


Hyperparameter tuning is a complex skill in data science to obtain exceptional results from the machine learning models. Often data scientists have to tune and train machine learning models to check their accuracy, consuming a colossal amount of resources. Such practices not only increase the operating costs but also impedes organizations in releasing products in the market. However, to eliminate such bottlenecks, Facebook AI has introduced a self-supervised learning framework for model selection (SSL-MS) and hyperparameter tuning (SSL-HPT) to provide accurate predictions while reducing the need for computational resources.
Current Techniques Used For Hyperparameter Tuning
Over the years, data scientists have embraced grid search, random search, and Bayesian optimal search to tune hyperparameters. According to researchers, these techniques require huge computational resources as well as cannot be used for scalable time-series hyperparameter tuning. With Facebook AI’s framework, data scientists can quickly optimize the hyperparameters without hampering the accuracy of the models.
For now, the framework can be used in time-series tasks like demand forecasting, anomaly detection, capacity planning and management, and energy prediction. “Our SSL framework offers an efficient solution to provide high-quality forecasting results at a low computational cost, and short running time,” writes the researchers.
How Does Facebook AI’s Model Selection Framework Work
Facebook AI’s self-supervised learning model selection framework architecture consists of three stages — offline training data preparation, offline training for a classifier, and online model prediction. While the offline training data preparation assists in extracting time-series features from time-series data and the best performing model for each time series using offline exhaustive hyperparameter tuning, the offline training for a classifier is where a classifier is trained with the extracted time-series feature as input and best performing model as the label. Eventually, the online model prediction is used for extracting features from the given time series data to infer with the pre-trained classifier.
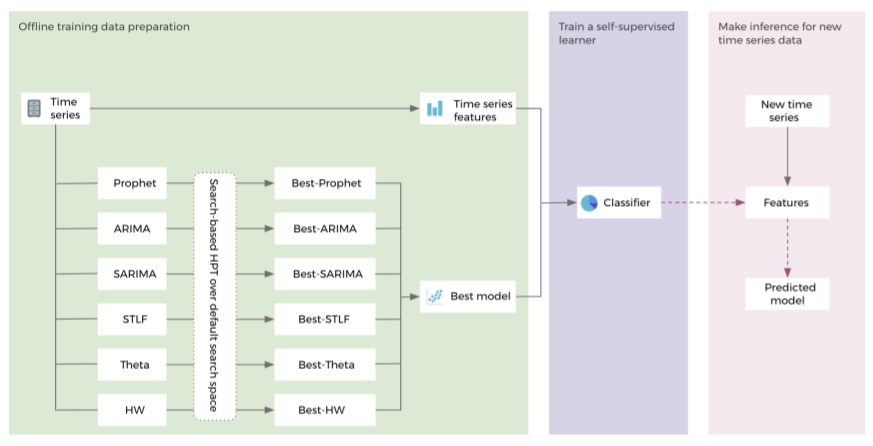
However, only automating model sections does not assist organizations in quickly completing their projects. With time-series analysis, there is a need for having the perfect hyperparameter tuning to ensure superior accuracy of models. Hyperparameter tuning techniques like Grid search, Random search, and Bayesian Optima Search (BOP) work well with single time-series dataset but are computationally demanding. As a workaround, Facebook AI introduced a self-supervised learning framework self-supervised hyperparameter tuning (SSL-HPT).
How Does Facebook AI’s Self-Supervised Hyperparameter Work
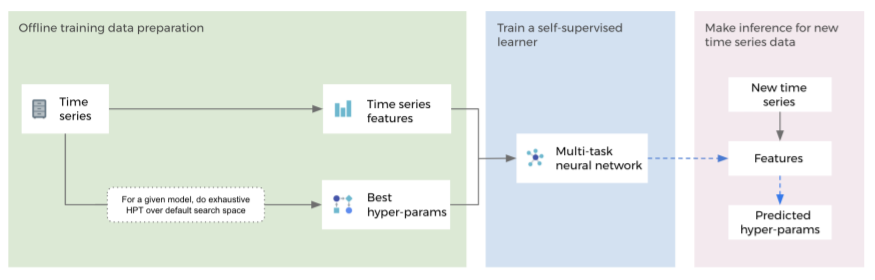
Similar to the model selection framework, Facebook AI’s hyperparameter tuning framework has three steps — offline training data preparation, offline training for neural network, and online hyperparameter tuning. While the offline training data preparation helps obtain time-series features and best-performed hyperparameters for models, the offline training for neural networks is carried out by training a multi-task neural network using datasets from step one. Eventually, given a new time-series data, in the final step, features are extracted, and then inferences are made using a pre-trained multi-tasks neural network. “Since SSL-HPT takes constant time to choose hyper-parameters, it makes fast and accurate forecasts at large scale become feasible,” mentions the researchers.
Integration Of Model Search And Hyperparameter Tuning
By integrating both model search and hyperparameter tuning, the speed at which developers can gain access to exceptional results gives a new dimension to the artificial intelligence landscape. Both SSL-MS and SSL-HPT are trained with the dataset collected in the first step — extracting features from time-series — and for input time-series dataset, the first model is predicted and then the hyperparameters. The computational time is constant since both SSL-learners are already trained offline, making the framework fast and reliable with large-scale workloads.