At Computex 2021, NVIDIA unveiled Base Command™ Platform to help developers take artificial intelligence projects from prototypes to production. Base Command is a cloud-hosted development hub designed for optimizing workflows in enterprises to expedite the development process of AI-based projects.
According to NVIDIA, the software is designed for large-scale, multi-user and multi-team AI development workflows hosted either on premises or in the cloud. It enables numerous researchers and data scientists to simultaneously work on accelerated computing resources, helping enterprises maximize the productivity of both their expert developers and their valuable AI infrastructure.
Build for NVIDIA’s internal research team to integrate several AI-workflows, the Base Command Platform simplifies sharing resources through graphical user interfaces and command-line APIs.
NVIDIA Base Command Platform is currently available on a monthly subscription basis, which starts from $90,000. And later this year, Google Could would allow users to leverage Base Command Platform in its marketplace.
“World-class AI development requires powerful computing infrastructure, and making these resources accessible and attainable is essential to bringing AI to every company and their customers,” said Manuvir Das, head of Enterprise Computing at NVIDIA. “Deployed as a cloud-hosted solution with NVIDIA-accelerated computing, NVIDIA Base Command Platform reduces the complexity of managing AI workflows, so that data scientists and researchers can spend more time developing their AI projects and less time managing their machines.”
Udacity invites applications for its AWS machine learning scholarship program for enthusiasts who are looking to become machine learning engineers. Similar to other scholarship programs of Udacity, learners will have to complete the foundation course to stand a chance to get the scholarship — AWS Machine Learning Engineer Nanodegree program. However, after completion of the foundational course, we will have to take an assessment, which will allow Udacity to evaluate top performers for the AWS machine learning scholarship.
Based on the results of the assessment, a total of 425 learners will be selected for the Nanodegree program, where learners will learn advanced machine learning and gain a certificate on completion.
According to Udacity, all the learners applying for the foundational course would be accepted, thereby giving an opportunity to all the learners to showcase their learning ability to obtain the scholarship.
The foundational course includes topics like object-oriented programming skills, fundamentals of machine learning, and other AWS technologies like AWS DeepRacer, AWS DeepLens, and AWS DeepComposer. Learners will even get a certificate for completing the foundational course. There are other perks for participating and completing first — the first 150 learners to successfully complete the free course will receive AWS DeepLense devices and $35 AWS credits will be offered to the first 2500 applicants.
Both the foundation course and assessment should be completed by learners before October 11, 2021; the foundation course will be available for scholarship participants in the Udacity Classroom on June 28, 2021, and the winners will be announced on October 21, 2021. The second phase will start on October 25, 2021, and will end on January 25, 2022.
At Microsoft Build, Sam Altman, CEO of OpenAI, announces a $100 million fund for startups leveraging OpenAI for innovation. In a pre-recorded video, Altman said that the company, along with Microsoft and other partners, is willing to make big early bets in close to 10 companies with OpenAI Startup Fund.
OpenAI is looking for ambitious developers and entrepreneurs who are primarily into health care, climate change, and education. However, these are not the only sectors they would invest in, although those are their top priorities.
The OpenAI Startup Fund is not limited to just providing the necessary capital but also offering Microsoft Azure credits, support from their team, and early access to OpenAI’s future systems.
Microsoft’s partnership with OpenAI goes back to 2019, when the company invested $1 billion for OpenAI’s research and development in artificial intelligence. As a part of the investment, Microsoft also gained access to some of the intellectual property of OpenAI. Case in point, a year later, Microsoft obtained an exclusive license of GPT-3, a 175 billion parameters natural language model.
Since the early private beta access, GPT-3 is being used by thousands of developers to create innovative solutions. Earlier this week, Microsoft also announced the integration of GPT-3 for application development and is committed to equipping other products and services for enhancing the productivity of numerous tasks.
With the OpenAI Startup Fund, the company would push the solutions developed using GPT-3 in the market to showcase the advancement of their research. This would be unprecedented as a lot of research does not creep into the commercial market. OpenAI wants to capitalize on the hype and push solution build with GPT-3.
