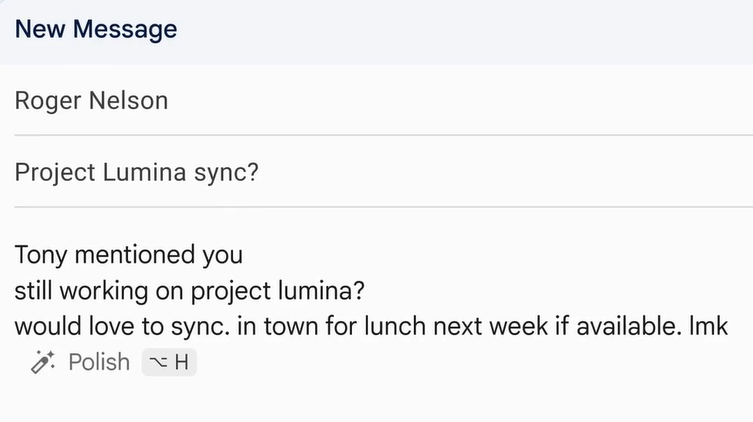
Google has expanded its “Help Me Write” feature in Gmail, making it available on the web. This feature is powered by Gemini AI, which assists you in crafting and refining emails, offering suggestions for changes in length, tone, and detail. However, this feature is exclusive to those with Google One AI Premium or Gemini add-ons for Workforce.
In addition, Google is also a new “Polish” shortcut that will help you quickly refine your emails on both web and mobile platforms. When you open a blank email in the Gmail web version, the Help Me Write feature will appear directly on your draft. This feature is powered by Gemini AI, which is also a Google product.
AI integrated within the Help Me Write feature allows you to write emails from scratch and improves existing drafts. You will see the Polish shortcut appearing automatically on your draft when you’ve written at least 12 words.
To instantly refine your message, you can either click on the shortcut or press Ctrl+H. Mobile users can swipe on shortcuts to refine their drafts. You can further improve the draft after applying the Polish feature, making it more formal, adding details, or shortening it.
Help Me Write is available in Chrome M122 on Mac and Windows PCs in English starting in the U.S. This expansion showcases how Google is continuing to integrate AI writing assistance across its products, making it quicker to compose emails regardless of the device you are using.
Extracting data from websites is crucial for developing data-intensive applications that meet customer needs. This is especially useful for analyzing website data comprising customer reviews. By analyzing these reviews, you can create solutions to fulfill mass market needs.
For instance, if you work for an airline and want to know how your team can enhance customer experience, scraping can be useful. You can scrape previous customer reviews from the internet to generate insights into areas for improvement.
This article highlights the concept of Python web scraping and the different methods you can use to scrape data from web pages.
What Is Python Web Scraping?
Python web scraping is the process of extracting and processing data from different websites. This data can be beneficial for performing various tasks, including building data science projects, training LLMs, personal projects, and generating business reports.
With the insights generated from the scraped data, you can refine your business strategies and improve operational efficiency.
For example, suppose you are a freelancer who wants to discover the latest opportunities in your field. However, the job websites you refer to do not provide notifications, causing you to miss out on the latest opportunities. Using Python, you can scrape job websites to detect new postings and set up alerts to notify you of such opportunities. This allows you to stay informed without having to manually check the sites.
Steps to Perform Python Web Scraping
Web scraping can be cumbersome if you don’t follow a structured process. Here are a few steps to help you create a smooth web scraping process.
Step 1: Understand Website Structure and Permissions
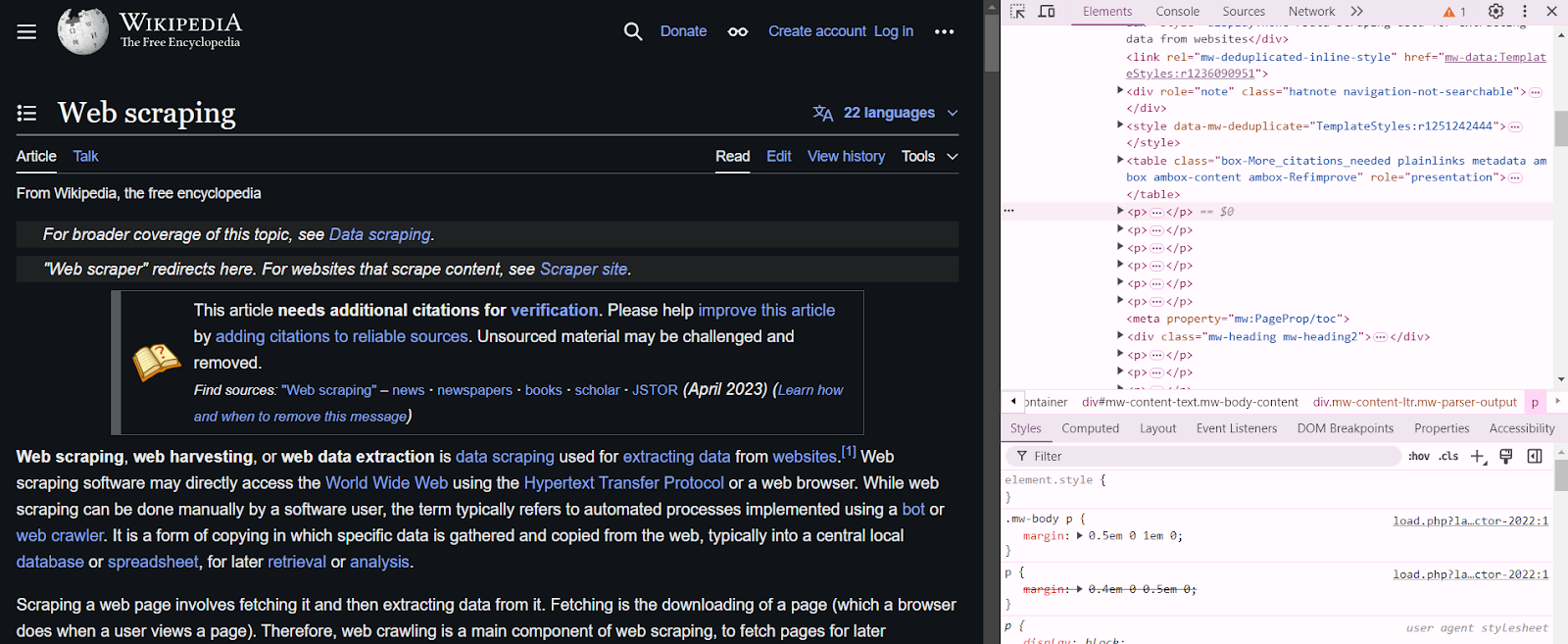
Before you start scraping, you must understand the structure of the website and its legal guidelines. You can visit the website and inspect the required page to explore the underlying HTML and CSS.
To inspect a web page, right-click anywhere on that page and click on Inspect. For example, when you inspect the web scraping page on Wikipedia, your screen will split into two sections to demonstrate the structure of the page.
To check the website rules, you can review the site’s robot.txt file, for example, https://www.google.com/robots.txt. This file provides you with the website’s terms and conditions, which outline the information about the content that is permissible for scraping.
Step 2: Set up the Python Environment
The next step involves the use of Python. If you do not have Python installed on your machine, you can install it from the official website. After successful installation, open your terminal and navigate to the folder where you want to work with the web scraping project. Create and activate a virtual environment with the following code.
This isolates your project from other Python projects on your machine.
Step 3: Select a Web Scraping Method
There are multiple web scraping methods you can use depending on your needs. Popular options include using the Requests library with BeautifulSoup for simple HTML parsing and HTTP requests using web sockets, to name a few. The choice of Python web scraping tools depends on your specific requirements, such as scalability and handling pagination.
Step 4: Handle Pagination
Web pages can be difficult to scrape when the data is spread across multiple pages, or the website supports real-time updates. To overcome this issue, you can use tools like Scrapy to manage pagination. This will help you systematically capture all the relevant data without requiring manual inspection.
Python Scraping Examples
As one of the most robust programming languages, Python provides multiple libraries to scrape data from the Internet. Let’s look at the different methods for importing data using Python:
Using Requests and BeautifulSoup
In this example, we will use the Python Requests library to send HTTP requests. The BeautifulSoup library enables you to pull the HTML and XML files from the web page. By combining the capabilities of these two libraries, you will be able to extract data from any website. If you do not have these libraries installed, you can run this code:
pip install beautifulsoup4
pip install requests
Execute this code in your preferred code editor to perform Python web scraping on an article about machine learning using Requests and BeautifulSoup.
import requests
from bs4 import BeautifulSoup
r = requests.get('https://analyticsdrift.com/machine-learning/')
soup = BeautifulSoup(r.text, 'html.parser')
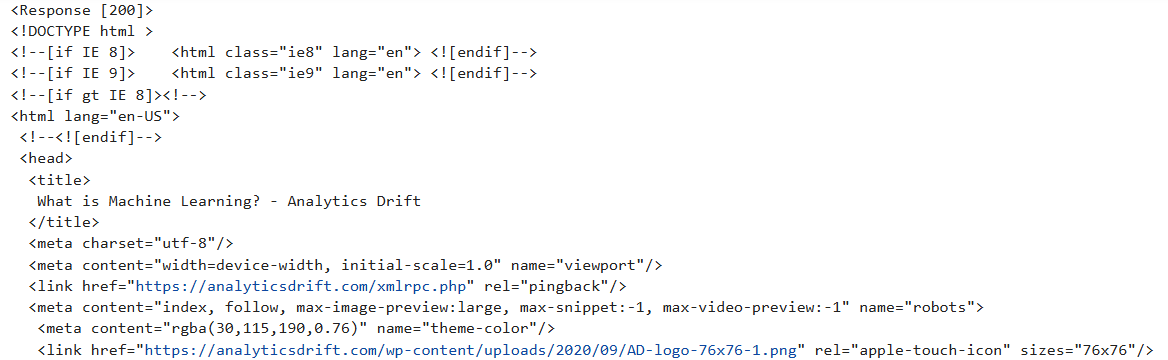
print(r)
print(soup.prettify())
Output:
The output will produce a ‘Response [200]’ to signify the get request has successfully extracted the page content.
