which vector databases are best for LLMs?
Several vector databases for LLMs offer better semantic search capabilities. Some of the popular ones are Azure AI search, Chroma, Pinecone, and Weaviate. Depending on your budget and infrastructure resources, you can choose any of these vector stores to get optimal results for your LLM queries.
A radio station in Poland, OFF Radio Kraków, has sparked controversy by replacing its journalists with AI-generated presenters. The station described it as Poland’s first experiment where journalists are virtual avatars created by AI.
The station’s three AI presenters are designed to connect with younger audiences by discussing topics related to culture, art, and social issues, including LGBTQ+ concerns. Marcin Pulit, the station’s head, wrote this change will help explore whether AI presents more of an opportunity or threat to radio, media, and journalism.
Mateusz Demski, a journalist and film critic who previously worked at the station, strongly opposed the decision. He published an open letter in which he mentioned this incident as a dangerous precedent for a world where machines would replace experienced employees. Over 23,000 people have signed the petition and extended their unwavering support to the journalist.
Demski further said that he received hundreds of calls from young people who disapproved of participating in such an experiment. However, Pulit defended the broadcaster’s position by stating that the journalists didn’t lose their jobs to AI but were fired due to near-zero listenership.
The radio station even aired an interview by an AI avatar that impersonated Wisława Szymborska, a Nobel Prize winner in Literature who died in 2012. Michał Rusinek, the president of the Wisława Szymborska Foundation, confirmed with broadcaster TVN that he agreed to let the station use the poet’s name. He said the poet had a great sense of humor and would have appreciated it.
The incident also caught the Polish Government’s attention, and Krzysztof Gawkowski, the Deputy Prime Minister and Minister of Digital Affairs, took to X to voice his concerns. He wrote that despite his enthusiasm for AI development, he believes AI must be used for people, not against them. He mentioned that he read Demski’s letter and that there is a need to establish legislation to regulate AI.
On Tuesday, October 22nd, 2024, Qualcomm announced a multi-year tech collaboration with Alphabet to develop a standardized framework for software-defined vehicles and generative AI-enabled experience.
The new partnership is supposed to foster advanced digital transformation in vehicles that support AI features to enhance the customer experience. By integrating Snapdragon Digital Chassis and Google’s in-vehicle technology, this collaboration aims to empower automakers to innovate and accelerate new developments.
This framework will leverage Google AI with Snapdragon heterogeneous edge AI system-on-chips (SoCs) and Qualcomm AI Hub. It will help automakers build AI-native features like enhanced map experience, intuitive voice assistants, and real-time updates to meet users’ needs.
Nakul Duggal, group general manager of automotive, industrial, and cloud at Qualcomm Technologies, Inc., stated, “We look forward to extending our work with Google to further advance automotive innovation and lead the go-to-market efforts leveraging our ecosystem of partners to enable a seamless development experience for our customers.”
The key elements of this revolutionizing collaboration will be genAI-enabled digital cockpit development and unified SDV car-to-cloud frameworks.
The digital cockpit is expected to have pre-integrated Android automotive operating system (AAOS) services, which provide customization, real-time driver updates, and responsive voice UI. The unified SDV car-to-cloud framework, on the other hand, will increase developer productivity while reducing the time to market for AAOS service.
Companies like the Mercedes Benz Group plan to use the Snapdragon Ride Elite chips in their future models. With such advancement in the automotive industry, Qualcomm and Google aim to simplify genAI integration with modern vehicles.
On October 22nd, 2024, Anthropic announced an enhanced version of Claude 3.5 Sonnet that can deliver better results than its predecessor. It also announced the release of a new model, Claude 3.5 Haiku, that matches the performance of Claude 3 Opus.
In this new Claude 3.5 Sonnet release, Anthropic offers users the capability to direct Claude to interact directly with the computer. It allows the automation of cursor movement, clicking buttons, and typing text.
Although still in the beta version, the computer use model efficiently performs functions like filling online forms by interacting with the spreadsheet on your computer. Anthropic has released this version so that users can interact with the model and provide feedback to improve performance.
The upgraded Sonnet 3.5 model has already shown significant improvements in various tasks and software benchmarks. Responses for SWE-bench Verified improved from 33.4% to 49.0%. On the other hand, TAU-bench results increased from 62.6% to 69.2% in retail and 36.0% to 46% in the advanced airline domain.
Early feedback from developers outlined a significant leap in the performance of AI-powered coding, with a 10% enhancement in logical reasoning.
With these improvements, the new model is being used by multiple renowned names, including Cognition, which uses the model for autonomous AI evaluations. The browse company is using this model to automate web-based AI workflows.