At Microsoft Build, the company announced that it is integrating GPT-3 into a wide range of applications. The company fined tuned GPT-3 to enable one of the most popular natural language processing models to generate Power Fx formulas. Power Apps Studio is a low-code platform, which allows people without coding knowledge to build business applications on the fly. Applications build using Power Apps works seamlessly on browsers and mobile devices, making it popular among a wide range of developers.
The new feature will be available in North America by the end of June, allowing users to leverage natural language for generating code/formulas. On providing input through natural language, the system will come up with a few options that can be selected by developers based on their requirements. Such features will expedite the development process of applications and will lead to an ultimate low-code experience.
“Using an advanced AI model like this can help our low-code tools become even more widely available to an even bigger audience by truly becoming what we call no code,” said Charles Lamanna, corporate vice president for Microsoft’s low code application platform.
Late last year, Microsoft obtained an exclusive license of GPT-3 from OpenAI after investing $1 billion in the company in 2019. After the release of the Azure-powered API of GPT-3 at a reasonable pricing, several developers have showcased the capability of GPT-3 in writing code, summarising email, generating synthetic text for articles, and more. Microsoft believes that GPT-3 will be capable of writing code to help the developers’ community in simplifying the application development process.
“We think there are a whole bunch more things that GPT-3 is capable of doing. It’s a foundational new technology that lights up a ton of new possibilities, and this is sort of that first light coming into production,” Eric Boyd, corporate vice president for Azure of Microsoft.
In the future, Microsoft will be integrating GPT-3 into its wide range of products to revolutionize the way developers or non-experts work with natural language processing.
If you go back the memory lane, specifically in the early 2010s, the shiny titles were taken by web designers and programmers. However, in the current situation, data scientists have taken a significant place.
The primary reason behind the demand for data science courses taking over other professionals is the need to make data-driven decisions. After all, to run a successful company in the 21st century, you need to have data that represents your target audience and the target market.
Over the last decade, a majority of companies have implemented data science to receive huge growth in the business and have found it helpful. Sure, this position has been engaging a lot of youngsters and mid-aged professionals.
So, if you wish to be a data scientist and want to learn this concept, this guide is curated just for you. Let’s understand how to start learning data science in this competitive environment.
What is Data Science?
Data science is the study that deals with the world of understanding, analyzing, and using modern tools and techniques to curate meaningful information and create protocols for making big business decisions.
To put it simply, data science is an interdisciplinary domain that uses scientific methods, procedures, algorithms, and systems to derive information and insights from structured and unstructured data and apply that knowledge and actionable data to a wide variety of application domains.
Data processing, deep learning, and big data are also some of the essential aspects of data science. Mainly, data science is used to make decisions and forecasts with the help of predictive causal analytics, prescriptive analytics, and machine learning.
Key Skills to Be a Data Scientist
To become a data scientist, you must master some basic skills in terms of analyzing, understanding, and collecting the data, such as:
You must know the tools used to analyze the database, such as Oracle® Database, MySQL®, Microsoft® SQL Server, and Teradata®.
You should know basic mathematical analysis, probability, and statistics. While statistics deal with the study and development of the data and calculation of the outcomes, the probability is the calculation of possibilities. Mathematical analysis deals with the basic differentiation, integrations, variables, measure, values, limits, vectors, odds, series, and so on.
Expertise in at least one programming language is the most important skill a data scientist must have. Data science relies on programming tools, which are the foundation of the discipline. You can consider learning R, Python, SAS, or any other language that meets the requirement.
Data wrangling is another requirement to become a data scientist as it helps in cleaning, manipulating, and organizing the data.
Being a data scientist, you must be able to understand the result. Data visualization is the integration of different data sets and generating a visual representation of the data using diagrams, charts, and graphs. You can also take up a data science and business analytics course in India to adept yourself with adequate knowledge.
How to start learning data science?
Data science is a complicated subject to choose as a career, but simultaneously a creative and flabbergasting field as well. To learn data science, you need to first understand and learn the key skills shared above. Once done, here is how you can begin learning data science.
As mentioned above, basic mathematics is required to enter the field of data science. As a result, learning the required mathematics concepts should be the first step. Complex equations, differentiation, integrations, calculus, programming, and database, are some important concepts for the same.