Retrieving Raw HTML Contents with Sockets
The socket module in Python provides a low-level networking interface. It facilitates the creation and interaction with network sockets, enabling communication between programs across a network. You can use a socket module to establish a connection with a web server and manually send HTTP requests, which can retrieve HTML content.
Here is a code snippet that enables you to communicate with Google’s official website using the socket library.
This code defines a target server, Google.com, and the port as 80 signifies the HTTP port. You can send requests to the server by establishing a connection and specifying the header request. Finally, the server response is converted from UTF-8 to string form and presented on your screen.
After getting the response, you can parse the data using regular expressions (RegEx), which allows you to search, transform, and manage text data.
Urllib3 and LXML to Process HTML/XML Data
While the socket library provides a low-level interface for efficient network communication, it can be complex to use for typical web-related tasks if you aren’t familiar with network programming details. This is where the urllib3 library can help simplify the process of making HTTP requests and enable you to effectively manage responses.
The following Python web scraping code performs the same operation of retrieving HTML contents from the Google website as the above socket code snippet.
import urllib3
http = urllib3.PoolManager()
r = http.request('GET', 'http://www.google.com')
print(r.data)
Output:
The PoolManager method allows you to send arbitrary requests while keeping track of the necessary connection pool.
In the next step, you can use the LXML library with XPath expressions to parse the HTML data retrieved with urllib3. The XPath is an expression language to locate and extract specific information from XML or HTML documents. On the other hand, the LXML library helps process these documents by supporting XPath expressions.
Let’s use LXML to parse the response generated from urllib3. Execute the code below.
from lxml import html
data_string = r.data.decode('utf-8', errors='ignore')
tree = html.fromstring(data_string)
links = tree.xpath('//a')
for link in links:
print(link.get('href'))
Output:
In this code, the XPath finds all the <a> tags, which define links available on the page and highlight them in the response. You can check that the response contains all the links on the web page that you wanted to parse.
Scraping Data with Selenium
Selenium is an automation tool that supports multiple programming languages, including Python. It’s mainly used to automate web browsers, which helps with web application testing and tasks like web scraping.
Let’s look at an example of how Selenium can help you scrape data from a test website representing the specs of different laptops and computers. Before executing this code, ensure you have the required libraries. To install the necessary libraries, use the following code:
Here’s the sample code to scrape data using Selenium:
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
def setup_driver():
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1920x1080")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36")
service = Service(ChromeDriverManager().install())
return webdriver.Chrome(service=service, options=options)
def scrape_page(driver, url):
try:
driver.get(url)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "title")))
except TimeoutException:
print(f"Timeout waiting for page to load: {url}")
return []
products = driver.find_elements(By.CLASS_NAME, "thumbnail")
page_data = []
for product in products:
try:
title = product.find_element(By.CLASS_NAME, "title").text
price = product.find_element(By.CLASS_NAME, "price").text
description = product.find_element(By.CLASS_NAME, "description").text
rating = product.find_element(By.CLASS_NAME, "ratings").get_attribute("data-rating")
page_data.append([title, price, description, rating])
except NoSuchElementException as e:
print(f"Error extracting product data: {e}")
return page_data
def main():
driver = setup_driver()
element_list = []
try:
for page in range(1, 3):
url = f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={page}"
print(f"Scraping page {page}...")
page_data = scrape_page(driver, url)
element_list.extend(page_data)
time.sleep(2)
print("Scraped data:")
for item in element_list:
print(item)
print(f"\nTotal items scraped: {len(element_list)}")
except Exception as e:
print(f"An error occurred: {e}")
finally:
driver.quit()
if __name__ == "__main__":
main()
Output:
The above code uses a headless browsing feature to extract data from the test website. Headless browsers are web browsers without a graphical user interface that helps you take screenshots of websites and automate data scraping. To execute this process, you define three functions: setup_driver, scrape_page, and main.
The setup_driver() method configures the Selenium WebDriver to control a headless Chrome browser. It includes various settings, such as disabling the GPU and setting the window size to ensure the browser is optimized for scraping without a GUI.
The scrape_page(driver, url) function utilizes the configured web driver to scrape data from the specified webpage. The main() function, on the other hand, coordinates the entire scraping process by providing arguments to these two functions.
Practical Example of Python Web Scraping
Now that we have explored different Python web scraping methods with examples, let’s apply this knowledge to a practical project.
Assume you are a developer who wants to create a web scraper to extract data from StackOverflow. With this project, you will be able to scrape questions with their total views, answers, and votes.
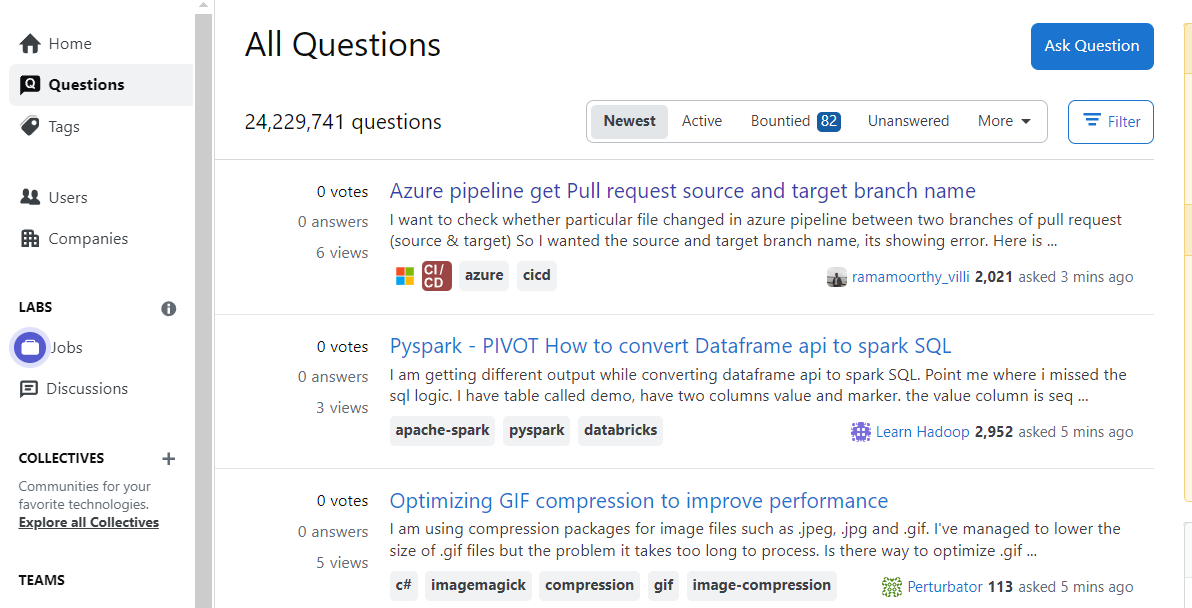
Before getting started, you must explore the website in detail to understand its structure. Navigate to the StackOverflow website and click on the Questions tab on the left panel. You will see the recently uploaded questions.
Scroll down to the bottom of the page to view the Next page option, and click on 2 to visit the next page. The URL of the web page will change and look something like this: https://stackoverflow.com/questions?tab=newest&page=2. This defines how the pages are arranged on the website. By altering the page argument, you can directly navigate to another page.
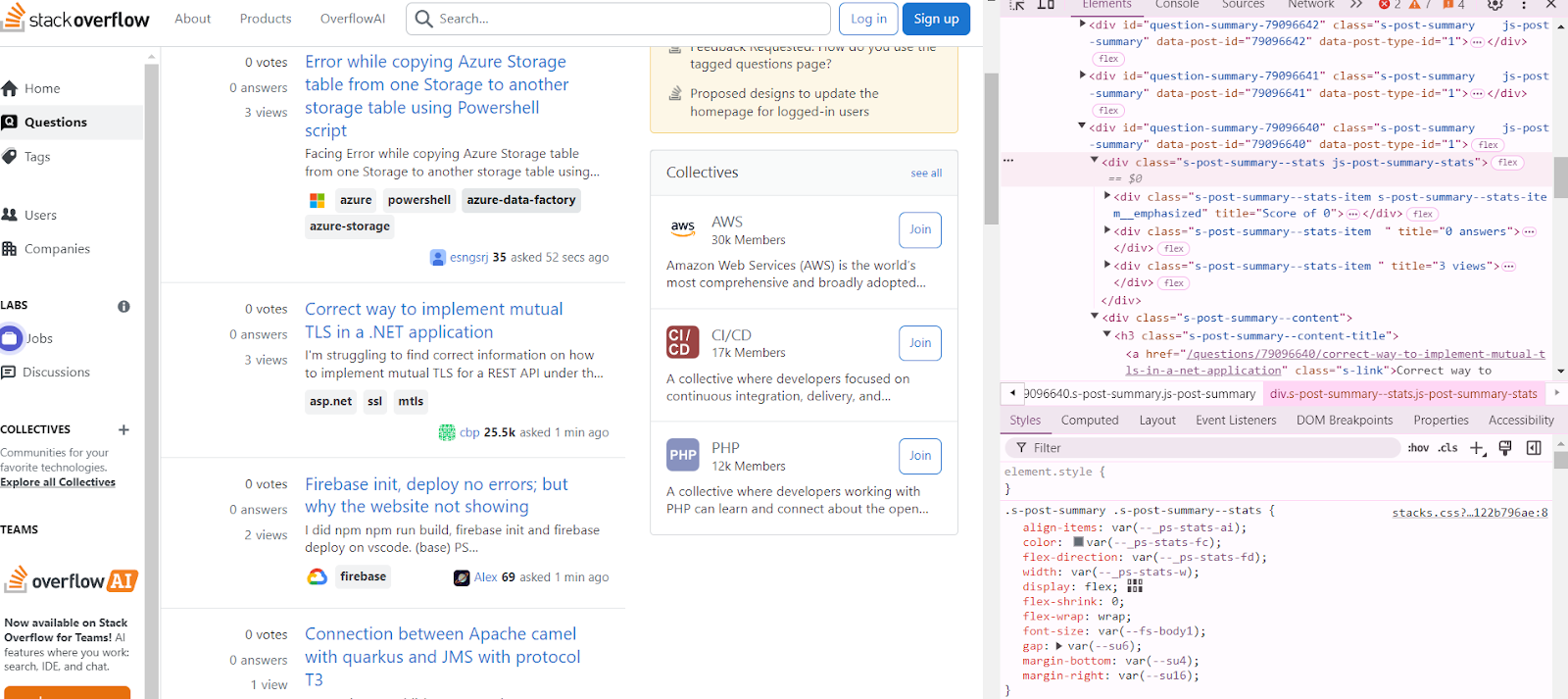
To understand the structure of questions, right-click on any question and click on Inspect. You can hover on the web tool to see how the questions, votes, answers, and views are structured on the web page. Check the class of each element, as it will be the most important component when building a scraper.