To ensure data safety, Anthropic partnered with the US AI Safety Institute (US AISI) and the UK Safety Institute (UK AISI). The US AISI and UK AISI conducted the pre-deployment testing of the new Claude 3.5 Sonnet model.
In hindsight, Claude 3.5 Haiku marks the release of the fastest model in the Anthropic ecosystem. For the same cost and slightly better speed than Claude 3, the 3.5 Haiku model offers enhanced results in almost every skill set.
With both models already available for use, Anthropic aims to revolutionize generative artificial intelligence and redefine modern processes by introducing automation.
Microsoft will allow its customers to build their own AI agents starting in November 2024. AI agents are autonomous software that can interpret their environment and perform various tasks without human intervention. This is the latest step taken by Microsoft to adopt AI technology amidst growing investor scrutiny over its AI investments.
To learn more about AI agentic workflow, read here.
Earlier this year, Dr Andrew Ng, founder of DeepLearning.AI, stated that AI agents will be the major component of AI development in 2024. Unlike chatbots, which require some human control, AI agents can make decisions and perform different functions autonomously without human interference.
Microsoft will allow users to use its Copilot Studio, a low-code tool with an AI-powered conversational interface to simplify building AI agents. It is based on several in-house AI models and those supported by OpenAI. Microsoft is also offering ten ready-to-use AI agents that can perform routine tasks such as managing supply chain, expense monitoring, or client communications.
As a demo, McKinsey and Co. created an AI agent that can manage client queries using interaction history. It also finds a consultant expert who can solve the specific queries and schedule a follow-up meeting.
Charles Lamanna, corporate vice president of business and industry Copilot at Microsoft, said, “The idea is that Copilot is the user interface for AI. Every employee will use it as a personalized AI agent that provides an interface to interact with numerous other AI agents.”
Microsoft is under pressure to show returns on the hefty investments made by investors for developing its AI services. The tech giant’s shares fell 2.8% in the September quarter, underperforming on the S&P index. However, they are still at 10% higher for the year.
On 22nd October 2024, Freeform, a metal 3D printing company, announced landing a $14M investment from AE Industrial Partners, LP, and NVIDIA’s NVentures. According to Freeform’s official LinkedIn page, this investment is a crucial step in scaling AI-driven metal 3D printing technology.
Developed by two former SpaceX engineers, Erik Palitsh (CEO) and TJ Ronacher (President), Freeform aims to set up a new frontier in manufacturing. With metal 3D printing technology, Freeform is taking a giant leap in industries like aerospace, energy, defense, and automotive.
In a recent conversation, Freeform CEO Erik Palitsh stated, “We saw the potential of metal printing. It has the potential to transform basically any industry that makes metal things. But adoption has been slow, and success has been marginal at best.”
In the upcoming project, Freeform’s objective is to utilize NVIDIA’s accelerated computing capabilities to build the world’s first AI-supported, autonomous metal 3D printing factory. This system will integrate process control, machine learning, and advanced sensing to manage manufacturing processes in real time.
By developing a hardware-accelerated computing platform with machine learning, Freeform has created a factory architecture that learns by building projects. The company’s AI-powered functionality makes it a strong contender in the manufacturing industry, providing it an advantage over other big names.
With the technological demands of the 21st century, Freeform is adopting new techniques to revolutionize the manufacturing sector where manual intervention still exists.
