

")
Generative AI models are trained on large datasets and use this data to generate outputs. However, training these models on finite and limited information isn’t enough to keep the model up-to-date, especially when answering domain-specific questions.
That’s where Retrieval-augmented generation (RAG) comes in. RAG enables these models to search for relevant information outside training data, ensuring they are better equipped to generate more accurate answers.
This article explores the benefits of RAG and how it improves the accuracy and relevance of the outputs generated by LLMs. Let’s get started!
What is Retrieval-Augmented Generation?

Retrieval-augmented generation (RAG) is an AI framework designed to enhance your applications by improving the accuracy and relevance of LLM-generated outputs. By integrating RAG, you can enable your LLM to retrieve relevant data from external sources such as databases, documents, or web content.
With access to up-to-date information, your model can generate contextually correct and reliable answers. Whether you’re building a customer support chatbot or research assistant, RAG ensures your AI delivers precise, timely, and relevant output.
Retrieval-Augmented Generation Architecture and Its Working
There is not one specific way to implement RAG within an LLM model. The core architecture depends on the particular use case, accessing specific external sources, and the model’s purpose. The following are the four basic foundational aspects that you can implement within your RAG architecture:
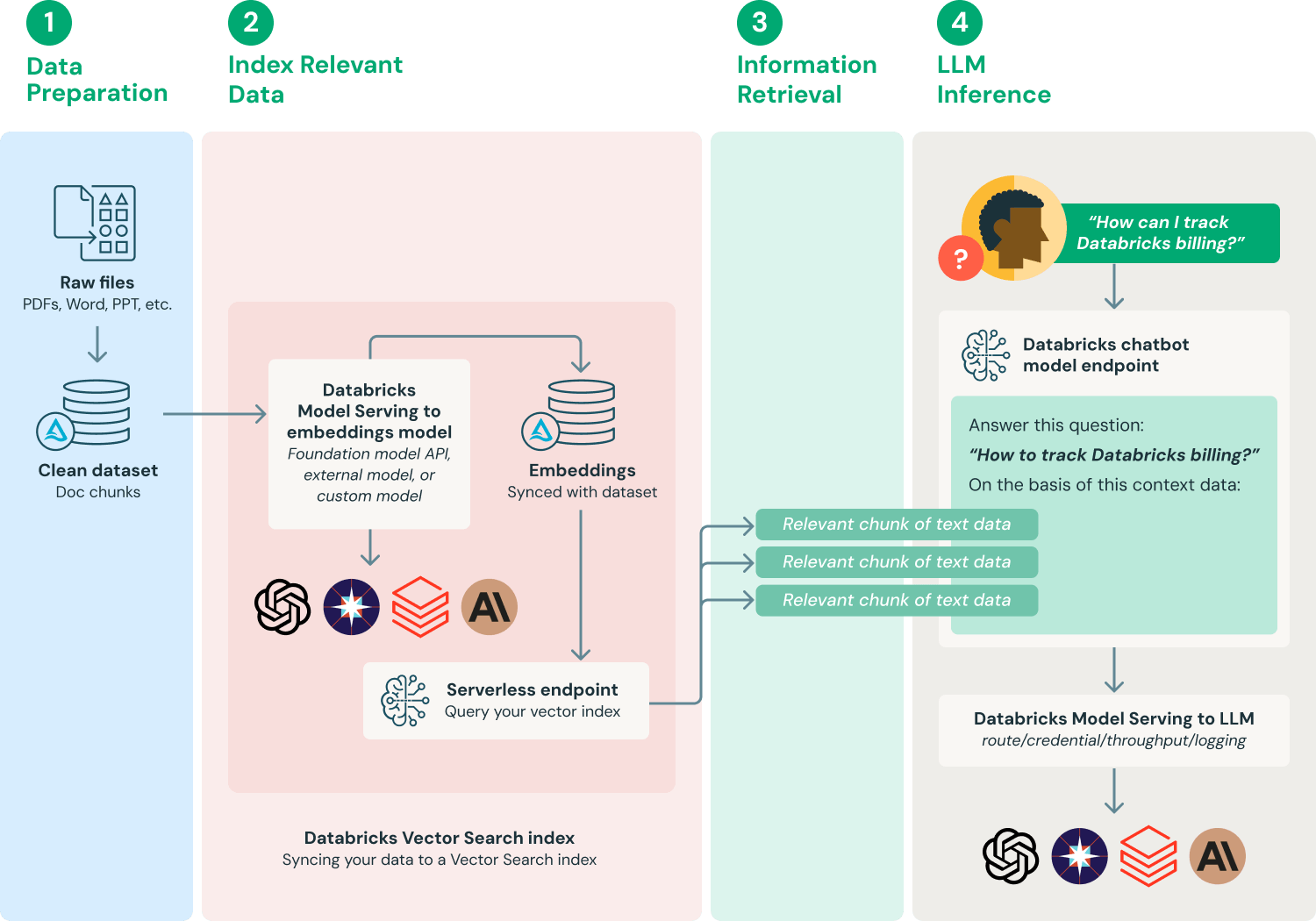
Data Preparation
The first component of the RAG architecture involves data collection, preprocessing, and chunking. Start by collecting data from internal sources such as databases, data lakes, documentation, or other reliable external sources. Once collected, clean and format the data and divide it into smaller chunks using methods like normalization or chunking. These chunks make it easier to embed the data in the model efficiently.
Indexing
Use a transformer model accessible through platforms like OpenAI and Hugging Face to transform the document chunks into dense vector representations called embeddings. These embeddings help to capture the semantic meaning of the text. Next, utilize a vector database to store the embeddings. These databases provide fast and efficient search capabilities.
Data Retrieval
When your LLM model processes a user query, it uses vector search to identify and extract information from the database. The vector search model matches the user’s input query with the stored embeddings, ensuring only the most contextually relevant data is retrieved.
LLM Inference
