


Artificial intelligence (AI) has gained popularity in the technological sector in recent years. The highlights of AI include natural language processing with models like ChatGPT. However, despite their increasing use, many people are still unfamiliar with the underlying architecture of these technologies.
The AI models you interact with daily use transformers to model output from the input data. Transformers are a specialized type of neural network designed to handle complex unstructured data effectively, leading to their popularity among data professionals. Here’s a graph that showcases the popularity of neural networks over the past year based on the number of Google searches.
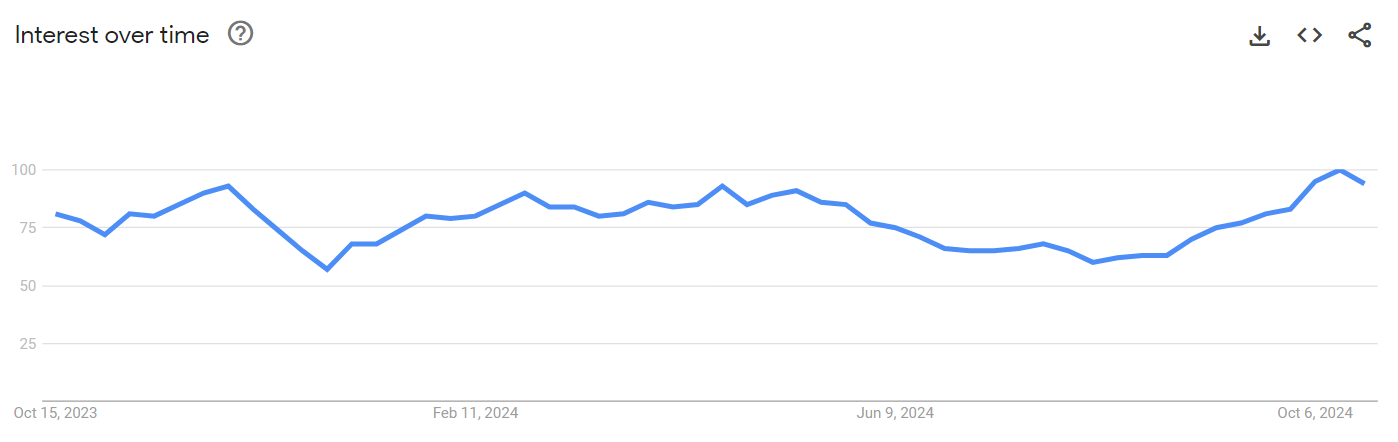
You can see a constant interest of people in the concept of neural networks.
This guide highlights the concept of machine learning neural networks and their working principles. It also demonstrates how to train a model and explores use cases that can help you understand how they contribute to better data modeling.
What Are Machine Learning Neural Networks?
A neural network is a type of machine-learning model developed to recognize patterns in data and make predictions. The term “neural” refers to neurons in the human brain, which was an early inspiration for developing these systems. However, neural networks cannot be directly compared with the human brain, which is too complex to model.
Neural networks consist of layers of nodes, or neurons, each connected to others. A node activates when its output is beyond a specified threshold value. Activation of a node signifies that it can send data to subsequent nodes in the next layer. This is the underlying process of neural networks, which are trained using large datasets to improve their ability to respond and adapt. After training, they can be used to predict outcomes for previously unseen data, making them robust machine learning algorithms.
Often, neural networks are referred to as black boxes because it is difficult to understand the exact internal mechanisms they use to arrive at conclusions.
Components of Neural Network
To understand the working process of a machine learning artificial neural network, you must first learn about weights, biases, and activation functions. These elements determine the network’s output.
For example, to perform a linear operation with two features, x1 and x2, the equation “y = m1x1 + m2x2 + c” would be handy.
Weights: These are the parameters that specify the importance of a variable. In the sample equation, m1 and m2 are the weights of x1 and x2, respectively. But how do these weights affect the model? The response of the neural network depends on the weights of each feature. If m1 >> m2, the influence of x2 on the output becomes negligible and vice versa. As a result, the weights determine the model’s behavior and reliance on specific features.
