


Businesses are always looking to explore new information quickly and generate valuable insights. A data lake plays a crucial role in achieving these goals by serving as a centralized repository to store data. It allows businesses to consolidate data from different sources in one place and offers versatility to manage diverse datasets efficiently.
Unlike traditional data storage systems, which focus on storing processed and structured data, data lake stores data in its original format. This approach preserves the data’s integrity and allows for deeper analysis, supporting a wide range of use cases.
This article will discuss data lakes, their need, and their importance in modern-day data management.
What is Data Lake?
A data lake is a centralized repository that stores all structured and unstructured data in its native form without requiring extensive processing or transformation. This flexibility enables you to apply transformations and perform analytics as needed based on specific query requirements.
One of the key features of a data lake is its flat architecture, which allows data to be stored in its original form without pre-defining the schema or data structure. The flat architecture makes the data highly accessible for various types of analytics, ranging from simple queries to complex machine learning, supporting more agile data-driven operations. While data lakes typically store raw data, they can also hold intermediate or fully processed data. This capability can significantly reduce the time required for data preparation, as processed data can be readily available for immediate analysis.
Key Concepts of Data Lake
Here are some of the fundamental principles that define how a data lake operates:
Data Movement
Data lakes can ingest large amounts of data from sources like relational databases, texts, files, IoT devices, social media, and more. You can use stream and batch processing to integrate this diverse data into a data lake.
Schema-on-Read
Unlike traditional databases, a data lake uses a schema-on-read approach. The structure is applied when the data is read or analyzed, offering greater flexibility.
Data Cataloging
Cataloging enables efficient management of the vast amount of data stored within a data lake. It provides metadata and data descriptions, which makes it easier for you to locate specific datasets and understand their structure and content.
Security and Governance
Data lakes support robust data governance and security features. These features include access controls, encryption, and the ability to anonymize or mask sensitive data to ensure compliance with data protection regulations.
Self-Service Access
Data lake provides self-service access to data for different users within an organization, such as data analysts, developers, marketing or sales teams, and finance experts. This enables teams to explore and analyze data without relying on IT for data provisioning.
Advanced Analytics Support
One of the key strengths of a data lake is its support for advanced analytics. Data lake can integrate seamlessly with tools like Apache Hadoop and Spark, which are designed for processing large datasets. It also supports various machine learning frameworks that enable organizations to run complex algorithms directly on the stored data.
Data Lake Architecture
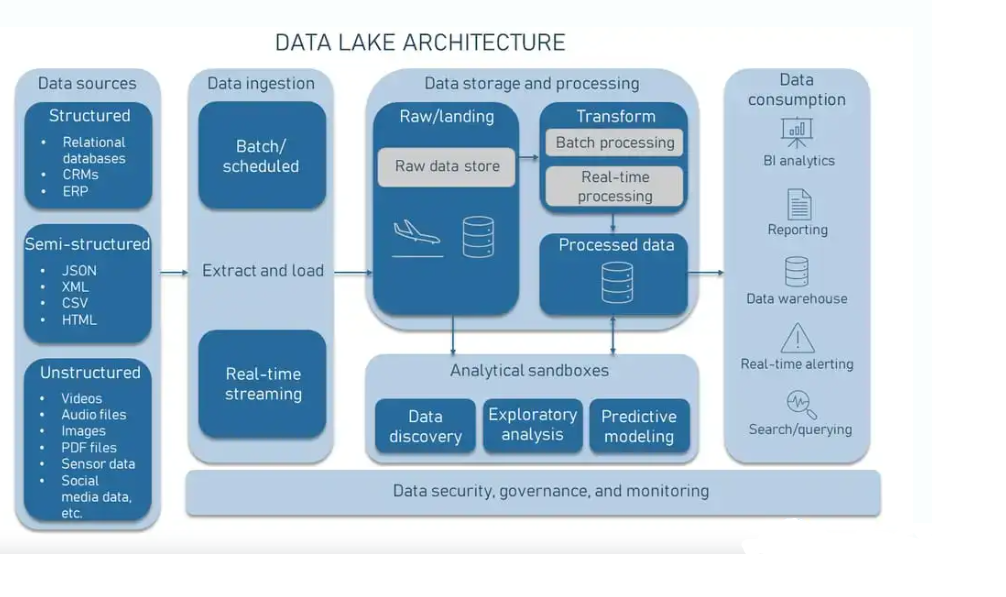
In a data lake architecture, the data journey begins with collecting data. You can integrate data, structured data from relational databases, semi-structured data such as JSON and XML, and unstructured data like videos into a data lake. Understanding the type of data source is crucial as it influences data ingestion and processing methods.
