


After releasing a blurry background feature in Google Meet in mid-September 2020, Google is now rolling out a more advanced version of Google Meet, where you can replace the background with hand-picked images. Although late, Google’s machine learning algorithm behind the blurry/replace background looks superior to the early adopters like Zoom and Skype. But how is it any better? Unlike other video conferencing applications that fail to remove and replace your image precisely, especially while moving around, Google’s blurry/replace does not look artificial; your image will never look detached from the background. So, what is the machine learning technique in Google Meet for blurry/replace backgrounds?

According to Google, existing solutions require installation of software, but Google Meet is equipped with state-of-the-art technology built with MediaPipe, an open-source framework that enables users to build and run machine learning pipelines on mobile, web, and edge devices, to work seamlessly in browsers.

Google released MediaPipe for the web on January 28, 2020, which was enabled by WebAssembly and accelerated by XNNPack ML Inference Library. Running a machine learning process in a browser is not a straightforward task when it comes to speed of execution. While Skype and Zoom rely on desktop applications for the best experience to get the computational power, Google Meet entirely relies on web browsers. To expedite the process on the web, Google made browsers convert WebAssembly instructions into native machine code that executes much faster than the traditional JavaScript code.
Machine learning in Google Meet segments users from the original background with inference to compute a low-resolution mask. On further refining the mask, the video is rendered with WebGL2 (Web Graphics Libraries)–a JavaScript API for rendering high-performance interactive 3D and 2D graphics without the need for plugins.
The segmentation model is run in real-time on the web using the client’s CPU, which is accelerated with the XNNPACK library and SIMD. To further consider the speed, the model varies its performance on high-end and low-end devices; a full pipeline is run on high-end devices, but on low-end devices, mask refinement is bypassed. Further, to reduce the need for floating-point operations (FLOPs) in browsers while processing every frame, the researchers downsample the image size before feeding it to the model.
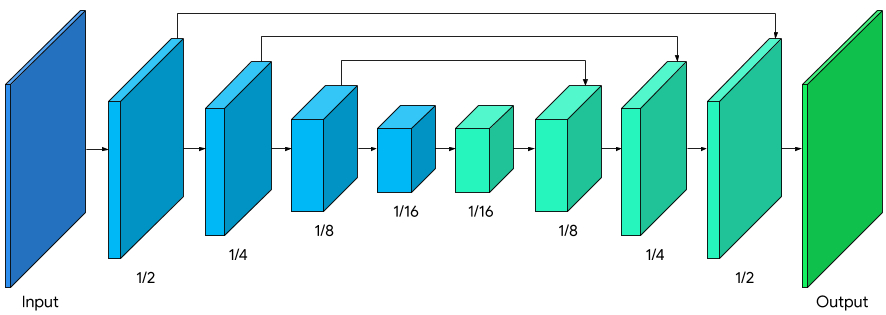
“We modified MobileNetV3-small as the encoder, which has been tuned by network architecture search for the best performance with low resource requirements. To reduce the model size by 50%, we exported our model to TFLite using float16 quantization, resulting in a slight loss in weight precision but with no noticeable effect on quality. The resulting model has 193K parameters and is only 400KB in size,” mentions researchers.

- Yann LeCun Ruptures The GPT-3 Hype With A FB Post
- Microsoft Lobe — A Free Platform For No-Code Machine Learning
- Microsoft Releases Clarity, A Web Analytics Platform
After the segmentation, the researchers used OpenGL–Open Graphics Library–for video processing and effect rendering. For refinements, they applied a bilateral filter, a non-linear, edge-preserving, and noise-reducing smoothing filter for images, and flushed the low-resolution mask. Besides, pixels were weighted by their circle-of-confusion (CoC) to ensure the background and foreground look separate. And to remove halo artifacts surrounding the person, separable filters were used instead of the popular Gaussian pyramid.

However, for a background with custom images, the researchers used the light wrapping technique. Light wrapping helps soften segmentation edges by letting background light spill over onto foreground elements, thereby making the compositing more immersive. The method also helps minimize halo artifacts in case of a large contrast between the foreground and the replaced background.