


Torchchat, an advancement from PyTorch, enhances capabilities for deploying large language models such as Llama across various devices.
PyTorch introduced Torchchat, a cutting-edge library designed to revolutionize the deployment of large language models (LLMs) like Llama 3 and 3.1. It supports deployment across multiple platforms, including laptops, desktops, and mobile devices.
Torchchat extends its support for additional environments, models, and execution modes and offers functions for export, quantization, and evaluation in an intuitive manner. It delivers a comprehensive solution for developing local inference systems.
This development enables PyTorch to provide a more versatile and comprehensive toolkit for AI deployment. Torchchat provides a well-structured LLM deployment approach that is organized into three key areas.
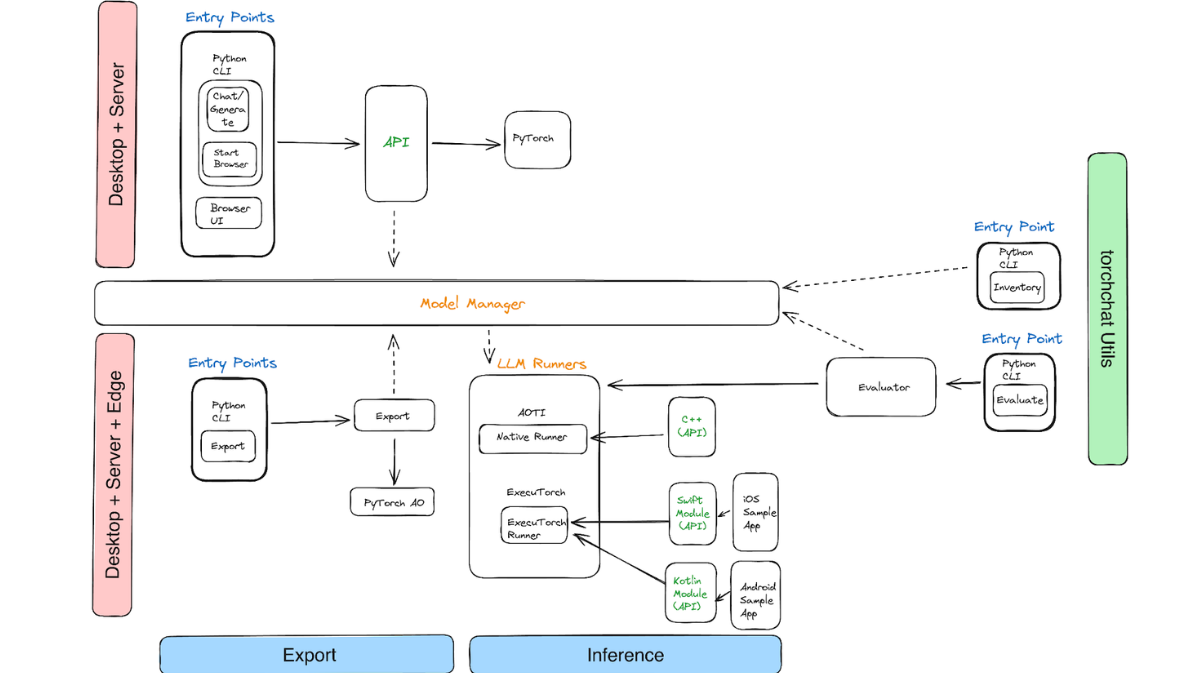
For Python, Torchchat features a REST API accessible through a Python CLI or web browser, simplifying developers’ management and interaction with LLMs. In a C++ environment, Torchchat creates high-performance desktop binary using PyTorch’s AOTInductor backend. For mobile devices, it exports .pte binaries for efficient on-device inference.
Read More: Zuckerberg announces PyTorch Foundation to Accelerate Progress in AI Research.
Torchchat has impressive performance metrics across various device configurations.
On laptops like MacBook Pro M1 Max, Torchchat achieves upto 17.15 tokens per second for Llama 2 using MPS Eager mode with int4 data type. This demonstrates Torchchat’s efficiency on premium laptops.
On desktops with an A100 GPU on Linux, Torchchat reaches speeds of up to 135.16 tokens per second for Llama 3 in int4 mode. It leverages CUDA for optimal performance on powerful desktop systems.
For mobile devices, Torchchat delivers over 8 tokens per second on devices like Samsung Galaxy S23 and iPhone. Torchchat also uses 4-bit GPTQ through ExecuTorch, bringing advanced AI capabilities to mobile platforms.
These performance metrics highlight Torchchat’s capabilities of efficiently running LLMs across various devices, ensuring that advanced AI technologies are accessible and effective on different platforms.