Data ingestion is the process of bringing data into the lake, where it is stored in unprocessed form. Depending on the organization’s needs, this can be done either in batch mode or in real-time.
The data then moves to the transformation section, where it undergoes cleansing, enrichment, normalization, and structuring. This transformed, trusted data is stored in a refined data zone, ready for analysis.
The analytical sandbox is an isolated environment that facilitates data exploration, machine learning, and predictive modeling. It allows analysts to experiment without affecting the main data flow using tools like Jupyter Notebook and RStudio.
Finally, the processed data is exposed to end users through business intelligence tools like Tableau and Power BI, which are used to dive into business decisions.
How Data Is Different from Other Storage Solutions
Data lake offers a distinct approach to storing and managing data compared to other data storage solutions like data warehouses, lakehouses, and databases. Below are the key differences between data lake and these storage solutions.
Data Lake vs Data Warehouse
Below are some of the key differences between a data lake and a data warehouse, showing how each serves a different purpose in data management and analysis.
| Aspect | Data Lake | Data Warehouse |
| Data Structure | Stores raw, unstructured, semi-structured, and structured data. | Stores structured data in predefined schema. |
| Schema | It uses a schema-on-read approach (the structure of the data is defined at the time of analysis) | It uses a schema-on-write approach (the structure is defined when the data is stored within a warehouse) |
| Processing | Data Lakes use the ELT process, in which data is first extracted from the source, then loaded into a data lake, and transformed when needed. | The warehouse uses the ETL process, in which data is extracted and transformed before being loaded into the system. |
| Use Case | Ideal for experiential data analytics and machine learning. | Best for reporting, BI, and structured data analysis. |
Data Lake vs. Lakehouse
Data lakehouse represents a hybrid solution that merges the benefits of both data lake and data warehouse. Here is how it differs from a data lake:
| Aspect | Data Lake | Lakehouse |
| Architecture | Flat architecture with file and object storage and processing layers. | Combines the features of data lakes and data warehouses. |
| Data Management | Primarily stores raw data without a predefined structure. | Manages raw and structured data with transactional support. |
| Cost | Cost-effective, as it eliminates the overhead cost for data transformation and cleaning. | Potentially higher cost for data storage and processing. |
| Performance | Performance may vary depending on the type of tool used for querying. | Optimized for fast SQL queries and transactions |
Data Lake vs Database
Databases and data lakes are designed to handle different types of data and use cases. Understanding the differences helps select appropriate storage solutions based on processing needs and scalability.
| Aspect | Data Lake | Database |
| Data Type | Store all types of data, including unstructured and structured. | Stores structured data in tables with defined schemas. |
| Scalability | Highly scalable | Limited scalable, focused on transactional data. |
| Schema Flexibility | Schema-on-read, adaptable at analysis time. | Scheme-on-write, fixed schema structure. |
| Processing | Supports batch and stream processing for large datasets | Primarily supports real-time transactional processing. |
Data Lake Vendors
Several vendors offer data lake technologies, ranging from complete platforms to specific tools that help manage and deploy data lakes. Here are some of the key players:
- AWS: Amazon Web Services provide Amazon EMR and S3 for data lakes, along with tools like AWS Lake Formation for building and AWS Glue for data integration.
- Databricks: It is built on the Apache Spark foundation. This cloud-based platform blends the features of a data lake and a data warehouse, known as a data lakehouse.