Above all the programming languages, you would have to go through one and learn to master your knowledge in data science. This field involves a lot of programming features, and that is the reason you must know any of the required programming languages. Python and R could be great choices, to begin with.
Once done with basic mathematics and a programming language, you need to move forward to learn the Pandas library. Understand what it is all about, how it works, its advantages, used resources, and more. Pandas library provides high-performance data frames that enable you to get easy access and understanding of the data. It simplifies the process and presents it in a tabular form. It includes various tools for reading and writing data, handling missing data, cleaning messy data, and many more.
Further, you will need to learn machine learning and practice the same. Machine learning is a complex field. Once you have completed the entire course, you must ensure that the practice is not missed at any cost.
Data Science Certificate
To become a data scientist, you would at least need a bachelor’s degree in data science or a computer-related field. Also, some of the careers require a master’s degree. Thus, you would have to cross-check before starting anything.
Project model certification, internship certification, and qualification certificates are among the additional certifications you will need. Apart from this, if you have graduated in a different field, you can pursue a diploma in any online platform as well. There are many short data science courses available online that you can pursue right away.
Current Scenario in India
The position of a data scientist has risen to become one of the most sought-after professions, ranking second only to that of a machine learning engineer, which is a profession that is closely related to that of a data scientist.
With emerging tech companies and educational institutions in India, data science is already booming. This has resulted in an increase in data science job openings. Such opportunities are not just in the private sector but the government as well, with majorly all of the organizations making digital transitions.
Moreover, in the current pandemic, data scientists emerge as a guide to shift business operations online by using big data, cloud computing, machine learning, and more advanced Artificial Intelligence (AI).
So far, data scientists have been able to make significant strides in client data processing, Robotic Process Automation (RPA), cybersecurity, banking, healthcare, manufacturing, logistical supply chain AI, retail, workplace connectivity, and e-commerce as a result of increased demand.
There are lots of opportunities in the private sector as well, where entry-level data scientists can earn around 5 lakhs rupees per annum and experienced data scientists can get more than 6 lakhs rupees per annum in India. According to a LinkedIn report 2020, data scientist jobs showed a growth rate of over 37% this year.
Current Scenario in Other Countries
There are six countries where data science expertise is in short supply. France is standing tall at the top of the list, with high demand for data science due to new startups that have emerged in recent years.
Germany is at the bottom of the list and can face a shortage of 3 million skilled workers by 2030, regardless of its dependability on technology, even with a small population. Other countries like Sweden, UK, Finland, Ireland are also facing this kind of problem.
The Bottom Line
Today, this field is considered to be a vast and emerging one for a person to grow and make their career in. In summary, data science is the science of analyzing data and solving big equations with modern techniques more efficiently. Apart from this, data science simplifies complex data into user-friendly data.
There are many institutes in India as well as across the world that are providing free beginner data science courses. To become a data scientist, mathematics is a plinth for it.
Moving further, some programming languages are a must to know if someone is willing to choose data science. The path to get your destination in this field is to get at least a degree or a diploma certificate in the field of computers.
Through Artificial Intelligence and automation, data science is poised to transform many industries, including health care, transportation, business, finance, and manufacturing.
Microsoft releases a library for PowerBI in Jupyter notebook to allow developers to leverage the power of one of the most widely used business analytics tools’ reports. For several years, Jupyter notebook has become the go-to tool for data scientists but creating reports from Matplotlib and Seaborn and other libraries is not as straightforward as one might think. What beats plotting with just drag and drop with analytics platforms like PowerBI, Qlik, and Tableau?
However, business analytics platforms are not highly popular with data scientists as several preprocessing of data is required to improve the quality and make information ready for visualizations. Although data visualization and report generation require numerous lines of code, they still rely on Jupyter notebooks; switching to a business analytics platform only to visualize is too much for an ask for data scientists.
In addition, machine learning practitioners prefer to showcase everything within Jupyter Notebooks as it is easier to have everything in one place.
During Microsoft Build, the company removed a major pain point of data scientists for visualization in Jupyter notebooks. Now, PowerBI analytics can be accessed with a new powerbiclient Python package. You can also find the Python package and associated TypeScript widget on GitHub.