Biases: The biases are constants, like “c” in the above example, that work as additional parameters alongside weights. These constants shift the input of the activation function to adjust the output. Offsetting the results by adding the biases enables neural networks to adjust the activation function to fit the data better.
Activation Function: The activation functions are the central component of neural network logic. These functions take the input provided, apply a function, and produce an output. The activation function is like a node through which the weighted input and biases pass to generate output signals. In the above example, the dependent variable “y” is the activation function.
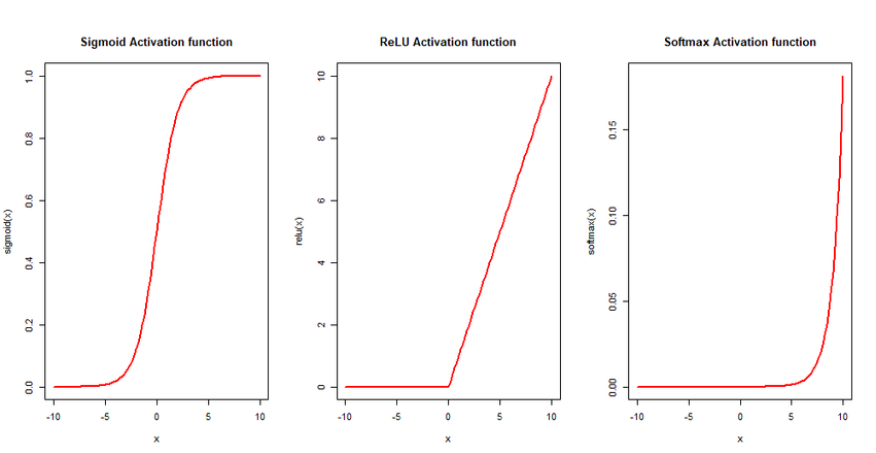
For real-world applications, three of the most widely used activation functions are:
- ReLU: Rectified Linear Unit, or ReLU, is a piecewise linear function that returns the input directly if its value is positive; if not, it outputs zero.
- Sigmoid: The sigmoid function is a special form of logistic function that outputs a value between 0 and 1 for all values in the domain.
- Softmax: The softmax function is an extension of the sigmoid function that is useful for managing multi-class classification problems.
How Do Neural Networks Work?
A neural network operates based on the architecture you define. The architecture comprises multiple layers, including an input layer, one or more hidden layers, and an output layer. These layers work together to create an adaptive system, enabling your model to learn from data and improve its prediction over time.
Let’s discuss the role of each layer and the working process of a machine learning artificial neural network.
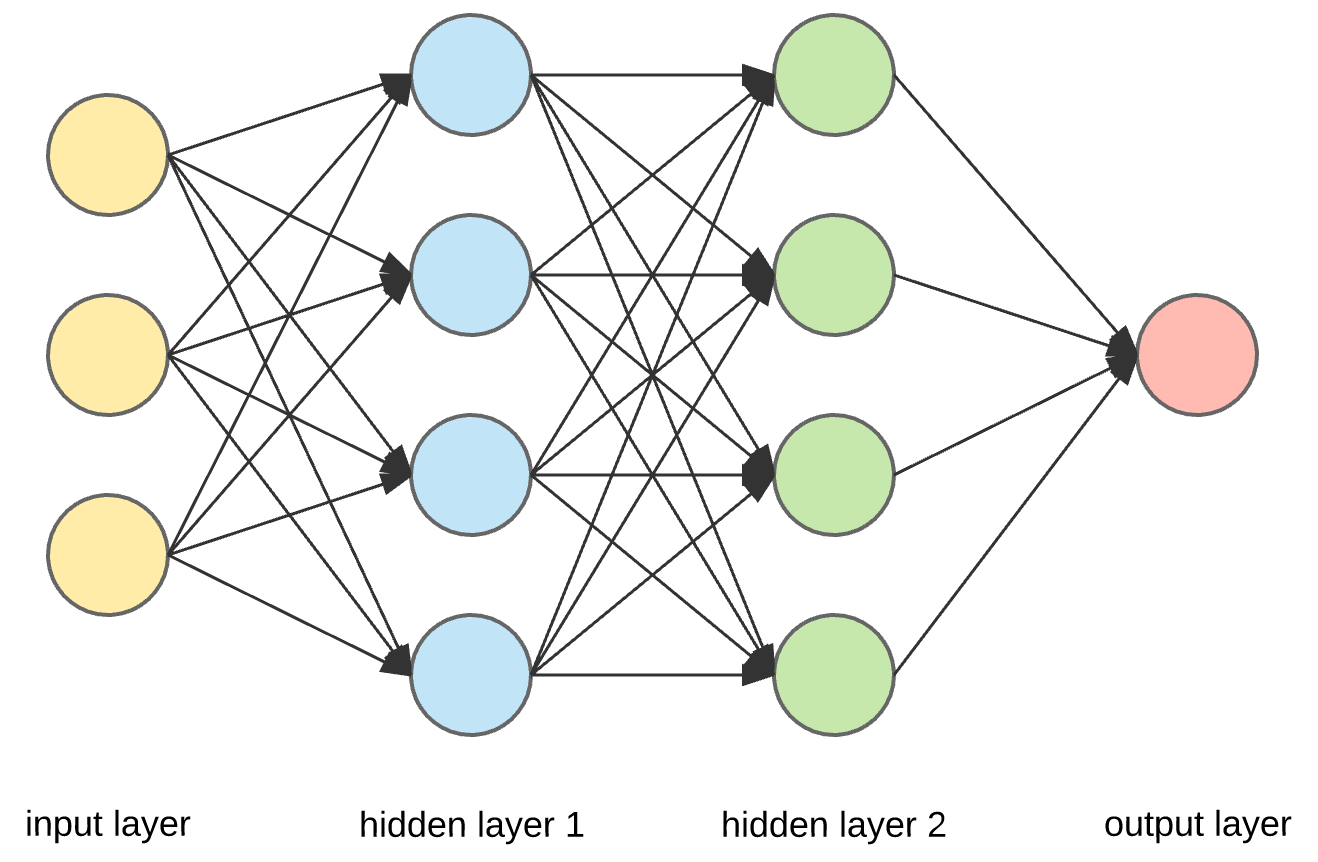
Input Layer: The input layer represents the initial point of data entry in the neural network; it receives the raw data. Each node in the input layer defines a unique feature in the dataset. The input layer also organizes and prepares the data so that it matches the expected input format for further processing by subsequent layers.
Hidden Layer: The hidden layers contain the logic of the neural network with several nodes that have an activation function associated with them. These activation functions determine whether and to what extent a signal should continue through the network. The processed information from the input layer is transformed within the hidden layers, creating new representations that capture the underlying data patterns.
Output Layer: The output layer is the final layer of the neural network that represents the model predictions. It can have a single or multiple nodes depending on the task to be performed. For regression tasks, a single node suffices to provide a continuous output. However, for classification tasks, the output layer comprises as many nodes as there are classes. Each node represents the probability that the input data belongs to a specific class.
After the data passes through all the layers, the neural network analyzes the accuracy of the model by comparing the output with the actual results. To further optimize the performance, the neural network uses backpropagation. In backpropagation, the network adjusts the weights and biases in reverse, from the output layer back to the input layer. This helps minimize prediction errors with techniques such as gradient descent.
How to Train a Neural Network?
Let’s learn about the neural network training algorithm—backpropagation—which utilizes gradient descent to increase the accuracy of the predictions.