After understanding the basic structure of the page, next is the coding. The first step of the scraping process requires you to import the necessary libraries, which include requests and bs4.
from bs4 import BeautifulSoup
import requests
Now, you can mention the URL of the questions page and the page limit.
After generating the URL in a suitable format, execute the code below to create a function that can scrape data from the required web page:
def scrape_page(page=1):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(generate_url(page=page), headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
question_summaries = soup.find_all("div", class_="s-post-summary")
page_questions = []
for summary in question_summaries:
try:
# Extract question title
title_element = summary.find("h3", class_="s-post-summary--content-title")
question = title_element.text.strip() if title_element else "No title found"
# Get vote count
vote_element = summary.find("div", class_="s-post-summary--stats-item", attrs={"title": "Score"})
vote_count = vote_element.find("span", class_="s-post-summary--stats-item-number").text.strip() if vote_element else "0"
# Get answer count
answer_element = summary.find("div", class_="s-post-summary--stats-item", attrs={"title": "answers"})
answer_count = answer_element.find("span", class_="s-post-summary--stats-item-number").text.strip() if answer_element else "0"
# Get view count
view_element = summary.find("div", class_="s-post-summary--stats-item", attrs={"title": lambda x: x and 'views' in x.lower()})
view_count = view_element.find("span", class_="s-post-summary--stats-item-number").text.strip() if view_element else "0"
page_questions.append({
"question": question,
"answers": answer_count,
"votes": vote_count,
"views": view_count
})
except Exception as e:
print(f"Error processing a question: {e}")
continue
return page_questions
Let’s test the scraper and output the results of scraping the questions page of StackOverflow.
results = []
for i in range(1, page_limit + 1):
page_ques = scrape_page(i)
results.extend(page_ques)
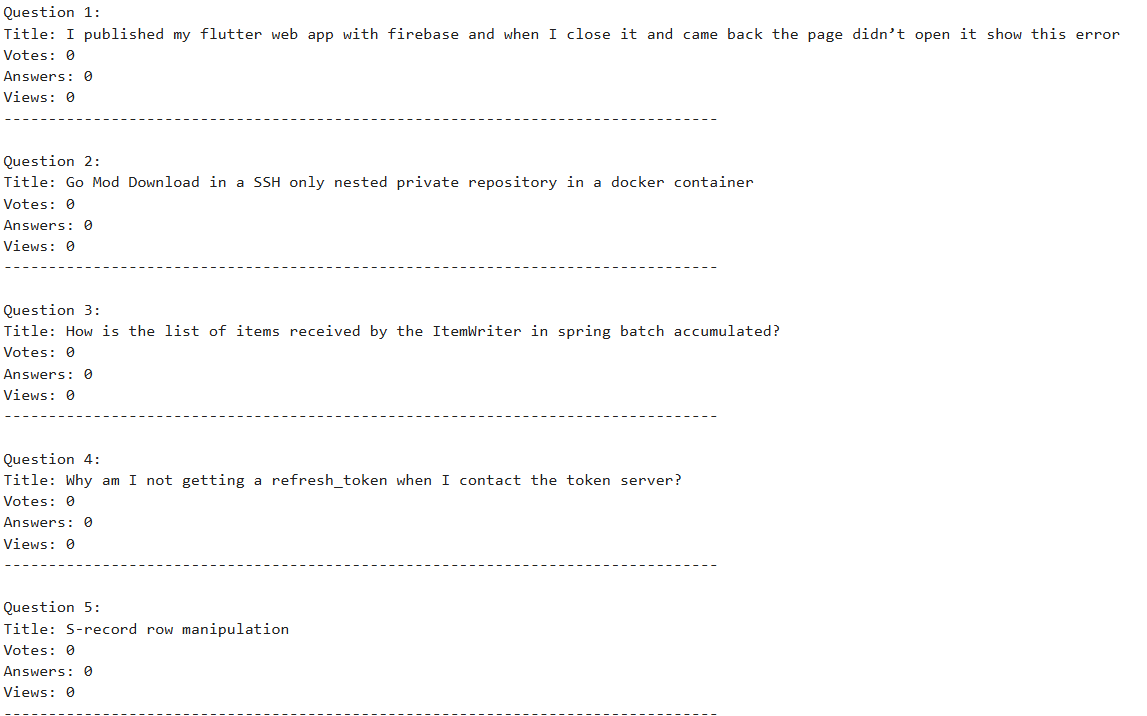
for idx, question in enumerate(results, 1):
print(f"\nQuestion {idx}:")
print("Title:", question['question'])
print("Votes:", question['votes'])
print("Answers:", question['answers'])
print("Views:", question['views'])
print("-" * 80)
Output:
By following these steps, you can build your own StackOverflow question scraper. Although the steps seem easy to perform, there are some important points to consider while scraping any web page. The next section discusses such concerns.
Considerations While Scraping Data
You must check the robots.txt file and the website’s terms and conditions before scraping. This file and documentation outline the parts of the site that are accessible for scraping, helping ensure you comply with the legal guidelines.
There are multiple tools that allow you to scrape data from web pages. However, you should choose the best tool according to your specific needs for ease of use and the data type to scrape.
Before you start scraping any website, it’s important to review the developer tools to understand the page structure. This will help you understand the HTML structure and identify the classes or IDs associated with the data you want to extract. By focusing on these details, you can create effective scraping scripts.
A website’s server can receive too many requests in a short period of time, which might cause server overload or access restrictions with rate limiting. To overcome this issue, you can consider request throttling, which is a method of adding delays between requests to avoid server overload.
Conclusion
Python web scraping libraries allow you to extract data from web pages. Although there are multiple website scraping techniques, you must thoroughly read the associated documentation of the libraries to understand their functionalities and legal implications.
Requests and BeautifulSoup are among the widely used libraries that provide a simplified way to scrape data from the Internet. These libraries are easy to use and have broad applicability. On the other hand, sockets are a better option for low-level network interactions and fast execution but require more programming.
The urllib3 library offers flexibility in working with high-level applications requiring fine control over HTTP requests. In hindsight, Selenium supports JavaScript rendering, automated testing, and scraping Single-Page Applications (SPAs).
FAQs
Is it possible to scrape data in Python?
Yes, you can use Python libraries to scrape data.
How to start web scraping with Python?
To start with web scraping with Python, you must learn HTML or have a basic understanding of it to inspect the elements on a webpage. You can then choose any Python web scraping library, such as Requests and BeautifulSoup, for scraping. Refer to the official documentation of these tools for guidelines and examples to help you start extracting data.
OpenAI, one of the leading AI startups in the world, launched ChatGPT 2022, focusing on providing advanced conversational capabilities. On October 31, 2024, OpenAI introduced a web search capability within the ChatGPT. This add-on enables the model to search the web efficiently to retrieve quick answers with relevant web source links. As a result, you can directly access what you need within your chat interface without being required to search through another search engine.
ChatGPT search model is a refined version of GPT-4, further trained with innovative synthetic data generation methods, including distilled outputs from OpenAI’s o1-preview. It enables the model to automatically search the web based on your inputs to provide a helpful response. Alternatively, you can click on the web search icon and type your query to search through the web.
You can also set ChatGPT search as your default search engine by adding the corresponding extension from the Chrome web store. Once added, you can search directly through your web browser’s URL.
ChatGPT will collaborate with several leading news and data providers to give users up-to-date information on weather, stock markets, maps, sports, and news. OpenAI plans to enhance search capabilities by specializing in areas like shopping, travel, and more. This search experience might be brought to the advanced voice and canvas features.
ChatGPT’s search feature is currently accessible to all Plus and Team users, as well as those on the SearchGPT waitlist. In the upcoming weeks, it will also be available to Enterprise, Edu, Free, and logged-out users. You can use this search tool via chatgpt.com and within the desktop/mobile applications.
Aptera Motor, a San Diego-based car company, successfully completed the first test drive of its solar-powered electric vehicle (SEV), PI2. The three-wheeled vehicle can be charged using solar power and does not require electric charging plugs.
The car will next undergo high-speed track testing to validate its general performance and core efficiency parameters. This includes checking metrics like watt-hours per mile, solar charging rates, and estimated battery ranges. According to Aptera, the next phase of testing will involve integrating its solar technology, production-intent thermal management system, and exterior surfaces.
The solar panels attached to the car’s body can support up to 40 miles of driving per day and 11,000 miles per year without compromising performance. Users can opt for various battery pack sizes, one of which can support up to 1000 miles of range on complete charging. If there is no sunlight or users need to drive more than 40 miles in a day, they can charge PI2 using an electric charging point.
Steve Fambro, Aptera’s co-founder and co-CEO, said, “Driving our first production-intent vehicle marks an extraordinary moment in Aptera’s journey. It demonstrates real progress toward delivering a vehicle that redefines efficiency, sustainability, and energy independence.”