You can install the package with:
pip install powerbiclient
The ability to bring PoweBI reports makes the workflow earlier for data scientists as they can collaborate with other developers with ease. All they have to do is import the reports developed by other professionals like data analysts or business analytics with PowerBI. Data scientists can focus more on the advanced work while easily importing the reports of others.
For reports in the Jupyter notebook, you have to authenticate PowerBI using Azure AD and then provide details of the workspace ID and report ID to embed. Eventually, they can load the report to the output cell.
from powerbiclient import Report, models
# Import the DeviceCodeLoginAuthentication class to authenticate against Power BI
from powerbiclient.authentication import DeviceCodeLoginAuthentication
# Initiate device authentication
device_auth = DeviceCodeLoginAuthentication()
group_id=""
report_id=""
report = Report(group_id=group_id, report_id=report_id, auth=device_auth)
report
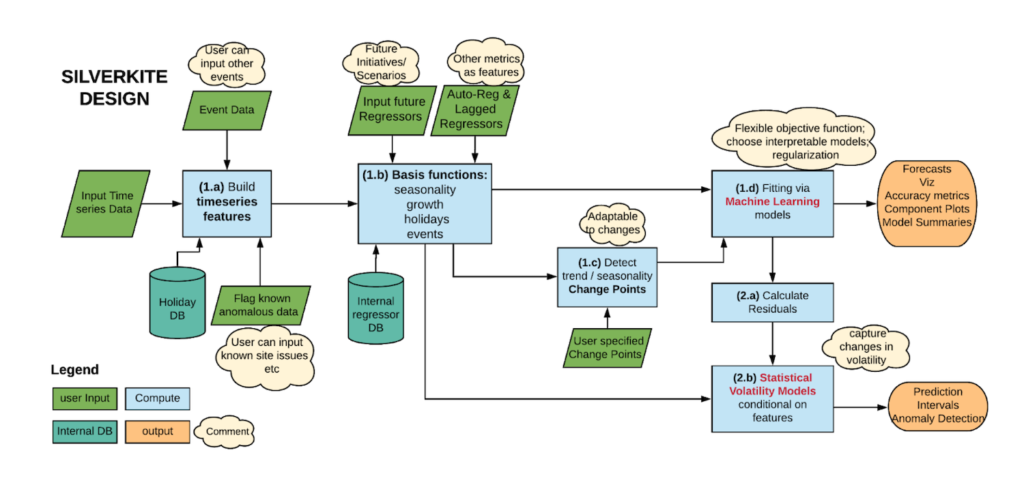
LinkedIn releases a time-series forecasting library, Greykite, to simplify prediction for data scientists. The primary forecasting algorithm used in this library is Silverkite, which automates the forecasting. LinkedIn developed GrekKite to support its team make effective decisions based on the time-series forecasting models. As the library also helps interpret outputs, it can become a go-to tool for most time-series forecasting. LinkedIn also had, last year, released a Fairness Toolkit for explainability in machine learning.
Over the years, LinkedIn has been using the Greykite library to provide sufficient infrastructure to handle peak traffic, set business targets, and optimize budget decisions.
Figure 1
According to LinkedIn, the Silverkite algorithm architecture is shown in Figure 1. The green parallelograms represent model inputs, and the orange ovals represent model outputs. The user provides the input time series and any known anomalies, events, regressors, or changepoint dates. The model returns forecasts, prediction intervals, and diagnostics.
Often, time-series models fail to consider seasonality and other non-frequent events, making it difficult to predict the outcome precisely. The is where LinkedIn’s Greykite library assists data scientists while working with seasonality and holidays. Users can fit their models based on the requirements and effectively work with changepoints and seasonality.
Since the models not only forecast but also provide exploratory plots, templates for tuning, and explainable forecasts, the Greykite library can be used for quick prototyping and deployment at scale.
To benchmark the performance of LinkedIn’s Greykite library, the researchers used several datasets — Peyton-Manning Dataset, Daily Australia Temperature Dataset, and Bejing PM2.5 Dataset. Silverkite outperformed Prophet, Facebook’s open-source algorithm for forecasting, ran four times faster than the latter.
Currently, the LinkedIn Greykite library also supports Prophet and will add more open-source algorithms to allow data scientists to work on diverse forecasting requirements.
