


Recently, Microsoft unveiled, Tutel, an open-source library for constructing a Mixture of Experts (MoE) models – a type of large-scale artificial intelligence model. According to the company, Tutel, which is integrated into Meta’s PyTorch toolkit, will simplify the process of executing MoE more readily and efficiently.
The Mixture of Experts (MoE) architecture is a deep learning model architecture in which the computing cost is proportional to the number of parameters, allowing for simpler scalability. The MoEs are made up of little clusters of “neurons” that are only active when certain circumstances are met. The lower “layers” of the MoE model extract features, and experts are called upon to assess them. MoEs may be used to develop translation systems, with each expert cluster learning new grammatical rules or elements of speech.
In other words, MoE entails breaking down predictive modeling tasks into sub-tasks, training an expert model on each, creating a gating model that learns which expert to trust based on the expected input, and combining the predictions. A gating model is a neural network model used to understand each expert’s predictions and help determine which expert to trust for a particular input. This is achieved by finding which expert gives the largest output or confidence provided by the gating network.
Although the approach was developed with neural network specialists and gating models in mind, it can be used for any form of models. As a result, it resembles stacked generalization and falls within the meta-learning category of ensemble learning approaches. By substituting a single global model with a weighted sum of local models, the accuracy of a function approximation is improved in MoE.
According to Microsoft, currently, MoE is the only approach demonstrated to scale deep learning models to trillions of parameters. This implies it has the potential to pave the way for models that can learn even more information and power computer vision, speech recognition, natural language processing, and machine translation systems, among others, that can help individuals and institutions in new ways.
Microsoft is particularly interested in MoE because it makes effective use of hardware. Here, only those experts are called upon in case an issue arises that requires their specialism, while the remainder of the model waits in silence for their turn, thereby increasing efficiency.
Furthermore, when compared to other forms of model architecture, artificial intelligence models MoEs provide a substantial number of plus points. They may respond to changes in a unique way, allowing the model to display a broader range of behaviors. The data may originate from many places, and the model only takes a few professionals to run – even a large model only requires a small number of computing resources.