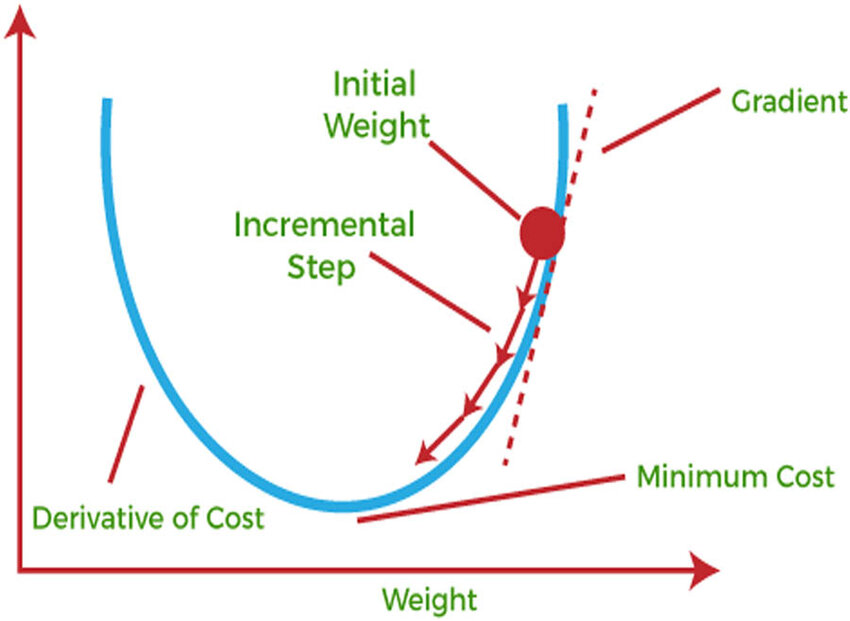
Gradient descent is a model optimization algorithm used in training neural networks. It aims to minimize the cost function—the difference between predicted values and actual values. The cost function defines how well the neural network is performing; a lower cost function indicates that the model is better at generalizing from the training data.
To reduce the cost function, gradient descent iteratively adjusts the model’s weights and biases. The point where the cost function reaches a minimum value represents the optimal settings for the model.
When training a neural network, data is fed through the input layer. The backpropagation algorithm determines the values of weights and biases to minimize the cost function. This ensures that the neural network is able to gradually improve its accuracy and efficiency at making predictions.
Neural networks have three types of learning: supervised, unsupervised, and reinforcement learning. While supervised learning involves training a model using labeled data, unsupervised learning involves training models on unlabeled data. In unsupervised learning, the neural network recognizes the data patterns to categorize similar data points.
On the other hand, reinforcement learning neural networks learn through interactions with the environment through trial and error. Such networks receive feedback in the form of rewards for correct actions and penalties for mistakes. The rewarding tasks are repeated while the penalties are avoided.
For instance, a robot trained to avoid fire might receive a reward for using water to extinguish the flames. However, approaching the fire without safety precautions can be considered a penalty.
What are Deep Learning Neural Networks
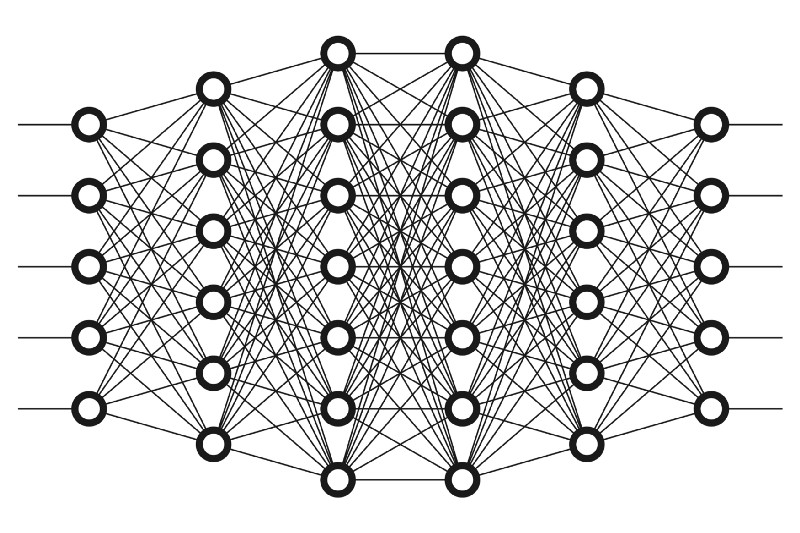
In deep learning neural networks, the word “deep” highlights the density of the hidden layer. Prominently known as deep learning, it is a subset of machine learning that uses neural networks with multiple hidden layers. These networks facilitate the processing of complex data by learning to extract features automatically without requiring manual feature extraction. It simplifies the analysis of unstructured data, such as text documents, images, and videos.
