


In any scientific research, leveraging the ‘Trial and error’ methodology helps in finding optimal solutions for a research problem. However, it can be an expensive and time-consuming affair, especially when using this method to train models to deliver desired outcomes. Recently, in the paper titled, Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer,’ co-authored by Microsoft Research and OpenAI, researchers discuss a new technique called µTransfer. This technique has been shown to reduce the amount of trial and error required in the costly process of training large neural networks.
Source: Microsoft
Models of AI (machine learning or deep learning) are mathematical functions that express the relationship between various data points. It takes time to train such models to handle a specific issue, such as image classification, object identification, image segmentation, or any other NLP application. One of the most important reasons is to acquire the best model by properly tuning hyperparameters. In other words, training a model entails selecting the best hyperparameters for the learning algorithm to employ in order to learn the best parameters that accurately map input data (independent variables) to labels or targets (dependent variable), resulting in ‘artificial intelligence.’
Every machine learning/deep learning model is defined using model parameters. Model parameters can be defined as the variables that your chosen machine learning algorithm utilizes to adjust to your data. They are specific to each model and are what separates it from other analogous models that are operating on similar data. Hyperparameters are variables whose values influence the training process and affect the learning algorithm’s model parameters. These variables aren’t linked to the training data in any way. They are configuration variables that remain constant during a task, as opposed to parameters that vary throughout training.
The process of discovering the best combination of hyperparameters to improve model performance is known as hyperparameter tuning (or hyperparameter optimization). Multiple trials are done in a single training job to perform hyperparameter optimization. Each trial is a complete execution of your training application with values for your selected hyperparameters set within the limitations you define. The outcomes of each trial are tracked by a training service, which makes improvements for future trials. When the job is completed, you can receive a summary of all the trials as well as the most effective value configuration based on the criteria provided. Given the crucial aspect of hyperparameter tuning, researchers spend huge time on the same.
The training of hyperparameters in large neural networks consumes resources since the network must estimate which hyperparameters to employ each time. The Microsoft research demonstrates that there is a highly particular parameterization that ensures excellent hyperparameters across a wide range of model sizes. Known as µ-Parametrization (µP, pronounced “myu-P”) or Maximal Update Parametrization, this technique makes use of the fact that neural networks of various sizes share the same optimum hyperparameters under certain conditions, allowing for substantially cheaper costs and improved efficiency while tuning large-scale models. Essentially, this implies that instead of directly tuning an entire multi-billion-parameter model, a small-scale tuning process may be extrapolated outwards and mapped onto a much larger model.
As per studies, large neural networks are difficult to train because their behavior changes as they expand in size. This homogeneity, however, falls off at varying model widths as training develops.
Furthermore, analytically analyzing training behavior is significantly more challenging. To reduce numerical overflow and underflow, the team worked to achieve comparable consistency, such that as the model width develops, the change in activation scales throughout training stays consistent and equivalent to initialization.
As a result, during training, their parameterization was founded on two fundamental ideas:
- Gradient updates in neural networks behave differently than random weights when the width is large. This is because gradient updates are data-driven and take into account correlations, whereas random initializations do not. They must, as a result, be scaled differently.
- The parameters of different shapes also behave differently when the width is large. While weights and biases are often used to partition parameters, with the former being matrices and the latter being vectors, some weights behave like vectors in the large-width scenario.
Researchers used these fundamental ideas to develop µ-Parametrization, which assures that neural networks of various widths act consistently during training. This enables them to converge to a desirable limit (feature learning limit) in addition to maintaining a constant activation scale during training.
The Microsoft team’s scaling theory paves the way for the development of a mechanism for transferring training hyperparameters across model sizes. If µ-Parametrization networks of various widths exhibit identical training dynamics, their ideal hyperparameters will most likely be similar. As a consequence, they could take the best hyperparameters from a small model and apply them to a bigger one. On the other hand, the findings suggest that hyperparameters can achieve the same effect without using a different initialization and learning rate scaling algorithm. This phenomenon was termed as µTransfer.
Read More: Microsoft launches Tutel, an AI open-source MoE library for model training
The Microsoft researchers collaborated with OpenAI to evaluate the efficacy of µTransfer for GPT-3. They first experimented with a smaller model to find the best hyperparameters, then transferred them to a bigger, scaled-up system. The team then used µTransfer on the GPT-3 to transfer hyperparameters from a 40-million-parameter model to a 6.7-billion-parameter model. The researchers calculated that their hyperparameter-tuning expenses leveraging µTransfer were just 7% of what it would have been to pre-train the model, only by eliminating the need to tune the bigger GPT-3’s hyperparameters continually. By transferring pretraining hyperparameters from a 13 million parameter model, it also produced remarkable results on BERT-large (350 million parameters).
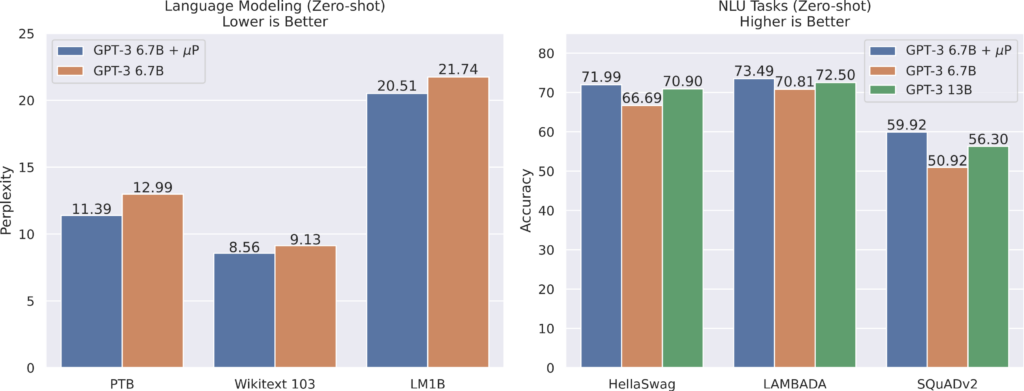
Microsoft has released a PyTorch package to enable other practitioners to profit from these insights by integrating µ-Parametrization into their current models, which otherwise could be difficult to implement.
Microsoft Research first launched Tensor Programs in the year 2020. The research was based on µ-Parametrisation, which allowed for maximum feature learning in the infinite-width limit. µTransfer operates automatically for intricate neural networks such as Transformer and ResNet and is based on the theoretical underpinning of Tensor Programs.
However, Microsoft admits that there is still much to learn about the scalability of AI models and promises to continue its efforts to derive more principled approaches to large-scale machine learning.