- Microsoft: Microsoft offers Azure HD Insight, Azure Blob Storage, and Azure Data Lake Storage Gen2, which help deploy Azure data lake.
- Google: Google provides Dataproc and Google Cloud storage for data lakes, and their BigLake service further enhances this by enabling storage for both data lakes and warehouses.
- Oracle: Oracle provides cloud-based data lake technologies, including big data services like Hadoop/Spark, object storage, and a suite of data management tools.
- Snowflake: Snowflake is a known cloud data warehouse vendor. It also supports data lakes and integrates with cloud object stores.
Data Lake Deployments: On-premises or On-Cloud
When deciding how to implement a data lake, organizations have the option of choosing between on-premises and cloud-based solutions. Each approach has its own set of considerations, impacting factors like cost, scalability, and management. Understanding the differences helps businesses make informed decisions aligning with their needs.
On-Premises Data Lake
An on-premises data lake involves setting up and managing a physical infrastructure within the organization’s own data centers. This setup requires significant initial hardware, software, and IT personnel investment.
The scalability of an on-premises data lake is constrained by the physical hardware available, meaning the scaling up involves purchasing and installing additional equipment. Maintenance is also a major consideration; organizations must internally handle hardware upgrades, software patches, and overall system management.
While this provides greater control over data security and compliance, it also demands robust internal security practices to safeguard the data. Moreover, disaster recovery solutions must be implemented independently, which can add to the complexity and cost of the data lake system.
Cloud-Based Data Lake
A cloud data lake leverages the infrastructure provided by cloud service providers. This model offers high scalability, as resources can be scaled up or down on demand without needing physical hardware investments.
Cloud providers manage system updates, security, and backups, relieving organizations of these responsibilities. Access to the cloud data lake is flexible and can be done anywhere with internet connectivity, supporting remote work and distributed teams.
The cloud-based data lake also offers built-in disaster recovery solutions, which enhance data protection and minimize the risk of data loss. However, security is managed by the cloud provider, so organizations must ensure that the provider’s security measures align with the compliance requirements.
Data Lake Challenges
Data Swamps
A poorly managed data lake can easily turn into a disorganized data swamp. If data isn’t properly stored and managed, it becomes difficult for users to find what they need, and data managers may lose control as more data keeps coming in.
Technological Complexity
Choosing the right technologies for a data lake can be overwhelming. Organizations must pick the right tools to handle their data management and analytics needs. While cloud solutions simplify installation, managing various technologies remains a challenge.
Unexpected Costs
Initial costs for setting up a data lake might be reasonable, but they can quickly escalate if the environment isn’t well-managed. For example, companies might face higher-than-expected cloud bills or increased expenses as they scale up to meet growing demands.
Use Cases of Data Lake
Data lakes provide a robust foundation for analytics, enabling businesses across various industries to harness large volumes of raw data for strategic decision-making. Here is how data lake can be utilized in different sectors:
- Telecommunication Service: A telecommunication company can use a data lake to gather and store diverse customer data, including call records, interactions, billing history, and more. Using this data, the company can build churn-propensity models by implementing machine learning alogrithms that identify customers who are likely to leave. This helps reduce churn rates and save money on customer acquisition costs.
- Financial Services: An investment firm can utilize a data lake to store and process real-time market data, historical transaction data, and external indicators. The data lake allows rapid ingestion and processing of diverse datasets, enabling the firm to respond quickly to market fluctuations and optimize trading strategies.
- Media and Entertainment Service: By leveraging a data lake, a company offering streaming music, radio, and podcasts can aggregate massive amounts of user data. This data can include a single repository’s listening habits, search history, and user preferences.
Conclusion
Data lakes have emerged as pivotal solutions for modern data management, allowing businesses to store, manage, and analyze vast amounts of structured and unstructured data in their raw form. They provide flexibility through schema-on-read, support robust data governance, and use cataloging to avoid pitfalls such as data swamps and effectively manage data.