The car company claimed PI2 includes the newly adopted Vitesco Technologies EMR3 drive unit. The success of the first test drive of this car has validated the combination of Aptera’s battery pack and EMR3 powertrain.
PI2 has only six key body components and a unique shape. This allows it to resist air drag with much less energy than other electric or hybrid vehicles.
The successful testing of PI2 will encourage the production of solar-powered EVs, driving innovation and sustainable traveling.
OpenAI initially explored the idea of establishing its own chip-manufacturing foundries. However, it chose in-house chip design due to the high costs and extended timelines associated with such projects. Currently, NVIDIA’s GPU dominates the market with over 80% of the share. The ongoing NVIDIA’s supply shortages and escalating costs have compelled OpenAI to seek alternatives.
To resolve these challenges, OpenAI partnered with Broadcom and TSMC (Taiwan Semiconductor Manufacturing Company Limited) to leverage their chip design and manufacturing expertise. Broadcom is an American MNC that designs, manufactures and supplies a broad range of semiconductor and enterprise products. On the other hand, TSMC, the world’s largest semiconductor foundry, develops digital consumer electronics, automotive, smartphones, and high-performance computing solutions.
Collaborating with these partners will enable OpenAI to create custom AI chips tailored specifically for model training and inference tasks. This enhanced hardware will optimize OpenAI’s generative AI capabilities. Broadcom is helping OpenAI design its AI chips, ensuring that the specifications and features align with OpenAI’s needs. Sources also indicate that OpenAI, through its collaboration with Broadcom, has secured manufacturing capacity at TSMC to produce its first custom chip.
OpenAI is now evaluating whether to develop or use additional components for its chip design and may consider collaborating with other partners. With expertise and resources from more partnerships, OpenAI can accelerate innovation and enhance its technology capabilities.
The company has assembled a team of approximately 20 chip engineers, including specialists who previously designed Google’s Tensor Processing Units (TPUs). Their goal is to develop OpenAI’s first custom chip by 2026, although this timeline remains adaptable.
Interacting with the physical world is essential to accomplishing everyday tasks, which come naturally to humans but is a struggle for AI systems. Meta is making strides in embodied AI by developing a robotic hand capable of perceiving and interacting with its surroundings.
Meta’s fundamental AI research team (FAIR) is collaborating with the robotics community to create agents that can safely coexist with humans. They believe it is a crucial step towards advanced machine intelligence.
Meta has released several new research tools to enhance touch perception, dexterity, and human-robot interaction. The first tool is Meta-Sparsh, a general-purpose encoder that operates on multiple sensors. Sparsh can work across many types of vision-based tactical sensors and leverages self-supervised learning, avoiding the need for labels. It consists of a family of models trained on large datasets. In evaluation, Meta researchers found that Sparsh outperforms task and sensor-specific models by an average of over 95% on the benchmark they set.
Meta Digit 360 is another tool within the Meta Fair family. It is a tactile fingertip with human-level multimodal sensing abilities and 18 sensing features. Lastly, Meta Digital Plexus provides a standard hardware-software interface to integrate tactile sensors on a single robotic hand.
To develop and commercialize these tactile sensing innovations, Meta has partnered with industry leaders, including GelSight Inc. and Wonik Robotics. GelSight will help Meta manufacture and distribute Meta Digit 360, which will be available for purchase next year. In partnership with Wonik Robotics, Meta is poised to create an advanced, dexterous robotic hand that integrates with tactical sensing leveraging Meta Digit Plexus.
Meta believes collaborating across industries is the best way to advance robotics for the greater good. To advance human-robot collaboration, Meta launched the PARTNR benchmark, a standardized framework for evaluating planning and reasoning in human-robot interactions. This benchmark comprises 100,000 natural language processing tasks and supports systematic analysis for LLMs and vision models in real-world scenarios.
Through these initiatives, Meta aims to transform AI models from mere agents into partners capable of effectively interacting with humans.
Amazon has launched its AI-powered shopping assistant, Rufus, in India to improve customers’ shopping experience. It is available in a beta version for selected Android and iOS users.
Rufus is trained on massive data collected by Amazon, including customer reviews, ratings, and product catalogs, to answer customer queries. It performs comparative product analysis and search operations to give precise recommendations.
To use Rufus, shoppers can update their Amazon shopping app and tap an icon on the bottom right. After doing this, the Rufus chat dialogue box will appear on the users’ screen, and they can expand it to see answers to their questions. Customers can also tap on suggested questions or ask follow-up questions to clear their doubts regarding any product. To stop using Rufus, the customers must swipe down to send the chat dialogue box again at the bottom of the app.
Customers can ask Rufus questions such as, ‘Should I get a fitness band or a smartwatch?’ followed by specific questions like, ‘Which ones are durable?’ It helps them find the best products quickly. If the customer is looking for a smartphone, Rufus can help them shortlist mobile phones based on features such as battery life, display size, or storage capacity.
Amazon first launched Rufus in the US in February 2024 and then extended its services to other regions. During the launch in August 2024, Amazon said in its press release, “It is still early days for generative AI. We will keep improving and fine-tuning Rufus to make it more helpful over time.”
Alexa, Amazon’s AI voice assistant, has already been used extensively by users to smartly manage homes and consume personalized entertainment. However, Rufus is a conversational AI assistant who specializes in giving shopping suggestions to Amazon users. It has extensive knowledge of Indian brands and products along with festivals, which makes it capable of providing occasion-specific product suggestions.
Artificial intelligence (AI) has become a transformative element in various fields, including healthcare, agriculture, education, finance, and content creation. According to a Statista report, the global AI market exceeded 184 billion USD in 2024 and is expected to surpass 826 billion USD by 2030.
With such widespread popularity, AI is bound to find its place in multiple organizations over the next few years. However, to efficiently use AI for task automation within your organizational workflows, it is important to know the advantages and disadvantages of AI. Let’s look into the details of the benefits and risks of artificial intelligence, starting with a brief introduction.
Artificial Intelligence: A Brief Introduction
Artificial intelligence is a technology that enables computer systems and machines to mimic human intellect. It makes machines capable of performing specialized tasks, such as problem-solving, decision-making, object recognition, and language interpretation, associated with human intelligence.
AI systems utilize algorithms and machine learning models trained on massive datasets to learn and improve from data. These datasets can be diverse, consisting of text, audio, video, and images. Through training, the AI models can identify patterns and trends within these datasets, enabling the software to make predictions and decisions based on new data.
You can test and fine-tune the parameters of AI models to increase the accuracy of the outcomes they generate. Once the models start performing well, you can deploy them for real-world applications.
Advantages of Artificial Intelligence
AI is increasingly becoming an integral part of various industrial sectors to enhance innovation and operational efficiency. This is due to the precision and speed with which AI facilitates the completion of any task.
Here are some of the advantages of artificial intelligence that make it well-suited for use in varied sectors:
Reduces the Probability of Human Errors
The primary advantage of AI is that it minimizes the chances of human errors by executing tasks with high precision. Most of the AI models are trained on clean and processed datasets, which enables them to take highly accurate actions. For example, you can use AI to accurately analyze patients’ health data and suggest personalized treatments with fewer errors than manual methods.
AI systems can be designed with mechanisms to detect anomalies or failures. In the event of such detection, the system can either make automatic adjustments or alert human operators for intervention. Examples of systems with these capabilities include industrial automation systems, some autonomous vehicles, and predictive maintenance tools.
Enhanced Decision-making
Human decisions are impacted by personal biases. However, AI models trained on unbiased datasets can make impartial decisions. The algorithms in these models follow specific rules to perform any task, which lowers the chances of variations usually arising during human decision-making. AI also facilitates the quick processing of complex and diverse datasets. This helps you make better real-time decisions for your business growth.
For example, an e-commerce company can use AI to dynamically adjust product pricing based on factors such as demand and competitor analysis. To do this, the AI system will analyze large-volume datasets to suggest an optimal price range for e-commerce products. The company can adopt these prices to maximize its revenue while remaining competitive.
Manages Repetitive Tasks
With AI, you can automate repetitive tasks such as customer support, inventory management, data entry, and invoice processing. This reduces the workload of your employees, allowing them to direct their efforts on more productive tasks that contribute to business growth.
For instance, an HR professional can use AI for resume screening, scheduling interviews, and responding to candidate FAQs. This saves you time and helps enhance operational efficiency.
Automation of routine tasks also reduces the chances of errors caused by fatigue or manual input. For example, you can use AI-based OCR software to extract textual business data from documents or emails and enter them correctly every day into a spreadsheet.
24/7 Availability
Unlike humans, AI ensures continuous task execution without any downtime or need for breaks. For instance, an online retail company could deploy AI-powered chatbots and customer support systems to resolve customer queries, process orders, and track deliveries 24/7.
With AI systems, you can serve global clients without the restrictions of time zones. This enables you to deliver your services more efficiently, contributing to revenue generation. All-around-the-clock availability also eliminates the need to hire additional employees for night shifts, reducing labor costs.
Risk Management
AI systems are securely used in risky situations where human safety is at risk. Industries such as mining, space exploration, chemical manufacturing units, and firefighting services can deploy AI robots for their operations.
You can also utilize AI software to monitor and mitigate hazardous conditions at construction sites, oil refineries, and industrial plants. During any emergency situation, the AI system can generate alerts and take actions such as automatically shutting down the equipment or activating fire suppression systems.
Disadvantages of Artificial Intelligence
Despite having significant advantages, AI comes with its own set of limitations. Let’s look into some of the disadvantages associated with using artificial intelligence:
Absence of Creativity
AI systems lack creative capabilities; they cannot generate completely original ideas or solutions for any problem. This makes AI unsuitable for replacing human creativity, especially in fields that require innovation and emotional depth.
For example, an AI-generated news report on the occurrence of a cyclone will lack emotions. The same story, written by an experienced journalist, will contain a human perspective showcasing the impact of the cyclone on people’s lives.