Machine Learning vs Neural Networks
Both machine learning and neural networks are beneficial for making predictions based on data patterns. But what factors differentiate them? In practical applications, machine learning is used for tasks such as classification and regression, employing algorithms like linear or logistic regression.
During the process of training a machine learning model, you might notice that you don’t have to manually define its architecture. Most of the machine learning algorithms come with predefined structures. This makes it fairly straightforward to apply these algorithms since they don’t require you to define the model’s architecture. Contrarily, neural networks provide you with the flexibility of defining the model architecture by outlining the layers and nodes involved. However, they lack ease of use, trading simplicity for flexibility, allowing you to build more robust models.
While machine learning effectively works with smaller or structured datasets, its performance can significantly reduce when large unstructured data is involved. Neural networks, on the other hand, are preferred for more complex situations where you want accurate modeling of large unstructured datasets.
Types of Neural Networks
Neural networks are typically categorized based on their architecture and specific applications. Let’s explore the different types of machine learning neural networks.
Feedforward Neural Network (FNN)
Feedforward neural networks are simple artificial neural networks that process data in a single direction, from the input to the output layer. Its architecture does not consist of a feedback loop, making it suitable for basic tasks such as regression analysis and pattern recognition.
Convolutional Neural Network (CNN)
Convolutional neural networks are a special type of neural network designed for processing data that has a grid-like topology, like in images. It combines convolutional layers with neurons to effectively learn the features of an image, enabling the model to recognize and classify test images.
Recurrent Neural Network (RNN)
A recurrent neural network, or RNN, is an artificial neural network that processes sequential data. It is primarily recognized for its feedback loops, which allow optimization of weights and biases to enhance output. The feedback loops enable the retention of information within the network, making RNN suitable for tasks like natural language processing and time series analysis.
Neural Network Use Cases
- Financial Applications: Neural networks are the backbone of multiple financial systems, and they are used to predict stock prices, perform algorithmic trading, detect fraud, and assess credit risk.
- Medical Use Cases: Machine learning neural networks can be beneficial in diagnosing diseases by analyzing medical images, such as X-rays or MRI scans. You can also identify drugs and dosages that may be suitable for patients with specific medical conditions.
- E-Vehicles: AI has become an integral part of most electronic vehicles. The underlying neural network model processes the vehicle’s sensor data in real-time to produce results, such as an object or lane detection and speed regulation. It then performs operations like steering, braking, and accelerating based on the results.
- Content Creation: The use of neural networks in content creation has been significant, with LLMs such as ChatGPT simplifying the complex tasks for content creators. To enhance creativity further, several models can create realistic video content, which you can use in marketing, entertainment, and virtual reality apps.
Key Takeaways
Understanding machine learning artificial neural networks is essential if you’re a professional working in data-driven fields. With this knowledge, you can learn about the underlying structures of most AI applications in the tech market.
Although neural networks are efficient in modeling complex data, the opacity of the hidden layers introduces a level of uncertainty. However, neural networks can effectively model data to produce accurate predictions. This makes them invaluable tools, especially in scenarios where precision is critical in AI applications.
FAQs
Is a neural network essential for deep learning?
Yes, neural networks are essential for deep learning. However, other machine learning techniques don’t necessarily require neural networks.
Why do neural networks work so well?
Neural networks work so well because of their extensive number of parameters—with weights and biases—which allow them to model complex relationships in data. Unlike simple machine learning models, training a neural network requires much more data, which allows it to generalize outcomes for new, unseen data.
Does machine learning use neural networks?
Yes, neural networks are a subset of machine learning and are used to perform complex tasks within this broader field. They’re particularly useful for tasks involving large amounts of data and require modeling intricate patterns.