Founders of DeepMind have for years shown interest in making DeepMind an independent artificial intelligence research center. The idea behind autonomy for DeepMind was to eliminate the control by a single entity over advanced artificial intelligence research. However, Alphabet has rejected the request for obtaining complete independence, according to sources.
Blue-chip companies have an eye for obtaining innovative artificial intelligence-based solutions to control groundbreaking technologies. A similar instance occurred when Microsoft exclusively licensed GPT-3 of OpenAI. The move was criticized by the likes of Elon Musk, who was one of the promoters of OpenAI.
But why shouldn’t companies that fund these research centers get control over how technological advancements are handed?
Bought by Google for $500 million in 2014, DeepMind has been doing groundbreaking research to further the development of artificial intelligence technology. More recently, DeepMind solved a 50-year-old grand challenge in biology by predicting protein structures. But every year, DeepMind incurs losses of around $600, and Alphabet in December 2020 waived off the debt of $1.5 billion. Supporting such a research center for nothing would mean a substantial long-term loss for promoters.
GPT-3, reportedly, cost $12 million for a single training run, making it cost-intensive for research centers. If a single research cost takes a sizable chunk of your funding, only a few big tech companies can invest in such projects. And tech companies can only do that because they are profit-oriented. Although this concentrates huge innovations to only a few companies, there are impactful innovations that further the development of artificial intelligence.
In addition, when big tech companies invest in these artificial intelligence research centers, they do it with specific terms and conditions that give them intellectual property rights; Microsoft has invested in OpenAI that allowed them to license GPT-3 exclusively. Blue-chip companies invest to gain profit. And so does Alphabet with DeepMind.
Sentiment analysis is one of the most common tasks performed by machine learning enthusiasts to understand the tone, opinions, and other sentiments. Over the years, sentimental analysis datasets were mostly created by extracting information from social media platforms. But due to an increase in unstructured data within organizations, companies have been actively leveraging natural language processing techniques to gain unique insights to make quick decisions. Today, with sentiment analysis, organizations are able to monitor brand and product sentiments among their customers. Consequently, working with datasets for sentiment analysis allows job seekers to gain expertise in handling unstructured data and help companies make effective decisions.
Sentiment analysis datasets are not limited to organizations; researchers have used rule-based models, automated models, and a combination of both to gauge out the sentiments behind texts for advancing the techniques in artificial intelligence. Neural network models are prevalent in the field for their sheer performance. But all these models need data to be trained, especially clean and well-annotated data. This is where benchmarks — sentiment analysis datasets — come in.
Amongst all the available datasets for sentimental analysis, here are some of the highest cited datasets:
1. General Language Understanding Evaluation (GLUE) Benchmark
Based on a paper on Multi-Task benchmarking and analysis for Natural Language Understanding (NLU), the GLUE sentiment analysis dataset offers a binary classification of sentiments — SST-2 along with eight other tasks for an NLU model. Current state-of-the-art models are trained and tested on it because of the variety of divergent tasks. Besides, a wide range of models can be evaluated for linguistic phenomena found in natural language.
Download: python download_glue_data.py --data_dir glue_data --tasks all
Source: Wang et al. GLUE
2. IMDb Movie Reviews
Hosted by Stanford, this beginner-friendly dataset is a binary sentiment analysis dataset consisting of 50,000 reviews from the Internet Movie Database (IMDb). A score above seven is labeled as positive, and a score below 4 is negative. The dataset for sentiment analysis contains the same number of positive and negative reviews with only 30 reviews per movie. Only highly polarizing reviews are considered.
DynaSent is an English-language-based positive, negative, and neutral dataset for sentiment analysis. It combines naturally occurring sentences with sentences created using the open-source Dynabench Platform, which facilitates human-and-model-in-the-loop dataset creation. DynaSent has a total of 121,634 sentences, each validated by five crowd workers. The dataset also contains the Stanford Sentiment Treebank dev set with labels.
4. MPQA Opinion Corpus (Multi-Perspective Question Answering)
The MPQA Opinion Corpus contains 535 news articles from a wide variety of news sources manually annotated for opinions, beliefs, emotions, sentiments, speculations, and more. The data should be strictly used for research and academic purpose only.
