


Machine learning (ML) is a subset of artificial intelligence that focuses on utilizing data and algorithms to feed various AI models, enabling them to imitate the way a human learns. Through these algorithms, an ML model can recognize patterns, make predictions, and improve their performance over time, providing more accurate outcomes.
Think of how platforms learn from your search and viewing habits to deliver personalized recommendations for products and services. These platforms use machine learning to analyze the search history, constantly learning and adapting to provide results that align with your preferences.
In this article, you will explore different types of machine learning methods, their best practices, and use cases.
What is Machine Learning?

Machine learning is a core component of computer science. Based on the input, the ML algorithm helps the model predict a pattern in the data and provides the output it thinks is most accurate. At a high level, the machine learning applications learn from the previous transactions and computational algorithms and provide reliable results through iteration. The primary intention of using machine learning is to make computer systems and models smarter and more intelligent.
How Does Machine Learning Work?
Machine learning is a system approach that involves several key steps. Here is the breakdown of how it operates:
- Data Collection: Machine learning starts with gathering relevant data. This data can come from sources such as databases, data lakes, sensors, user interactions, APIs, and more.
- Data Preparation: Once you collect the data, it needs to be cleaned and preprocessed for use. It involves handling missing values, removing duplicates, and normalizing data.
- Feature Selection: In this step, you identify relevant features (variables) within the data that will contribute or have the most impact on ML model predictions or outcomes.
- Model Selection and Training: You need to choose an algorithm based on the problem type, such as classification (sorting data), clustering (grouping data), or regression (predicting numerical outcomes). Then, you must train your model with the prepared dataset to find patterns and relationships within the data.
- Evaluation and Tuning: After the initial training, you can evaluate the model’s performance by testing it on unseen data to check its accuracy. You can also adjust or tune the model’s parameters to minimize errors and improve the output predictions.
Types of Machine Learning Methods
The following are major machine learning algorithms that you can use to train your models, software, and systems:
Supervised Learning
Supervised learning is a method where a machine is trained using a labeled dataset. Labeled data is raw data tagged with labels or annotations to add context and meaning to the data.
How Supervised Learning Works
In supervised learning, you provide the model with input data and corresponding output labels. It learns to map the input constraint with the output constraints. For example, if you are teaching the model to recognize different shapes, you would give it labeled data:
- If the shape has four sides that are equal, it is a square.
- If a shape has three sides, it is a triangle.
- If it doesn’t have any sides, it is a circle.
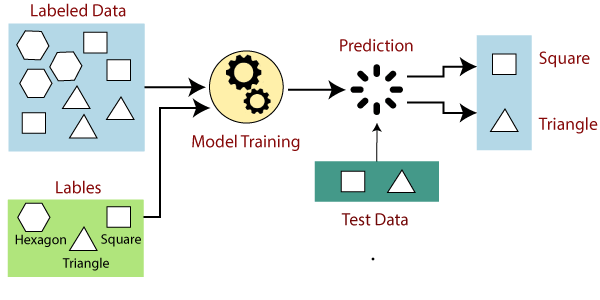
After training the model with the labeled data, you can test its ability to identify shapes using a separate test set. When the model encounters a new shape, it can use the information gained during training to classify the shape and predict the output.
Types of Supervised Learning
There are two types of supervised learning:
- Regression: Regression-supervised learning algorithms generate continuous numerical values based on the input value. The main focus of this algorithm is to establish a relationship between independent and dependent variables. For example, it can predict the price of a house based on its size, location, and area.
- Classification: A classification-supervised learning algorithm is used to predict a discrete labeled output. It involves training the machine with labeled examples and categorizing input data into predefined labels, such as whether emails are spam or not.
Pros of Supervised Learning
- Models can achieve high accuracy due to training on labeled data.
- It is easier to make adjustments.
Cons of Supervised Learning
- Data dependency is high.
- The model might perform well on labeled data but poorly with unseen data.
Best Practices of Supervised Learning
- Clean and preprocess data before training the model.
- Sometimes, when the training is too small or does not have enough samples to represent all possible data values, it can result in overfitting. The model may provide correct results for training but not for new data. To avoid overfitting, you can diversify and scale the training datasets.
- Ensure data is well balanced in terms of class distribution.
Use Cases of Supervised Learning
- Spam Detection: It can be used for spam detection by using classification based on features like sender, subject line, and content.
- Image Recognition: Supervised learning can be employed for image recognition tasks, where the model can be trained based on labeled images.
Unsupervised Learning
Unsupervised learning is a technique for training an ML model to learn about data without human supervision. The model is provided with unlabeled data, and it must discover patterns without any explicit guidance.
How Unsupervised Learning Works
Unlike supervised learning, where the model knows what to look for, unsupervised learning explores data independently. The model is not given predefined categories or outcomes. It must explore and find hidden structures or groups based on the information it receives.
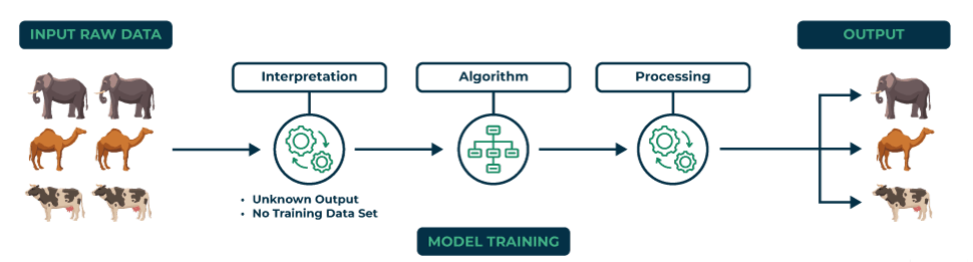
In the above image, you can see that the model gets input data with no predefined labels for the animals, and no training dataset has been provided to guide or categorize them. The model processes the data through interpretation and algorithm, analyzing animal features, such as the number of legs, size, shape, and other physical features.
Based on the similarities and differences, the model groups similar animals, such as elephants, camels, and cows, into separate clusters.
Types of Unsupervised Learning
There are three types of unsupervised learning:
- Clustering: It is the process of grouping the unlabeled data into clusters based on similarities. The aim is to identify relationships among data without prior knowledge of data meaning.
- Association Rule Learning: Association rule learning is used to recognize the association between parameters of large data sets. It is generally used for market-based analysis to find associations between different product sales.
- Dimensionality Reduction: Dimensionality reduction helps you simplify the dataset by reducing the number of variables while preserving the important features of the original data. This process helps remove irrelevant or repetitive information, making analysis easier for AI models.
Pros of Unsupervised Learning
- Saves time and cost involved in data preparation for labeled data.
- It can help you reveal the hidden relationships that weren’t initially considered.
Cons of Unsupervised Learning
- It is difficult to validate the accuracy or correctness of data.
- Discovering patterns without guidance often requires significant computational power.
Best Practices of Unsupervised Learning
- As unsupervised learning requires multiple iterations to obtain better results over time, you can try different algorithms and revisit data preprocessing to improve results.
- Choose a suitable algorithm depending on your goal.
- Implementing data visualization techniques such as t-SNE or UMAP can help better interpret clusters.
Use Cases of Unsupervised Learning
- Customer Segmentation: You can utilize unsupervised learning to analyze customer data and create segments based on purchasing behavior.
- Market-Based Analyses: Unsupervised learning can be used for market analysis, where you can identify products that are frequently purchased together. This helps optimize product placement.
Semi-Supervised Learning
Semi-supervised learning is a technique that combines both supervised and unsupervised learning methods. You can train the machine using both labeled and unlabeled data. The main focus is to accurately predict the output variable based on the input variable.
How Semi-Supervised Learning Works

