


With a significant increase in the generation of unstructured data, including text documents, images, audio, and video files, there is a need for effective data management. Traditional relational databases are mainly designed to handle structured data, leaving this option out for unstructured data. Vector databases are a more suitable choice, especially for various AI-based applications.
Let’s understand what a vector database is, its use cases, and the challenges associated with its use.
What is a Vector Database?
A vector database is a system that allows you to store and manage vector data, which is a mathematical representation of different data types. The data types can be audio, video, or text in the form of multidimensional arrays. While the representation changes the format, it retains the meaning of the original data.
Weaviate, Milvus, Pinecone, and Faiss are some examples of vector databases. These databases are useful in fields such as natural language processing (NLP), fraud detection, image recognition, and recommendation systems. You can also utilize vector databases for LLMs (Large Language Models) to optimize outcomes.
How Does Vector Database Work?
To understand how a vector database works, you need to know the concept of vector embeddings. These are data points arranged as arrays within a multidimensional vector space, which are typically generated through machine learning models. Depending upon the data type, different vector embeddings, such as sentence, document, or image embeddings, can be created.
The vector data points are represented in a multidimensional vector space. The dimensions of this vector space vary from tens to thousands and depend on the data type, such as video, audio, or image.
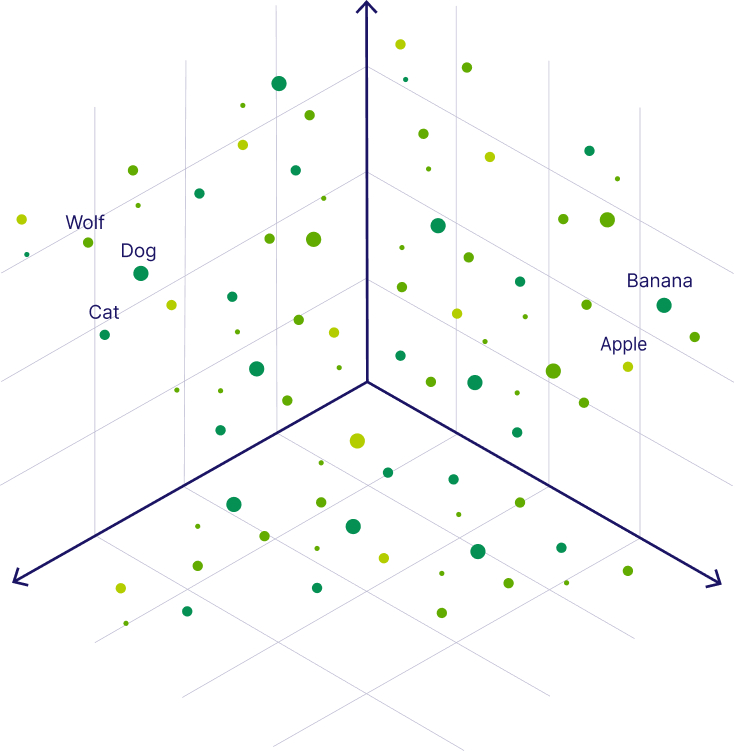
Consider an example of a vector space illustrated in the above image. Here, the data points ‘wolf’ and ‘dog’ are closer to each other as they come from the same family. The data point ‘cat’ might be slightly farther but still in proximity to ‘dog’ as it also comes under the animal category. On the other hand, data points ‘banana’ and ‘apple,’ while close to each other, are placed away from wolf, dog, or cat data points as they both belong to the fruits category.
When you execute queries in a vector database, it provides results by identifying the closest matches to the input query. For this, the database uses a specialized search technique called Approximate Nearest Neighbor (ANN) search. In this method, an algorithm finds data points very close to your input query point but not with exact precision.
The ANN algorithms facilitate the calculation of distance between vector embeddings and store similar vector data together in clusters through a process called vector indexing. This helps in faster data retrieval with efficient navigation of the multidimensional vector space.
Top 5 Popular Vector Databases
Now that we know how a vector database works, let’s look at some of the popular vector databases.
1. Chroma

Chroma is an AI-based open-source vector database that allows you to generate and store vector embeddings. You can integrate it with LLMs and use the stored vector embeddings along with metadata for effective semantic searches. Chroma provides native support for models like HuggingFace and OpenAI and is also compatible with various LLM frameworks like LangChain.
Metadata filtering, full-text search, multi-modal retrieval and document storage are some of the other features offered by Chroma. It also supports SDKs for different programming languages, including Python, Ruby, JavaScript, PHP, and Java, to help you develop high-performing AI applications.
2. Pinecone

Pinecone is a fully managed, cloud-based vector database used extensively in NLP, recommendation systems, and computer vision. It eliminates the need for infrastructure maintenance and is highly scalable, allowing you to manage large volumes of vector data effectively.
Pinecone supports SDKs for programming languages such as Python, Java, Node.js, and Go. Using these SDKs, you can easily access the Pinecone API and use the API key to initialize the client application. After this, you can create indexes and write vector data records using the upsert operation.
The stored embeddings can be queried using similarity metrics such as Euclidean distance, cosine similarity, or dot product similarity. These metrics should match those used to train your embedding model for maintaining effectiveness and accuracy of search results.
3. Weaviate

