


Image classification using machine learning rose to prominence in a recent couple of years. While processing images to understand the visual data is nothing new as earlier researchers relied on raw pixel data to classify visual data. In this process, computers would fragment an image into individual pixels for further analysis. However, this was not an effective method as the computers often got confused in cases when two images of the same subject appear to be very different. Machines also struggled with images focusing on a single entity but having a variety of backdrops, perspectives, positions, and so on. Thus, making it difficult for computers to see and categorize images appropriately.
As a result, scientists turned to deep learning, which is a subset of machine learning that uses neural networks for processing input data. In neural networks, information is filtered by hidden layers of nodes. Each of these nodes processes the data and relays the findings to the next layer of nodes. This continues until it reaches an output layer, at which point the machine produces the desired result.
Using convolution neural networks (CNN) machine learning models became extremely good at classifying images and videos. CNN is a form of neural network where the output of the nodes in the hidden layers of CNNs is not always shared with every node in the following layer (known as convolutional layers).
Despite being proficient in detecting patterns in data, scientists are baffled by how these models make decisions or how they arrived at the said decision. Furthermore, when there is a likelihood that the machine learning model makes judgments based on inadequate, error-prone, or one-sided (biased) information, the constant need to understand the mechanisms underlying the decisions becomes even more important.
Recently, the Massachusetts Institute of Technology (MIT) has discovered an intriguing problem involving machine learning and image classification called overinterpretation. Depending on where deep learning algorithms are used, this problem might be innocuous or dangerous if it is not fixed. Apart from adversarial attacks and data poisoning, overinterpretation is the new irritant for AI researchers and developers.
The MIT researchers discovered that neural networks trained on popular datasets like CIFAR-10 and ImageNet include “nonsensical” signals that are troublesome. Models trained on them suffer from overinterpretation, a phenomenon in which they label images with such high confidence that they are useless to humans. For instance, models trained on CIFAR-10 made confident predictions even when 95% of input images were missing, and the remainder is senseless to humans.
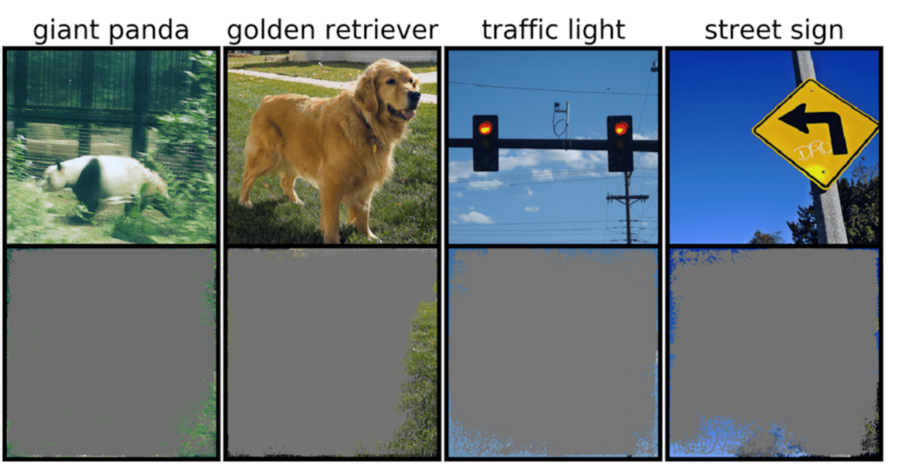
In the actual world, these signals can lead to model fragility, but they’re also valid in datasets, which means overinterpretation can’t be detected using traditional approaches.
“Not only are these high-confidence images unrecognizable, but they contain less than 10 percent of the original image in unimportant areas, such as borders. We found that these images were meaningless to humans, yet models can still classify them with high confidence,” says Brandon Carter, MIT Computer Science, and Artificial Intelligence Laboratory Ph.D. student and lead author of this research.
Read More: Fujitsu and MIT Center for Brains, Minds, and Machines Build AI model to Detect OOD data
The team explains that machine-learning algorithms have the potential to cling onto these meaningless tiny signals, making image classification difficult. Then, after being trained on datasets like ImageNet, image classifiers can make seemingly reliable predictions based on those signals.
The MIT team adds that datasets are equally to be blamed for causing overinterpretation. According to Carter, scientists can start by questioning ways to modify the datasets in a manner that models trained on those can more closely mimic how a human would think about classifying images. Carter hopes that the algorithms could generalize better in real-world scenarios, such as autonomous driving and medical diagnosis so that the models don’t show nonsensical behavior, else it can lead to fatal outcomes due to flawed prediction.
This might imply producing datasets in a more controlled setting. Currently, images retrieved from public domains are the only ones that are classified. The team notes that overinterpretation, unlike adversarial attacks, relies on unmodified image pixels. At present, the MIT team asserts that ensembling and input dropout, can both assist prevent overinterpretation. You can read more about the research findings here.
This research was sponsored by Schmidt Futures and the National Institutes of Health.
Carter collaborated on the research with Amazon scientists Siddhartha Jain and Jonas Mueller, as well as MIT Professor David Gifford. They’ll share their findings at the Conference on Neural Information Processing Systems in 2021.