ReDial (Recommendation Dialogues) is an annotated dataset of dialogues for sentiment analysis, where users recommend movies to each other. The dataset consists of over 10,000 conversations centered around the theme of providing movie recommendations. There are several examples from the conversation for validation sets that can be useful before getting started.
Antonio Gulli’s corpus of news articles is a collection of more than 1 million news articles. The articles are curated from more than 2000 news sources by ComeToMyHead in more than one year. This data set can be used for non-commercial activities only. Also, you cannot re-distribute the datasets with a different name.
The paper From Amateurs to Connoisseurs: Modeling the Evolution of User Expertise through Online Reviews using Amazon Fine Foods is cited over 400 times. The Amazon Fine Foods dataset consists of ~5000,000 reviews up to October 2021 by 256,059 users. A total of 74,258 products have been reviewed, with a median number of words per review of 56.
Collected from Yelp’13 and IMDB, the SPOT sentiment analysis dataset contains 197 reviews that are annotated with segment-level polarity labels (positive/neutral/negative). Annotations have been gathered on two levels of granularity: Sentences and Elementary Discourse Units (EDUs). The dataset is ideal for evaluating methods that are focused on predicting sentiment on a fine-graned and segment-level basis.
Youtbean is a dataset created from closed captions of YouTube product review videos. It can be used for a wide range of sentimental analysis tasks like aspect extraction and sentiment classification. The data set was used for the paper ‘Mining fine-grained opinions on closed captions of YouTube videos with an attention-RNN.’
ReviewQA is a question-answering dataset proposed for sentiment analysis tasks based on hotel reviews. The dataset consists of questions that are linked to a set of relational understanding competencies of models. Each question comes with an associated type that characterizes the required competency.
Twitter datasets for sentimental analysis are one of the go-to data for sentiment analysis. iSarcasm is a dataset of tweets that are intended sarcasm for sentimental analysis. The data is labeled as either sarcastic or non_sarcastic. Sarcastic tweets are further labeled with the types of ironic speech — sarcasm, irony, satire, understatement, overstatement, and rhetorical questions.
PHINC is a parallel corpus of the 13,738 code-mixed English-Hindi sentences and their translation in English. According to researchers, the translations of sentences are manually annotated. This is one of the best datasets for sentimental analysis with a mixture of languages that is highly common in India.
XED is a multilingual fine-grained emotion dataset for sentimental analysis. The dataset consists of human-annotated Finnish (25k) and English sentences (30k), as well as projected annotations for 30 additional languages, providing new resources for many low-resource languages.
MultiSenti offers code-switched informal short text, for which a deep learning-based model can be trained for sentiment classification. The developers have provided a pre-trained model using word2vec, which can be accessed here.
PerSenT dataset contains crowd-sourced annotations of the sentiment expressed by the authors towards the main entities in news articles. The dataset also includes paragraph-level sentiment annotations to provide more fine-grained supervision for the task.
Sundar Pichai, CEO of Alphabet, demonstrates a breakthrough Conversational AI technology LaMDA (Language Model for Dialogue Applications. Like other language models, LaMDA is a Transformer-based neural network architecture model but are trained on dialogue. Since the release of Transformer by Google Research in 2017, several large-scale language models like GPT-3, DeBERT, and ROBERTA were released that have revolutionized the artificial intelligence industry. Today, language models can generate code, summarise articles, and more.
However, Transformer-based models can be heavily limited to specific tasks or require training the pre-build models with new information to effectively on a wide range of functions.
To make models topic/task agnostic, Google blazed a trail and trained LaMDA on dialogue, especially with chatbots. “During its training, it picked up on several of the nuances that distinguish open-ended conversation from other forms of language. One of those nuances is sensibleness. Basically: Does the response to a given conversational context make sense?;” mentions Google.
Google has witnessed a superior performance of LaMDA while asking a few questions. The video below demonstrates LaMDA’s capability with open-ended conversation.
LaMDA resulted from Google’s earlier research published in 2020 that showcased that Transformer-based language models can be trained on dialogue to improve use cases on numerous tasks. Since it is still early in the research, Google is committed to revolutionizing Conversational AI technologies.
For now, Google will be focusing on the sensibleness and satisfyingness of response from LaMDA to further enhance its responses.