Ethical Issues
The rapid adoption of AI in various sectors has raised several ethical concerns, particularly related to bias and discrimination. If biases are present in the training data, the AI models reflect this bias in the outcomes. This can lead to discriminatory outcomes in sensitive processes such as hiring, lending, or resolving legal issues.
For example, a facial recognition system trained on a biased dataset may give inaccurate results for certain demographic groups. Using such software for criminal identification can lead to misinterpretations, potentially resulting in unjust legal implications for these groups.
Data Security Concerns
Violation of data privacy is another prominent concern when using artificial intelligence. AI models are trained on large volumes of data, which may contain sensitive personal information. The lack of a strong data governance framework and regulatory measures increases the possibility of data breaches.
Yet another major threat is AI model poisoning, in which cyber attackers introduce misleading data in the training datasets. This leads to misinterpretations, inefficient business operations, and failure of AI systems.
Higher Implementation Costs
The overall cost of deploying AI depends on various factors involved in its implementation. The expenses include hardware, software, and specialized personnel. Apart from this, the integration of AI into specific industries also adds to the expense.
You also have to consider the cost of ensuring data security, which involves regular auditing and legal consulting. As a result, even though AI can facilitate automation and improve your operational efficiency, the initial cost of implementing and maintaining it is high. Smaller businesses with limited finances may find it difficult to incorporate AI into their workflows.
Environmental Implications
AI provides solutions for several environmental problems, including monitoring air quality, waste management, and disaster mitigation. However, the development and maintenance of AI require a lot of electrical power, contributing to carbon emissions and environmental degradation.
The hardware required in AI technology contains rare earth elements, whose extraction can be environmentally damaging. AI infrastructure also leads to the generation of huge amounts of electronic waste containing mercury and lead, which is hazardous and takes a long time to degrade.
Best Practices for Balancing the Pros and Cons of Artificial Intelligence
Having seen the details of artificial intelligence advantages and disadvantages, let’s understand how you can balance the different aspects of AI to leverage it effectively.
Here are some best practices that you can adopt for this:
Choose the Right Models
Selecting the right AI model is essential to ensure high performance, efficiency, and optimal resource usage. To select a suitable model, it is important to recognize the objectives that you want to achieve through AI implementation.
Choose those AI models that are relevant to your needs. These models should give appropriate outcomes and should be scalable to accommodate the increase in data volume over time.
Understand the Limitations of Your AI Models
Understanding the limitations of your AI models is crucial to avoid model misuse, performance issues, ethical dilemmas, and operational inefficiency. For example, using an everyday object recognition system for medical imaging will generate inaccurate results, leading to misdiagnosis.
Address Data Governance and Security Issues
Implement a strong data governance and security framework to avoid data breaches. For robust data security, you can deploy role-based access control, encryption, and other authentication mechanisms. It’s also essential to standardize the model training data to ensure high data quality and integrity.
Ensure Fair and Ethical Usage
For ethical usage, you should establish clear guidelines conveying the principles of AI development and use in your organization. Besides, you should train AI models on diverse datasets and conduct regular audits to minimize biases.
For transparency, develop AI systems that can explain their decision-making processes in an understandable manner to users and stakeholders. To achieve this, maintain documentation of data sources and model training processes.
Adopt User-Centric Approach
Design your AI applications by keeping in mind the specific needs of end-users. Conduct thorough research to understand user preferences and challenges. You can also opt for a co-design approach where users can give feedback during the development process. To make your product more user-friendly, you should create training programs and establish a responsive support system to resolve queries of your target users.
Final Thoughts
Artificial intelligence offers numerous advantages and disadvantages. On one hand, it improves work efficiency, speeds up decision-making, and enhances personalization. However, it also presents significant challenges, such as data privacy concerns, ethical issues, inherent biases, and higher operational costs.
To fully harness the benefits of AI, a wise approach is to identify its limitations and actively resolve them. This involves addressing ethical concerns, implementing regulatory frameworks, and fostering transparency and accountability among all stakeholders. By using AI responsibly, you can simplify your data-based workflows and contribute to organizational growth.
FAQs
What are some positive impacts of AI on daily human life?
AI has simplified human lives by automating routine tasks through smart home devices, AI-based robots, and e-commerce applications. To manage calls and emails, you can now use voice-activated personal assistants. Even for recreational purposes, you are automatically recommended content based on your watching history. All this has made everyday life easier.
Will AI replace humans?
No, AI will not completely replace humans, but it can transform the job market. People with AI-based skills will likely replace people who do not possess the same skillset. Especially after the development of GenAI, there is a possibility that jobs such as translation, writing, coding, or content creation will mostly be done using AI tools.
Machine learning (ML) algorithms are programs that help you analyze large volumes of data to identify hidden patterns and make predictions. These algorithms are step-by-step instructions that enable your machines to learn from data and perform several downstream tasks without explicit programming.
As a data analyst, understanding and utilizing these algorithms can significantly enhance your ability to extract valuable insights from complex datasets.
Employing machine learning algorithms allows you to automate tasks, build predictive models, and discover trends you might overlook otherwise. These algorithms can enhance the reliability and accuracy of your analysis results for a competitive edge.
This article will provide a detailed rundown of the top ten machine learning algorithms list that every data analyst in 2024 should know.
Types of Machine Learning Algorithms
Based on the data type and the learning objectives, ML algorithms can be broadly classified into supervised, semi-supervised, unsupervised, and reinforcement learning. Let’s explore each category:
Supervised Machine Learning Algorithms
Supervised learning involves learning by example. The algorithms train on labeled data, where each data point is linked to a correct output value. These algorithms aim to identify the underlying patterns or relationships linking the inputs to their corresponding outcomes. After establishing the logic, they use it to make predictions on new data.
Classification, regression, and forecasting are the three key tasks linked with supervised machine learning algorithms.
Classification: It helps categorize data into predefined classes or labels. For example, classifying e-mails as “spam” or “not spam” or diagnosing diseases as “positive” or “negative.” Common algorithms for classification include decision trees, support vector machines, and logistic regression.
Regression: Regression is used when you want to establish relationships between dependent and independent variables. For example, it can be used to evaluate housing prices based on location or temperature based on previous weather data.
Forecasting: You can use forecasting and predict future values based on historical data trends. It is majorly used in time-series data. Some examples include predicting future sales or demand for specific products.
Semi-Supervised Machine Learning Algorithms
Semi-supervised machine learning algorithms utilize both labeled and unlabeled data. The algorithm uses labeled data to learn patterns and understand how inputs are mapped to outputs. Then, it applies this knowledge to classify the unlabeled datasets.
Unsupervised Machine Learning Algorithms
An unsupervised algorithm works with data that don’t have labels or pre-defined outcomes. It works by exploring large datasets and interpreting them based on hidden data characteristics, patterns, relationships, or correlations. The process involves organizing large datasets into clusters for further analysis.
Unsupervised learning is generally used for clustering, association rule mining, and dimensionality reduction. Some real-world examples include fraud detection, natural language processing, and customer segmentation.
Reinforcement Machine Learning Algorithms
In reinforcement learning, the algorithm employs a trial-and-error method and learns to make decisions based on its interaction with the environment. It gets feedback as rewards or penalties for its actions. Over time, the algorithm leverages past experiences to identify and adapt the best course of action to maximize rewards.
Such algorithms are used to optimize trajectories in autonomous driving vehicles, simulate gaming environments, provide personalized healthcare plans, and more.
Top 10 Algorithms for Machine Learning in 2024
Even though machine learning is rapidly evolving, certain algorithms are consistently effective and relevant across various domains. Here is the top ten machine learning algorithms list that every data analyst in 2024 should know about:
1. Linear Regression
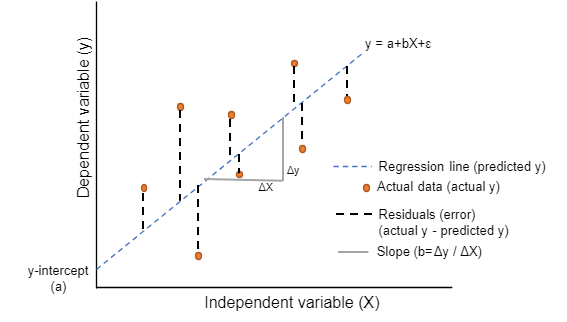
Linear regression, a supervised learning algorithm, is used for modeling relationships between a dependent and one or more independent variables. If one independent variable is involved, it is a simple linear regression; if there are multiple variables, it is called multiple linear regression.
The algorithm assumes the data points have a linear relationship and approximates them along a straight line, described by the equation y=mx+c.
Here:
‘y’ refers to the dependent variable.
‘x’ is the independent variable.
‘m’ is the slope of the line.
‘c’ is the y-intercept.
The objective is to find the best-fitting line that minimizes the distance between actual data points and predicted values on the line. Linear regression has applications in various fields, including economics, finance, marketing, and social sciences, to analyze relationships, make predictions, and understand trends.
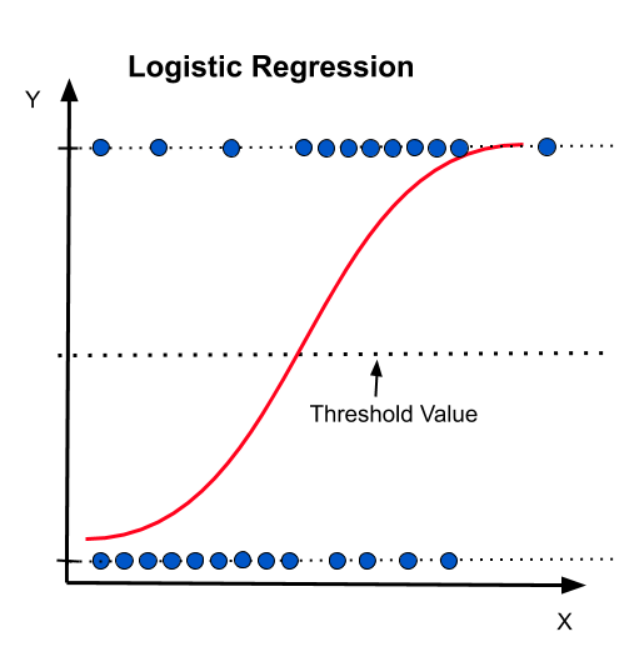
2. Logistic Regression
Logistic regression is a supervised classification algorithm. You can use it to predict binary outcomes (yes/no or 0/1) by calculating probabilities. The algorithm uses a sigmoid function that maps the results into an “S-shaped” curve between 0 and 1.