In semi-supervised learning, the machine is first trained on labeled data, learning basic patterns within the data. Then, unlabeled data is introduced to the machine to generate predictions or pseudo-labels. These pseudo-data points are combined with the original labeled data to retain the model. The process is repeated until the machine attains accuracy.
Types of Semi-Supervised Learning
Here are two significant types of semi-supervised learning:
- Self-Training: This method involves first training the machine on labeled data. Once trained, this new model is applied to unlabeled data to make predictions.
- Co-Training: Co-training involves training two or more machines on the same dataset but using different features.
Pros of Semi-Supervised Learning
- Leads to better generalization as it works with both labeled and unlabeled data.
- High accuracy can be achieved through training from labeled data.
Cons of Semi-Supervised Learning
- More complex to implement.
- Careful handling of both labeled and unlabeled data is needed; otherwise, the performance of the ML model might be affected.
Best Practices of Semi-Supervised Learning
- Start with high-quality labeled data to guide the learning process for your system.
- Regularly validate the model by using separate test sets to avoid noisy data.
- Experiment with different amounts of labeled data to find a balance between labeled and unlabeled data input.
Use Cases of Semi-Supervised Learning
- Speech Recognition: Labelling audio files is very intensive and time-consuming. You can use the self-training model of semI-supervised learning to improve speech recognition.
- Text Classification: You can train a model with labeled text and then unlabeled text so it can learn to classify documents more accurately.
Reinforcement Learning
The reinforcement machine learning model involves training software and models to make decisions to achieve the most optimal results. It mimics the trial-error learning method that humans use to achieve their goals.
How Reinforcement Machine Learning Works
In this method, there is an agent (learner or decision maker) and an environment (everything the agent interacts with). The agent studies the current state of the environment, takes action to influence it, and uses the feedback to update its understanding. Over time, the agent learns which actions lead to high rewards, allowing it to make better decisions.

Types of Reinforcement Machine Learning
- Positive Reinforcement: It involves increasing the tendency that is required for a particular action to occur again in the future. For example, in a gaming environment, if you successfully complete a task, you receive points for it. Then, you will likely take up another task to get more rewards.
- Negative Reinforcement: In this learning model, you remove an undesirable stimulus to increase the likelihood of a particular behavior occurring again. For example, if you get a penalty for making a mistake, you will learn to avoid the error.
Pros of Reinforcement Learning
- It helps to solve complex real-world problems which can otherwise be difficult to interpret using conventional methods.
- RL agents learn through trial and error, gaining experience that can lead to more efficient decision-making.
Cons of Reinforcement Learning
- Training model reinforcement learning can be expensive.
- It is not preferable to solve simple problems.
Conclusion
Machine learning is a transformative branch of artificial intelligence that assists systems to learn from data and make informed predictions. Machine learning can be classified into three major types: supervised, unsupervised, and semi-supervised models. You can employ these models for different uses, but they all contribute to natural language processing tasks. By understanding the methods and their applications, you can create efficient machine-learning models that provide optimal outcomes for your input data.
FAQs
What Are the Two Most Common Types of Machine Learning?
The two most common types are supervised and unsupervised machine learning methods.
What Are Some of the Challenges of Machine Learning?
Some of the challenges that machine learning faces include data overfitting and underfitting, poor data quality, computational costs, and interpretability.