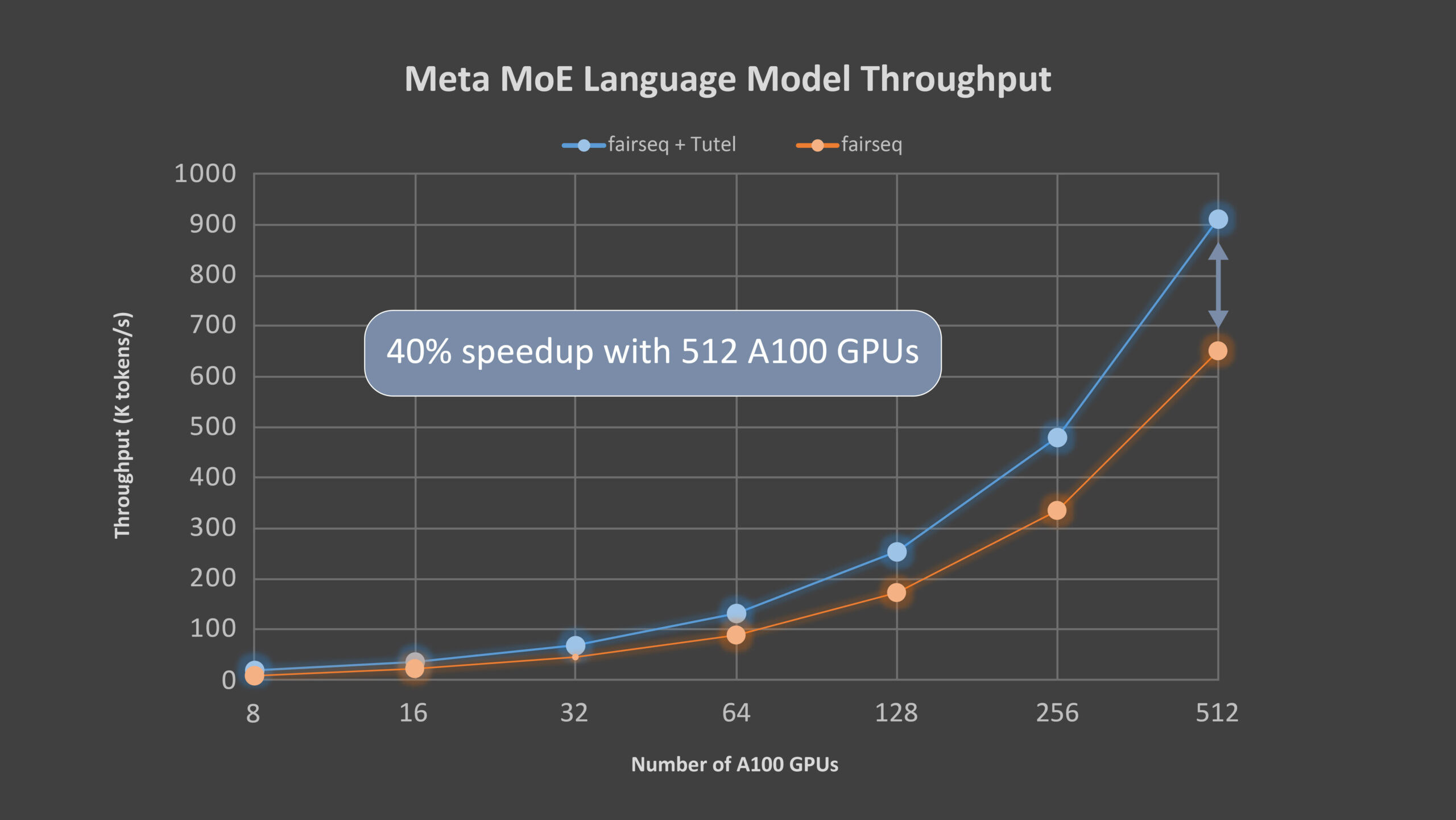
Microsoft’s Tutel primarily focuses on MoE-specific calculation enhancements. The library is designed specifically for Microsoft’s new Azure NDm A100 v4 series instances, which offer a sliding scale of Nvidia A100 GPUs. Tutel’s MoE algorithmic support is broad and versatile, allowing developers across AI fields to implement MoE more quickly and efficiently. Tutel delivers an 8.49x speedup on an NDm A100 v4 node with 8 GPUs and a 2.75x speedup on 64 NDm A100 v4 nodes with 512 A100 GPUs when compared to state-of-the-art MoE implementations like Meta’s Facebook AI Research Sequence-to-Sequence Toolkit (fairseq) in PyTorch for a single MoE layer. This is a significant benefit because existing machine learning frameworks such as TensorFlow, PyTorch, and others lack a practical all-to-all communication library, resulting in large-scale distributed training performance loss.
Read More: Introducing MT-NLG: The World’s Largest Language Model by NVIDIA and Microsoft
The present MoE-based DNN model depends on the splicing of numerous ready-made DNN operators supplied by deep learning frameworks to generate MoE calculations due to a lack of efficient implementation methods. This strategy might incur substantial performance overhead due to the necessity for duplicate calculations. Here, Tutel proves handy by enabling the creation and development of many highly efficient GPU cores to offer operators for MoE computations.
Tutel, in addition to other high-level MoE solutions such as fairseq and FastMoE, focuses on the optimizations of MoE-specific computation and all-to-all communication, as well as other diversified and flexible algorithmic MoE support. Tutel features a concise user interface that makes it simple to combine with other MoE systems. Developers may also leverage the Tutel interface to embed independent MoE layers into their own DNN models from the ground up, gaining direct access to the highly optimized state-of-the-art MoE capabilities.
“MoE is a promising technology. It enables holistic training based on techniques from many areas, such as systematic routing and network balancing with massive nodes, and can even benefit from GPU-based acceleration,” explains Microsoft.
Tutel, which displayed a significant gain over the fairseq framework, has also been included in the DeepSpeed architecture. Tutel and related integration are expected to benefit additional Azure services, particularly for clients looking to expand their own huge models easily. MoE is still in its initial stages today, and more work is needed to fully fulfill its potential. Consequently, scientists will continue to improve Tutel in the hopes of bringing you even more exciting research and application results in the future.
Tutel is now available for download on GitHub.