The final step of RAG architecture is to create a single accessible endpoint. Add components like prompt augmentation and query processing to enhance interaction. This endpoint serves as a connection between the LLM model and RAG, enabling the model to interact efficiently through a single point of contact.
What Are the Benefits of RAG?
Retrieval-augmented generation brings several benefits to your organization’s generative AI efforts. Some of these benefits include:
- Access to fresh information: RAG helps the LLMs maintain context relevance by enabling them to connect directly to external sources. These sources include social media feeds, news sites, or other frequently updated information sources that provide the latest data.
- Reduce Fabrication: Generative AI models sometimes ‘make up’ content when it doesn’t have enough context. RAG addresses this issue by allowing LLM to extract verified data from reliable sources before generating responses.
- Control Over Data: The Retrieval-Augmented generation provides flexibility in specifying the sources the LLM can refer to. This ensures the model produces responses that align with industry-specific knowledge or authoritative databases, giving control over the output.
- Improves Scope and Scalability: Instead of being limited to a static training set, RAG allows the LLM to retrieve information dynamically as needed. This enables the model to handle a wider variety of tasks, making it more versatile.
Difference between RAG and Semantic Search
Both RAG and Semantic Search approaches are used to improve the accuracy of the LLM but have slightly different frameworks. RAG uses semantic search as a part of its larger framework, while semantic search focuses on improving how to find relevant information.
Semantic search leverages natural language processing techniques to understand the context and meaning behind the words in a query. It helps to retrieve output that is more closely related to the intent of the question, even if some keywords differ. You can use semantic search in applications where only relevant document retrieval is needed, such as search engines, document indexing, or recommendation systems.
Example of Semantic Search
If you enter a query such as “What are the best apple varieties for baking pies?” a semantic search system first processes and interprets the meaning. Then, it will retrieve information about different varieties of apples suitable for baking.
RAG goes beyond semantic search. It first uses semantic search to retrieve relevant information from a database or document repository, then integrates this data into the LLMs prompt. This enables the LLM model to generate more accurate and contextually correct content.
