


This week, Google introduced the first iteration of TensorFlow Similarity, a Python module meant to train similarity models with the company’s TensorFlow machine learning framework. With the arrival of TensorFlow Similarity, Google aims to blur the machine learning challenges for users.
In today’s day and age, finding similar products is one of the most important functions an app or software can have. For instance, similar-looking outfits, tweets or playlist suggestions, games, etc. This is why multimedia searches and recommendation engines act as an essential part of information systems because they rely on swiftly obtaining relevant content/data, which would otherwise consume a lot of time if not done properly. Most of these applications rely on similarity learning, also known as metric learning and contrastive learning, in order to improve their performance.
Contrastive learning is a machine learning approach that teaches the model which data points are similar or different in order to understand the general characteristics of a dataset without labels. Using this method, a machine learning model may be trained to distinguish between similar and different pictures.
For instance, imagine a baby trying to understand and distinguish between a cricket bat and a ball. The baby will first try to familiarize itself by understanding how either of the objects looks, what their visual features are, and then use those differentiating features and visual cues to identify whether a given object is a bat or ball or neither.
Achieving good results in any computer vision problem begins with learning invariant and discriminative features from input. Because we can train the model to learn a great deal about our data without any annotations or labels, contrastive learning is quite effective.
When a model is applied to a dataset, contrastive learning allows it to project things into an “embedding space,” where the distances between embeddings — mathematical representations of the objects — indicate how similar the input instances are. TensorFlow Similarity training produces a space in which the distance between similar things remains small while the distance between different items grows. This allows the model to push pictures from the same class together while images from other classes are pushed apart.
The goal is to minimize contrastive losses. This is done by finding the distance between two points in an embedding space.
Contrastive losses allow a model to learn how to project objects into the embedding space such that the distances between embeddings are reflective of how comparable the input instances are when applied to a complete dataset. After training, you’ll have a well-clustered area with tiny distances between related things and big distances between different items.
TensorFlow Similarity creates an index that contains the embeddings of the various objects to make them searchable once a model is trained. TensorFlow Similarity employs Fast Approximate Nearest Neighbor Search (ANN) to instantiate the index’s closest matching items in sub-linear time. This fast lookup takes use of TensorFlow’s metric embedding space, which meets triangle inequality requirements and is suitable for ANNs, resulting in excellent retrieval accuracy.
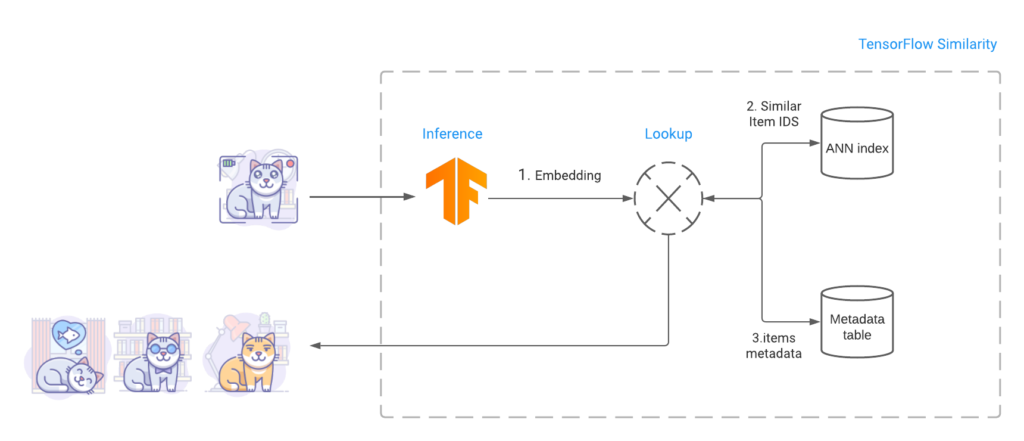
According to Google, the TensorFlow Similarity Python library allows users to search millions of indexed items and retrieve the top comparable results in a fraction of a second. One of the great features of the TensorFlow Similarity package, like other similarity models, is that you may add an unlimited number of new classes to your index without retraining. A few embedded items from these newly added categories will suffice, and they will be automatically saved in place so as not to disrupt any ongoing training process.
Read More: Top 10 Innovations by Google DeepMind
TensorFlow Similarity includes all of the essential components to make evaluating and querying similarity training easy and simple. SimilarityModel(), a Keras model that allows embedding indexing and querying, is one of the new features introduced by TensorFlow Similarity, which enables users to complete end-to-end training and evaluation in a timely and effective manner. In just 20 lines of code, it trains, indexes, and searches MNIST data.
While the library’s initial release focuses on providing components for building contrastive learning-based similarity models, Google says it will expand TensorFlow Similarity to enable other types of models in the future.
At present, TensorFlow Similarity is open-source and accessible via GitHub. Google has also produced a programming notebook that includes a Hello World tutorial on how to use it.