Weaviate is a vector database—open-source and AI-native—that can store vectors as well as objects, allowing you to perform vector search along with structural filtering. It facilitates semantic search, classification, and question-answer extraction.
The database enables you to retrieve data at a very high speed, with a search time of less than 100ms. You can use its RESTful API endpoints to add and retrieve data to Weaviate. Apart from this, the GraphQL interface provides a flexible way to work with data. Weaviate also offers various modules for vectorization, extending the database’s capabilities with additional functionality.
4. Faiss
Facebook AI Similarity Search (Faiss) is an open-source library that provides efficient search and clustering of large-scale vector data. The AI research team at Meta developed this library, which offers nearest-neighbor search capabilities for billion-scale datasets.
With Faiss, you can search vector data at speeds 8.5x faster than many other high-performance databases because of the k-selection algorithm on GPU architectures. To optimize search performance further, Faiss allows you to evaluate and tune parameters related to vector indexing.
5. Qdrant

Qdrant is an AI-native vector database and semantic search engine that helps you extract meaningful information from unstructured data. It supports additional data structures known as payloads, which facilitate optimized search performance by allowing you to store extra information with vector data. With the help of these payloads and suitable API, Qdrant offers a production-ready service to help you store, search, and manage vector data points.
For effective resource usage, Qdrant supports scalar quantization, a data compression technique to convert floating data points into integers. This results in 75% less memory consumption. You can also convert integer data points back to float, but with a small precision loss.
Use Cases of Vector Database
With the advancement of GenAI applications, there has been a significant rise in the use of vector databases. Here are some prominent use cases of vector dbs:
Natural Language Processing
Vector databases are integral to NLP tasks like semantic search, sentiment analysis, and summarization. It includes converting the words, phrases, or sentences in the textual data into vector embeddings and storing in the vector databases.
Anomaly and Fraud Detection
You can use vector databases for fraud detection. It allows you to store transaction data as vector embeddings. In case of transaction anomalies, a similarity search in the vector space can help quickly identify discrepancies; there is a distance between anomalous transaction data points and the normal data points in vector space. This facilitates rapid responses to potential fraud.
Image and Video Recognition
Vector databases can help you perform similarity searches on a large collection of images and videos. Deep learning models enable you to convert images or videos into high-dimensional vector embeddings that you can store in vector databases. When you upload an image or video in the application, its embeddings are compared to those stored in a vector database, giving you visually similar content as output.
Customer Segmentation
You can use vector databases on e-commerce platforms to segment customers based on their purchase behavior or browsing patterns. The vector database allows you to store embeddings of customer data, and with the help of clustering algorithms, you can identify groups with similar behavior. This helps in developing a targeted marketing strategy.
Streaming Services
Vector databases are useful for providing recommendations and personalized content delivery in streaming platforms. These platforms utilize the vector embeddings of user interaction and preferences data to understand and monitor user behavior. The vector database facilitates conducting similarity searches to find content that is most aligned with your preferences for an enhanced viewing experience.
Challenges You May Face While Using Vector Databases
While vector databases are highly functional data systems, they require high technical expertise, and managing vector embeddings can be complex. Here are some of the challenges that you may encounter while using vector dbs:
Learning Curve
It can be challenging to understand vector database operations, such as similarity measures and optimization techniques, without a strong mathematical background. You must also familiarize yourself with the functioning of machine learning models and algorithms to know how various data points are converted into vector embeddings.
Data Complexity
As the dimensionality of data increases, the space between clusters in high-dimensional vector spaces can result in increased data sparsity or latency issues. The complexity of storing and querying vector data also increases with the rise in data volumes.
Approximate Results
Vector databases support ANN for faster data searching and querying. However, prioritizing speed over precision often leads to less accurate results. In high-dimensional vector space, the data sparsity further degrades the accuracy of these results. This can be detrimental in applications such as medical imaging or fraud detection, where precision is critical.
Operational Costs
Maintaining vector databases can be costly, especially for higher data loads. You have to invest in software tools, hardware, and expert human resources to utilize these databases efficiently. This can be expensive and, if not implemented properly, can lead to unnecessary expenditure.
Summing It Up
With the advancements in AI, the usage of vector databases is bound to increase for effective data management. Techniques such as quantization and pruning can enhance these databases’ ability to handle large volumes of data efficiently. As a result, the development of better-performing and high-dimensional vector databases is expected in the future.
Some popular vector databases include Chroma, Pinecone, Weaviate, Faiss, and Qdrant. Such databases can contribute to use cases such as NLP, anomaly and fraud detection, customer segmentation, and streaming services, among others. However, from a steep learning curve and data complexity to higher operational costs, you need to be aware of the challenges associated with vector databases.
FAQs
How to choose a vector database?
To choose a suitable vector database, you should first identify your specific use cases, scalability, and performance requirements. You should also evaluate the availability of documentation and the ease with which the vector store integrates with your existing infrastructure.
What are the best practices for using vector databases?
To effectively use vector databases, you should choose the appropriate indexing technique for accuracy and speed. For better results, ensure clean, high-quality datasets. You must also regularly monitor and fine-tune the performance of the applications using the vector database and make necessary adjustments before public deployment.
Which vector databases are best for LLMs?
Several vector databases for LLMs offer better semantic search capabilities. Some of the popular ones are Azure AI search, Chroma, Pinecone, and Weaviate. Depending on your budget and infrastructure resources, you can choose any of these vector stores to get optimal results for your LLM queries.