Example of RAG
You can ask a chatbot powered by the RAG system, “What are the latest advancements in solar panel technology?”. Instead of relying on pre-trained data, the RAG will allow the chatbot to search across recent research articles, industry reports, or technical documents about solar panels. This extended search provides the chatbot LLM with additional data that can be used to generate a more accurate answer to your question.
What Are the Challenges of Retrieval-Augmented Generation?
RAG applications are being adopted widely in AI-driven customer service and support, content creation, and other fields. While RAG enhances the accuracy and relevance of responses, implementing and maintaining these applications comes with its own set of challenges.
- Maintaining Data Quality and Relevance: As your data sources expand, ensuring data quality and relevance becomes harder. You will need to implement mechanisms to filter out unreliable or outdated information. Without this, conflicting or irrelevant data might slip through, leading to responses that are either incorrect or out of context.
- Complex Integration: Integrating RAG with LLMs involves many steps, such as data preprocessing, embedding generation, and database management. Each step demands considerable resources to function, adding complexity to your system.
- Information Overload: You should maintain a delicate balance when providing contextual information to LLM. Feeding too much data into the RAG model can overwhelm it, leading to prompt overload. The data overload makes it harder for the model to process the information accurately.
- Cost of Infrastructure: Building and maintaining RAG systems can be costly. You need to manage infrastructure for storing, updating, and querying vector databases, along with the computational resources required to run the LLM. These costs can add up quickly if you are working on large-scale applications.
Retrieval-Augmented Generation Use Cases
The RAG framework significantly improves the capabilities of various natural language processing systems. Here are a few examples:
Content Summarization
The RAG framework contributes to generating concise and relevant summaries of long documents. It allows the summarization model to retrieve and attend to key pieces of text across the document, highlighting the most critical points in a condensed form.
For example, you can use RAG-powered tools like Gemini to process and summarize complex studies and technical reports. Gemini efficiently sifts through large amounts of text, identifies the core findings, and generates a clear and concise summary, saving time.
Information Retrieval
RAG models improve how information is found and used by making search results more accurate. Instead of just showing a list of web pages or documents, RAG combines the ability to search and retrieve information with the power to generate snippets.
For example, when you enter a search query, like ‘best ways to improve memory,’ a RAG-powered system doesn’t just show you a list of articles. It looks through a large pool of information, extracts the most relevant details, and then creates a short summary to answer your question directly.
Conversation AI Chatbots
RAG improves the responsiveness of conversational agents by enabling them to fetch relevant information from external sources in real-time. Instead of relying on static scripted responses, the interaction can feel more personalized and accurate.
For instance, you have probably interacted with a virtual assistant on an e-commerce platform while placing or canceling an order or when you wanted more details about the product. In this scenario, a RAG-powered virtual assistant instantly fetches up-to-date information about your recent orders, product specifications, or return policies. Using this information, the Chatbot generates and provides you with information relevant to your query, offering real-time assistance.
Conclusion
Retrieval-augmented generation represents a significant advancement in LLMs’ capabilities. It enables them to access and utilize external information sources. This integration allows your organization to improve the accuracy and relevance of AI-generated content while reducing misinformation or fabrication.
The benefits of RAG enhance the precision of responses and allow for dynamic and scalable applications across various fields, from healthcare to e-commerce. It is a pivotal step towards creating more intelligent and responsive AI systems that can adapt to the rapidly changing text landscape.
FAQs
Q. What Is the Difference Between the Generative Model and the Retrieval Model?
A retrieval-based model uses pre-written answers for the user queries, whereas the generative model answers user queries based on pre-training, natural language processing, and deep learning.
Q. What Is the Difference Between RAG and LLM?
LLMs are standalone Gen AI frameworks that respond to user queries using training data. RAG is a new framework that can be integrated with LLM. It enhances LLM’s ability to answer queries by accessing additional information in real-time.