


DeepMind’s MuZero, an AI program that can play Chess, Go, Shogi, and Atari, gained superhuman performance to outperform existing AI agents like DQN, R2D2, and Agent57, on Atari while matching the performance of AlphaZero on Go, Chess, and Shogi. DeepMind with MuZero could do all of this even without training it with the rules of Go, Chess, Shogi, and Atari.
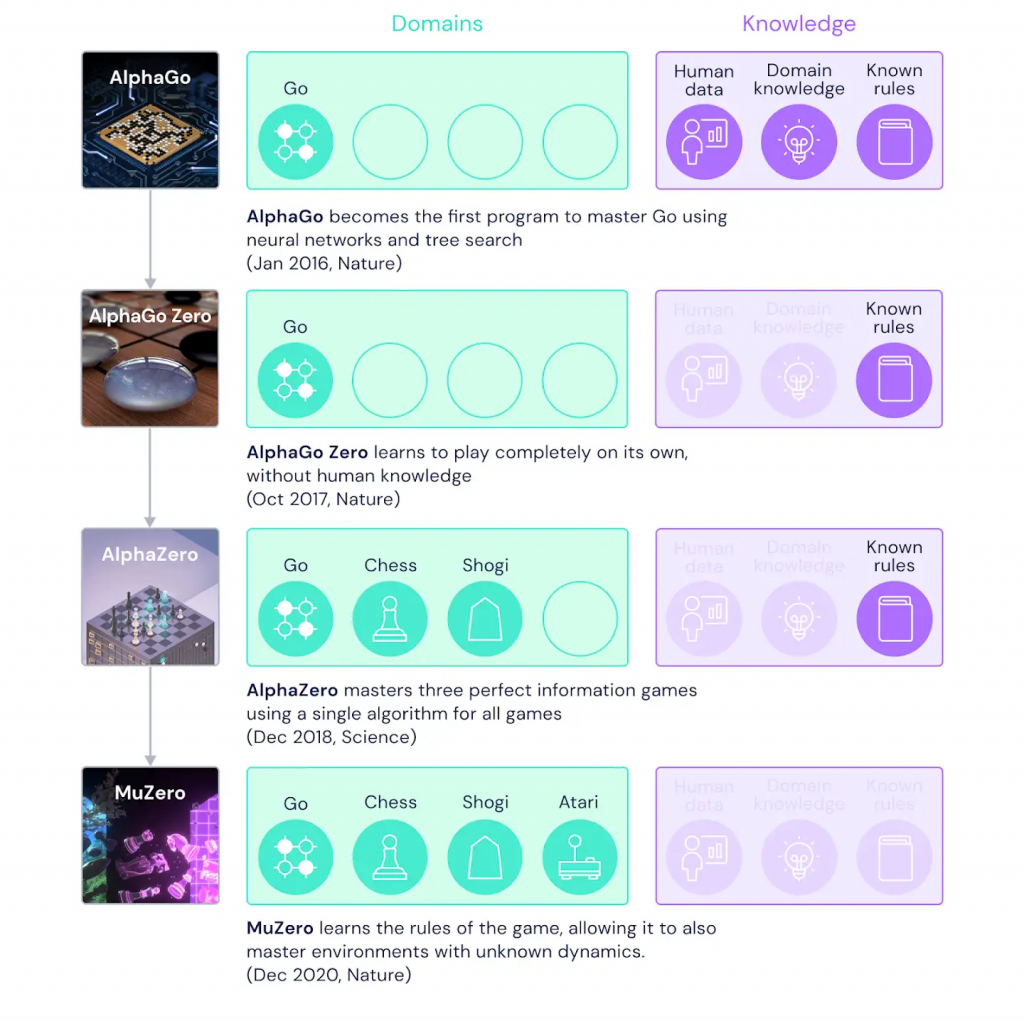
Although MuZero was introduced in a preliminary paper in 2019, this breakthrough was obtained by combining AlphaZero’s superior lookahead tree search. But what makes MuZero different from other approaches is that it does not try to model the entire environment for effective planning.
“For many years, researchers have sought methods that can both learn a model that explains their environment, and can then use that model to plan the best course of action. Until now, most approaches have struggled to plan effectively in domains, such as Atari, where the rules or dynamics are typically unknown and complex,” mentions DeepMind in a blog post.
Also Read: Free 12-Week Long Artificial Intelligence Course By IIT Delhi
In strenuous environments, AI models have failed to deliver optimal results because machine learning struggles to generalize. As a workaround, researchers adopt techniques like lookahead search or model-based planning. However, both approaches have several limitations when it comes to complex environments. While lookahead search only delivers exceptional results when the rules are correctly defined (Chess and Go) or provided with accurate simulators, model-based planning cannot be used to understand the entire complex environments like Atari.
Consequently, DeepMind with MuZero uses an approach where they model only some parts of the environment, which are crucial for AI to make decisions. This eliminates the need for modeling the entire environment in reinforcement learning. For instance, as humans, we do not understand the environment’s intricacies, but we can predict the weather conditions and make decisions accordingly. Adopting a human-like approach for decision-making by AI makes DeepMind’s MuZero a significant breakthrough in the general-purpose algorithm.
DeepMind’s MuZero considers three elements of environments — value, policy, and reward — for effective planning. While value tells how good is the current position, the policy helps in evaluating the best action. The reward assesses the effectiveness of the last action.
MuZero marks a new beginning in AI that can open up further opportunities in the domain to democratize machine learning in complex and dynamic environments.