By setting a threshold value, you can easily categorize data points into classes. Logistic regression is commonly used in spam email detection, image recognition, and health care for disease diagnosis.
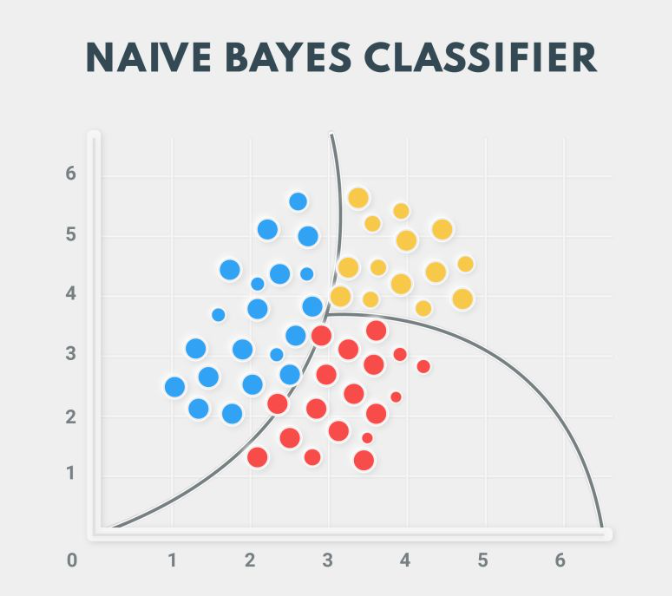
3. Naive Bayes
Naive Bayes is a supervised classification machine learning algorithm. It is based on Bayes’ Theorem and the ‘naive’ assumption that features in an input dataset are independent of each other. The algorithm calculates two probabilities: the probability of each class and the conditional probability of each class given an input. Once calculated, it can be used to make predictions.
There are several variations of this algorithm based on the type of data: Gaussian for continuous data, Multinomial for frequency-based features, and Bernoulli for binary features. Naive Bayes is mainly effective for applications such as sentiment analysis, customer rating classification, and document categorization due to its efficiency and relatively high accuracy.
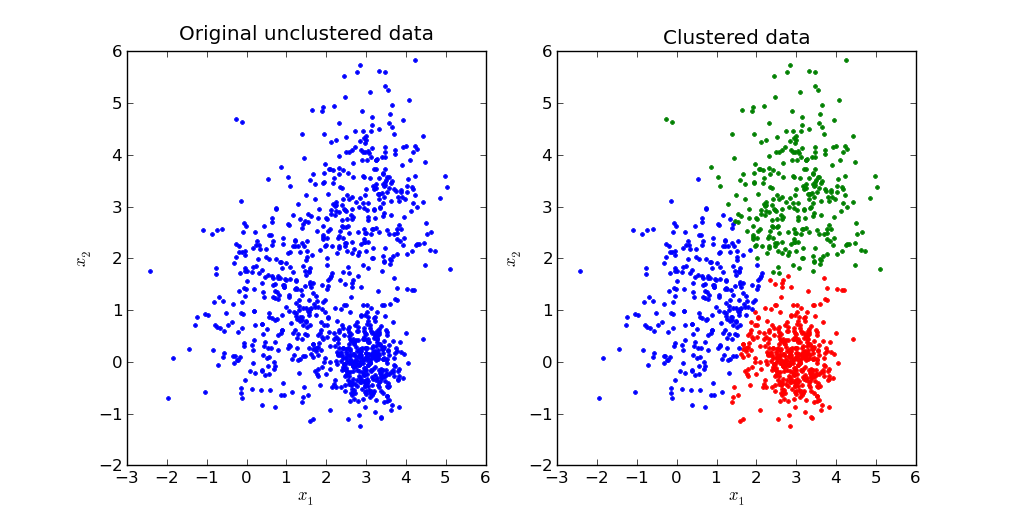
4. k-Means
K-means is an unsupervised learning algorithm that groups data into ‘k’ clusters such that the variances between data points and the cluster’s centroid are minimal. The algorithm begins by assigning data to separate clusters based on Euclidean distance and calculating their centroids.
Then, if a cluster loses or gains a data point, the k-means model recalculates the centroid. This continues until the centroids stabilize. You can utilize this clustering algorithm across various use cases, such as image compression, genomic data analysis, and anomaly detection.
5. Support Vector Machine Algorithm
SVM is a supervised learning algorithm that you can use for both regression and classification tasks. It lets you plot a graph where all your data is represented as points in n-dimensional space (‘n’ is the number of features). Then, several lines (2D) or planes (higher dimensions) that split the data into different classes are found.
The decision boundary, or the hyperplane, is selected such that it maximizes the margin between the nearest data points of different classes. Common kernel functions such as linear, polynomial, and Radial Basis Functions (RBF) can be employed to enable SVM to handle complex relationships within data effectively.
Some real-world applications of the SVM algorithm include hypertext classification, stenographic detection in images, and protein fold and remote homology detection.
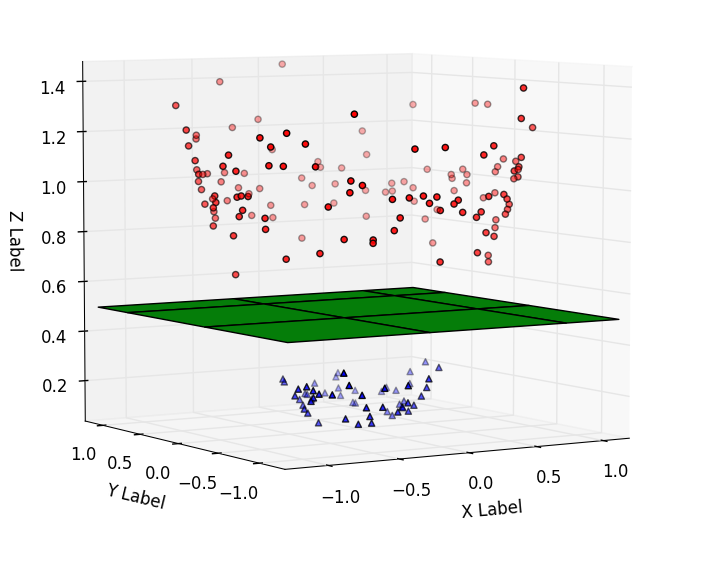
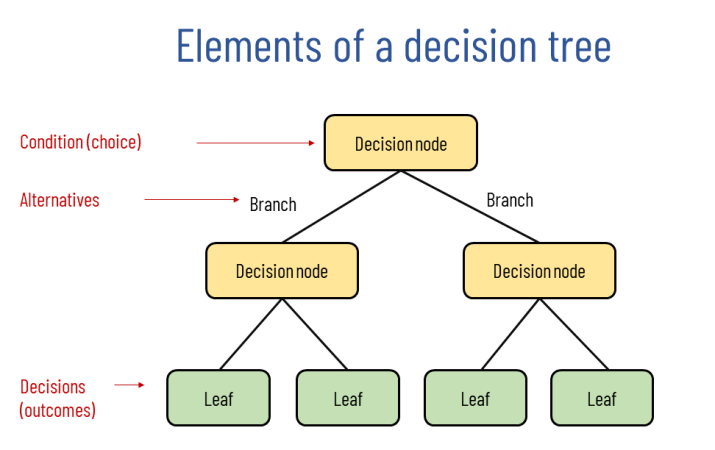
6. Decision Trees
Decision trees are a popular supervised machine learning method used for classification and regression. It recursively splits the dataset based on attribute values that maximize information gain and minimize the Gini index (a measure of impurity).
The algorithm uses the same concept to choose the root node. It starts by comparing the root node’s attribute to the real dataset’s attribute and follows the branch to jump to the next node. This forms a tree structure where internal nodes are decision nodes and leaf nodes are final outputs at which you cannot segregate the tree further.
Decision trees effectively handle both categorical and continuous data. Some variants of this algorithm include Iterative Dichotomiser 3 (ID3), CART, CHAID, decision stumps, and more. They are used in medical screening, predicting customer behavior, and assessing product quality.
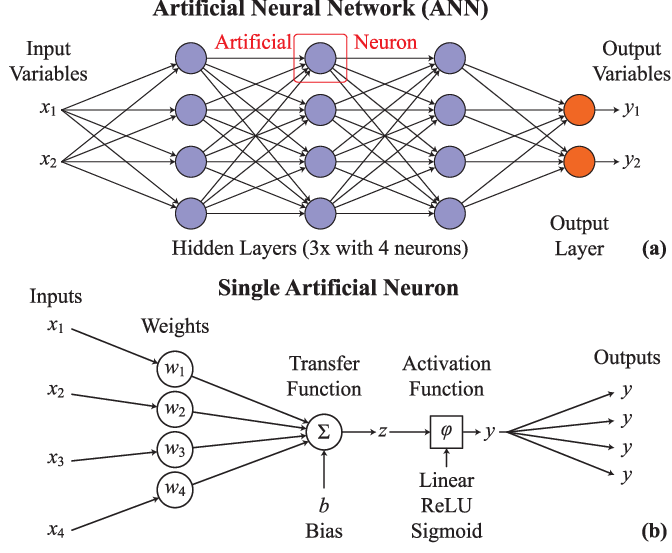
7. Artificial Neural Networks (ANNs)
Artificial neural networks are computational algorithms that work with non-linear and high-dimensional data. These networks have layers of interconnected artificial neurons, including input, hidden, and output layers.