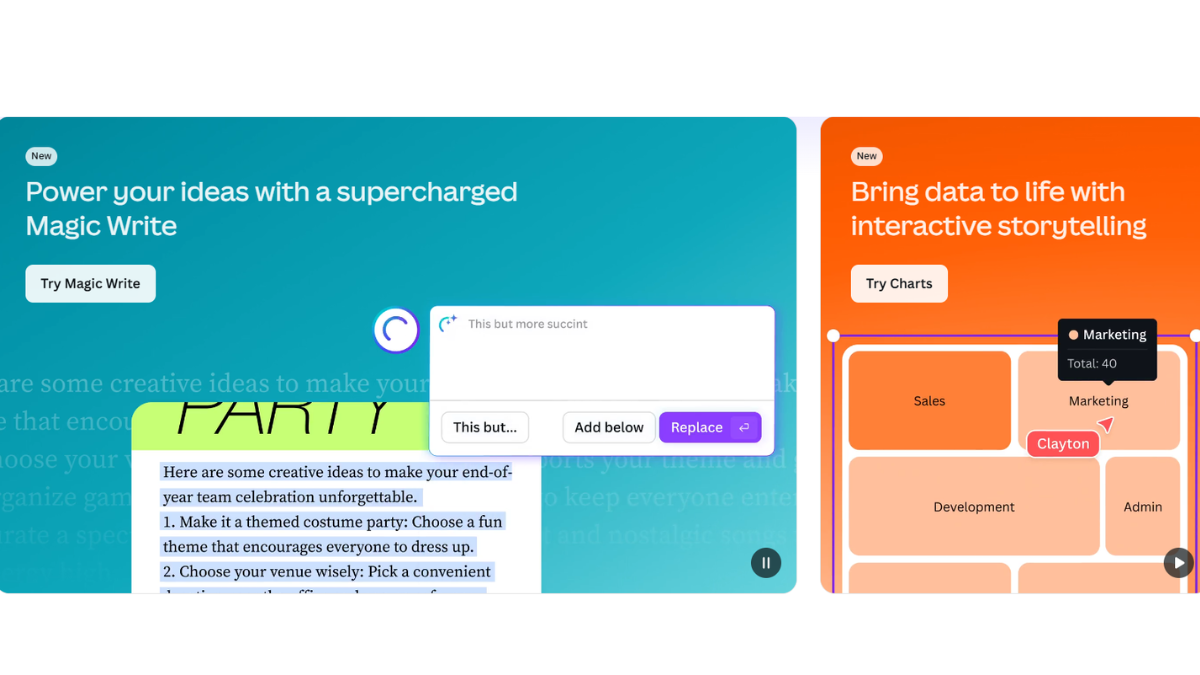
Canva has introduced its new robust AI image generator tool, Dream Lab. It is built on the Leonardo.AI Phoenix Model that allows you to create realistic images with unmatched precision. You can copy, download, or insert the images created by Dream Lab in your designs, simply as you do with other images on Canva.
To create an image with Dream Lab, you first have to describe what you want to make. Once you input your description, click on the Create button. The tool will process the information and provide an image that best matches your description. The more elaborate the content and instructions, the better the resulting image will be.
Dream Lab enables you to select from different styles when creating images. The presets include Cinematic, Dynamic, Sketch-Color, Stock Photo, Minimalist, Fashion, Portrait, Graphic Design, Pop Art, and more. These images will be created in JPG file format.
You can also choose the image size from the fame options, such as 1:1, 16:9, and 9:16. Once the image is created, Dream Lab allows you to make changes to it, similar to how you edit other images on Canva.
In addition to Dream Lab, Canva has introduced two other visual tools. The first is Magic Write, an AI text generator with enhanced contextual capabilities. OpenAI powers Magic Write and helps you quickly draft blog outlines, bio captions, and content ideas. The second tool is Try Charts, which allows you to create interactive charts.
Canva is continuously expanding its work kits and AI ecosystem, and the recent acquisition of Leonardo AI is a significant milestone. The acquisition allowed Canva to use Leonard’s image and video generation models in its product Dream Lab.
These steps taken by Canva are fostering a creative space where you can explore ideas and create more engaging and interactive content.
How can you be sure if the content you are consuming is authentic information or AI-generated? Google DeepMind has developed a solution for this. SynthID is a tool that can embed digital watermarks in AI-generated content, including images, text, videos, and audio. This further helps you identify whether the content is AI-generated. It is open-source and accessible through Hugging Face and Google’s Responsible GenAI Toolkit.
Here is a brief rundown of how SynthID works. LLMs utilize probability models to predict the next token (word or phrase) and assign potential outputs with probability scores. The higher the score, the higher is the chance of LLM choosing those words to generate text. This creates the pattern of scores for the model’s choice of words.
SynthID slightly alters the token probabilities generated by LLMs without compromising the accuracy and readability of the content. The combined patterns of the model’s probability score and the tweaked probability scores form the watermark. This unique identifier cannot be detected by humans.
While this watermarking tool for AI content can work on cropped and mildly paraphrased text, it has some limitations. SynthID finds it difficult to detect AI footprints if the content is too short, has factual information, is heavily rephrased, or is translated into a different language.
Despite these challenges, Google’s SynthID has immense potential. It can be used across several industries to improve people’s experience with AI. This tool can help protect creators’ rights related to intellectual property, verify the authenticity of news, and identify deepfakes used for malicious purposes. SynthID can enhance the trustworthiness, accountability, and transparency of digital content over the Internet. The report by Europol Innovation Lab details the potential harm AI-generated content can cause, such as document fraud, spreading misguided information, and misleading law enforcement. It highlights the dire need to establish new laws that regulate the usage of AI while ensuring ethical and responsible practices are implemented. Google has taken a step in this direction by developing SynthID.