Each neuron processes incoming data using weights and activation functions, deciding whether to pass a signal to the next layer. The learning process involves adjusting the weights through a process called backpropagation. It helps minimize the error between predicted and actual values by tweaking connections based on feedback.
Artificial neural networks support many applications, including research on autism spectrum disorder, satellite image analysis, chemical compound identification, and electrical energy demand forecasting.
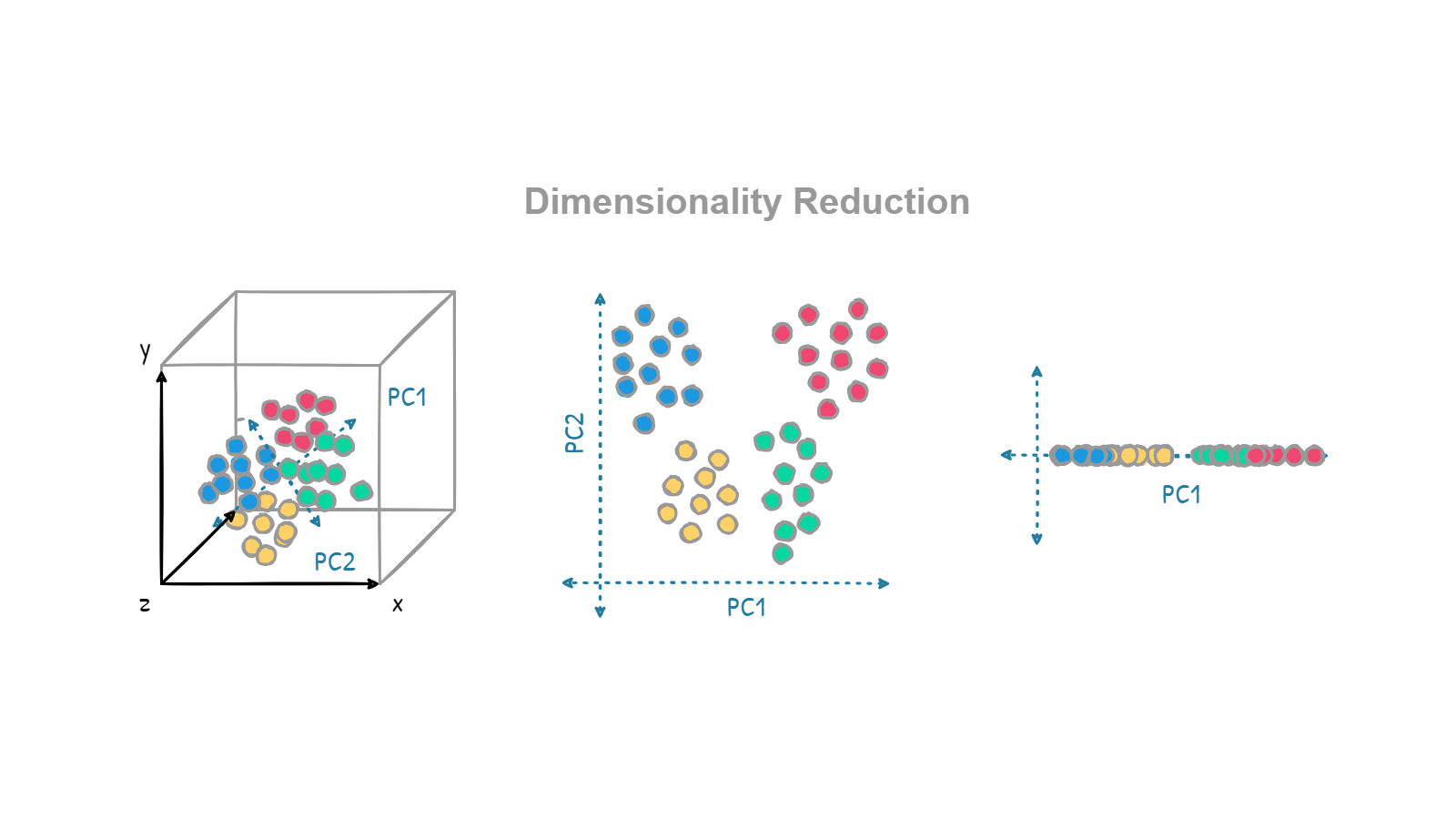
8. Dimensionality Reduction Algorithms
Data with a large number of features is considered high-dimensional data. Reducing the dimensionality refers to reducing the number of features while preserving essential information.
Dimensionality reduction algorithms help you transform high-dimensional data into lower-dimensional data using techniques like linear discriminant analysis (LDA), projection, feature selection, and kernel PCA. These algorithms are valuable for video compression, enhancing GPS data visualization, and noise reduction in datasets.
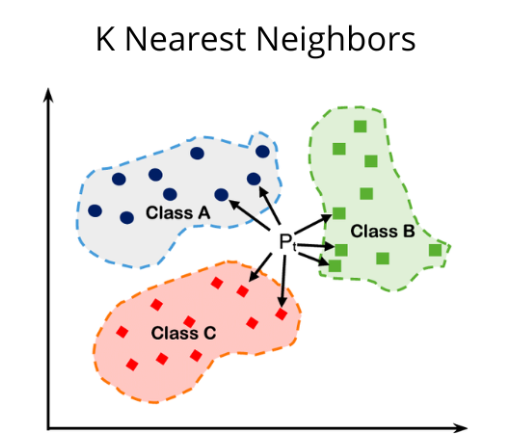
9. kNN Algorithm
kNN stands for k nearest neighbor. This algorithm operates on proximity or similarity. To make predictions using KNN, you should first specify the number (k) of neighbors. The algorithm then uses distance functions to identify the k nearest data points (neighbors) to a new query point from the training set.
Eucledian, Hamming, Manhattan, and Minkowski distance functions are commonly used in the kNN algorithm. While Hamming is used for categorical data, the other three are used for continuous data. The predicted class or value for the new point depends either on the majority class or the average value of ‘k’ nearest neighbors.
Some applications of this algorithm include pattern recognition, text mining, facial recognition, and recommendation systems.
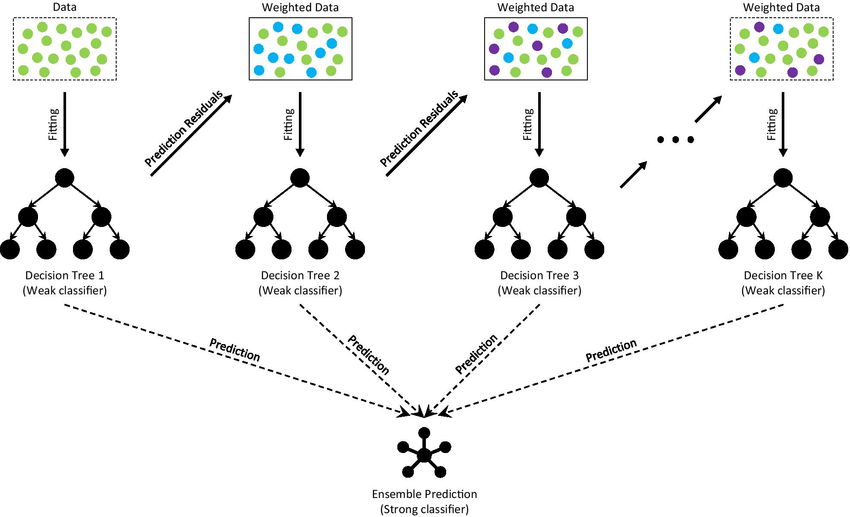
10. Gradient Boosting Algorithms
Gradient boosting machine learning algorithms employ an ensemble method that combines multiple weak models, typically decision trees, to create a strong predictive model. It works by optimizing a loss function, such as log loss for classification or mean squared error for regression.
Many data analysts prefer this algorithm as it can be tuned using hyperparameters such as number of trees, learning rate, and maximum tree depth. It has many variants, including XGBoost, LightGBM, and AdaBoost, which can help you improve the system’s training speed and performance.
You can use gradient boosting for image/object recognition, predictions in finance, marketing, and healthcare industries, and natural language processing.
Final Thoughts
With the top ten algorithms for machine learning, you can extract valuable insights from complex datasets, automate data operations, and make informed decisions. These algorithms provide a strong foundation for building accurate and reliable data models that can drive innovation.
However, when selecting an algorithm, you should consider the specific nature of your data and the problem at hand. Experimenting with different types of machine learning algorithms and fine-tuning their parameters will help you achieve optimal results. Staying up-to-date with the recent advancements in machine learning and artificial intelligence enables you to make the most of your data and maintain a competitive edge in the field.
FAQs
How is linear regression different from logistic regression?
With linear regression, you can predict continuous numerical values and model the relationship between variables. On the other hand, logistic regression allows you to predict probabilities for binary outcomes using a logistic function.
How to avoid overfitting in ANNs?
To avoid overfitting in ANNs, you can employ techniques like:
Dropout layers to randomly deactivate neurons during training.
Early stopping to halt training when the performance deteriorates on a validation set.
Regularization to reduce overfitting by discouraging larger weights in an AI model.
Is k-means sensitive to the initial cluster centroids?
Yes, the k-means algorithm is sensitive to the initial cluster centroids. Poor initialization can lead to the algorithm getting stuck at the local optimum and provide inaccurate results.
Machine learning (ML) is a subset of artificial intelligence that focuses on utilizing data and algorithms to feed various AI models, enabling them to imitate the way a human learns. Through these algorithms, an ML model can recognize patterns, make predictions, and improve their performance over time, providing more accurate outcomes.
Think of how platforms learn from your search and viewing habits to deliver personalized recommendations for products and services. These platforms use machine learning to analyze the search history, constantly learning and adapting to provide results that align with your preferences.
In this article, you will explore different types of machine learning methods, their best practices, and use cases.
What is Machine Learning?
Machine learning is a core component of computer science. Based on the input, the ML algorithm helps the model predict a pattern in the data and provides the output it thinks is most accurate. At a high level, the machine learning applications learn from the previous transactions and computational algorithms and provide reliable results through iteration. The primary intention of using machine learning is to make computer systems and models smarter and more intelligent.
How Does Machine Learning Work?
Machine learning is a system approach that involves several key steps. Here is the breakdown of how it operates:
Data Collection: Machine learning starts with gathering relevant data. This data can come from sources such as databases, data lakes, sensors, user interactions, APIs, and more.
Data Preparation: Once you collect the data, it needs to be cleaned and preprocessed for use.It involves handling missing values, removing duplicates, and normalizing data.
Feature Selection: In this step, you identify relevant features (variables) within the data that will contribute or have the most impact on ML model predictions or outcomes.
Model Selection and Training: You need to choose an algorithm based on the problem type, such as classification (sorting data), clustering (grouping data), or regression (predicting numerical outcomes). Then, you must train your model with the prepared dataset to find patterns and relationships within the data.
Evaluation and Tuning: After the initial training, you can evaluate the model’s performance by testing it on unseen data to check its accuracy. You can also adjust or tune the model’s parameters to minimize errors and improve the output predictions.
Types of Machine Learning Methods
The following are major machine learning algorithms that you can use to train your models, software, and systems:
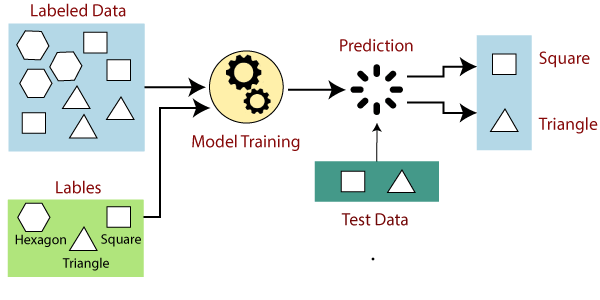
Supervised Learning
Supervised learning is a method where a machine is trained using a labeled dataset. Labeled data is raw data tagged with labels or annotations to add context and meaning to the data.
How Supervised Learning Works
In supervised learning, you provide the model with input data and corresponding output labels. It learns to map the input constraint with the output constraints. For example, if you are teaching the model to recognize different shapes, you would give it labeled data:
If the shape has four sides that are equal, it is a square.
If a shape has three sides, it is a triangle.
If it doesn’t have any sides, it is a circle.
After training the model with the labeled data, you can test its ability to identify shapes using a separate test set. When the model encounters a new shape, it can use the information gained during training to classify the shape and predict the output.
Types of Supervised Learning
There are two types of supervised learning:
Regression: Regression-supervised learning algorithms generate continuous numerical values based on the input value. The main focus of this algorithm is to establish a relationship between independent and dependent variables. For example, it can predict the price of a house based on its size, location, and area.
Classification: A classification-supervised learning algorithm is used to predict a discrete labeled output. It involves training the machine with labeled examples and categorizing input data into predefined labels, such as whether emails are spam or not.
Pros of Supervised Learning
Models can achieve high accuracy due to training on labeled data.
It is easier to make adjustments.
Cons of Supervised Learning
Data dependency is high.
The model might perform well on labeled data but poorly with unseen data.
Best Practices of Supervised Learning
Clean and preprocess data before training the model.
Sometimes, when the training is too small or does not have enough samples to represent all possible data values, it can result in overfitting. The model may provide correct results for training but not for new data. To avoid overfitting, you can diversify and scale the training datasets.
Ensure data is well balanced in terms of class distribution.
Use Cases of Supervised Learning
Spam Detection: It can be used for spam detection by using classification based on features like sender, subject line, and content.
Image Recognition: Supervised learning can be employed for image recognition tasks, where the model can be trained based on labeled images.
Unsupervised Learning
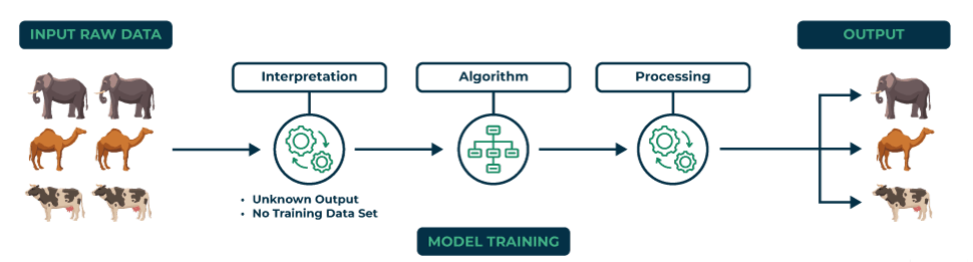
Unsupervised learning is a technique for training an ML model to learn about data without human supervision. The model is provided with unlabeled data, and it must discover patterns without any explicit guidance.
How Unsupervised Learning Works
Unlike supervised learning, where the model knows what to look for, unsupervised learning explores data independently. The model is not given predefined categories or outcomes. It must explore and find hidden structures or groups based on the information it receives.
In the above image, you can see that the model gets input data with no predefined labels for the animals, and no training dataset has been provided to guide or categorize them. The model processes the data through interpretation and algorithm, analyzing animal features, such as the number of legs, size, shape, and other physical features.
Based on the similarities and differences, the model groups similar animals, such as elephants, camels, and cows, into separate clusters.
Types of Unsupervised Learning
There are three types of unsupervised learning:
Clustering: It is the process of grouping the unlabeled data into clusters based on similarities. The aim is to identify relationships among data without prior knowledge of data meaning.
Association Rule Learning: Association rule learning is used to recognize the association between parameters of large data sets. It is generally used for market-based analysis to find associations between different product sales.
Dimensionality Reduction: Dimensionality reduction helps you simplify the dataset by reducing the number of variables while preserving the important features of the original data. This process helps remove irrelevant or repetitive information, making analysis easier for AI models.
Pros of Unsupervised Learning
Saves time and cost involved in data preparation for labeled data.
It can help you reveal the hidden relationships that weren’t initially considered.
Cons of Unsupervised Learning
It is difficult to validate the accuracy or correctness of data.
Discovering patterns without guidance often requires significant computational power.
Best Practices of Unsupervised Learning
As unsupervised learning requires multiple iterations to obtain better results over time, you can try different algorithms and revisit data preprocessing to improve results.
Choose a suitable algorithm depending on your goal.
Implementing data visualization techniques such as t-SNE or UMAP can help better interpret clusters.
Use Cases of Unsupervised Learning
Customer Segmentation: You can utilize unsupervised learning to analyze customer data and create segments based on purchasing behavior.
Market-Based Analyses: Unsupervised learning can be used for market analysis, where you can identify products that are frequently purchased together. This helps optimize product placement.
Semi-Supervised Learning
Semi-supervised learning is a technique that combines both supervised and unsupervised learning methods. You can train the machine using both labeled and unlabeled data. The main focus is to accurately predict the output variable based on the input variable.
How Semi-Supervised Learning Works
In semi-supervised learning, the machine is first trained on labeled data, learning basic patterns within the data. Then, unlabeled data is introduced to the machine to generate predictions or pseudo-labels. These pseudo-data points are combined with the original labeled data to retain the model. The process is repeated until the machine attains accuracy.
Types of Semi-Supervised Learning
Here are two significant types of semi-supervised learning:
Self-Training: This method involves first training the machine on labeled data. Once trained, this new model is applied to unlabeled data to make predictions.
Co-Training: Co-training involves training two or more machines on the same dataset but using different features.
Pros of Semi-Supervised Learning
Leads to better generalization as it works with both labeled and unlabeled data.
High accuracy can be achieved through training from labeled data.
Cons of Semi-Supervised Learning
More complex to implement.
Careful handling of both labeled and unlabeled data is needed; otherwise, the performance of the ML model might be affected.
Best Practices of Semi-Supervised Learning
Start with high-quality labeled data to guide the learning process for your system.
Regularly validate the model by using separate test sets to avoid noisy data.
Experiment with different amounts of labeled data to find a balance between labeled and unlabeled data input.
Use Cases of Semi-Supervised Learning
Speech Recognition: Labelling audio files is very intensive and time-consuming. You can use the self-training model of semI-supervised learning to improve speech recognition.
Text Classification: You can train a model with labeled text and then unlabeled text so it can learn to classify documents more accurately.
Reinforcement Learning
The reinforcement machine learning model involves training software and models to make decisions to achieve the most optimal results. It mimics the trial-error learning method that humans use to achieve their goals.
How Reinforcement Machine Learning Works
In this method, there is an agent (learner or decision maker) and an environment (everything the agent interacts with). The agent studies the current state of the environment, takes action to influence it, and uses the feedback to update its understanding. Over time, the agent learns which actions lead to high rewards, allowing it to make better decisions.
Types of Reinforcement Machine Learning
Positive Reinforcement: It involves increasing the tendency that is required for a particular action to occur again in the future. For example, in a gaming environment, if you successfully complete a task, you receive points for it. Then, you will likely take up another task to get more rewards.
Negative Reinforcement: In this learning model, you remove an undesirable stimulus to increase the likelihood of a particular behavior occurring again. For example, if you get a penalty for making a mistake, you will learn to avoid the error.
Pros of Reinforcement Learning
It helps to solve complex real-world problems which can otherwise be difficult to interpret using conventional methods.
RL agents learn through trial and error, gaining experience that can lead to more efficient decision-making.
Cons of Reinforcement Learning
Training model reinforcement learning can be expensive.
It is not preferable to solve simple problems.
Conclusion
Machine learning is a transformative branch of artificial intelligence that assists systems to learn from data and make informed predictions. Machine learning can be classified into three major types: supervised, unsupervised, and semi-supervised models. You can employ these models for different uses, but they all contribute to natural language processing tasks. By understanding the methods and their applications, you can create efficient machine-learning models that provide optimal outcomes for your input data.
FAQs
What Are the Two Most Common Types of Machine Learning?
The two most common types are supervised and unsupervised machine learning methods.
What Are Some of the Challenges of Machine Learning?
Some of the challenges that machine learning faces include data overfitting and underfitting, poor data quality, computational costs, and interpretability.