


Machine learning models, from simple regression to complex neural networks, operate on mathematical logic. For these models to function effectively, all data, whether text, audio, or image, must be converted into numerical format. This allows the models to accurately analyze the data and predict outcomes. A vector embedding is a method of representing data as an array of numbers while preserving the original meaning and context of the data.
These embeddings facilitate efficient data processing by enabling the ML models to capture relationships and similarities among different data points. In this article, you will learn about vector embeddings, how you can create an embedding, and the diverse use cases.
What are Vector Embeddings?
To comprehend the concept of vector embeddings, it is important to first understand vectors in the context of machine learning. A vector is a data point that represents both direction and magnitude, similar to coordinates on a map. These vectors define the characteristics and features of the data types they represent.
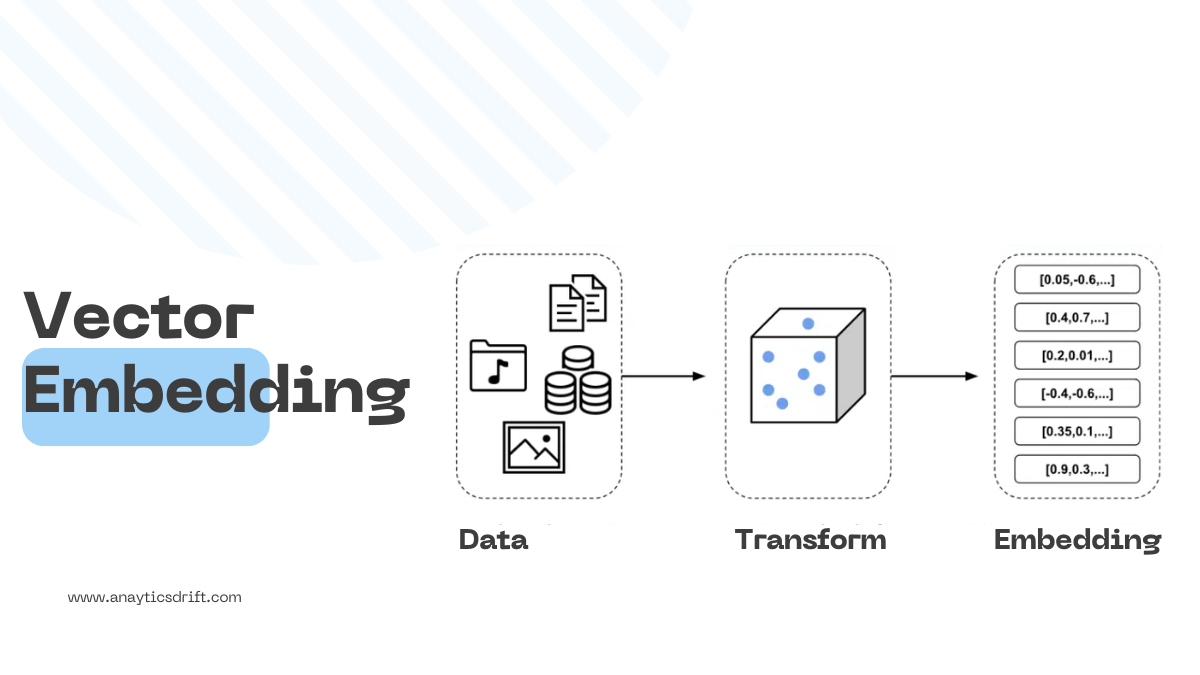
Vector embeddings are structured arrays of numbers that capture significant information about data. These numerical representations contain key features of the original data and are processed by ML models to perform tasks such as classification and clustering. You can also use these embeddings to make predictions based on the relationships between these vectors in a numerical space. With this, models can determine the similarities or differences among data points, which is essential for making informed predictions and decisions based on the data.
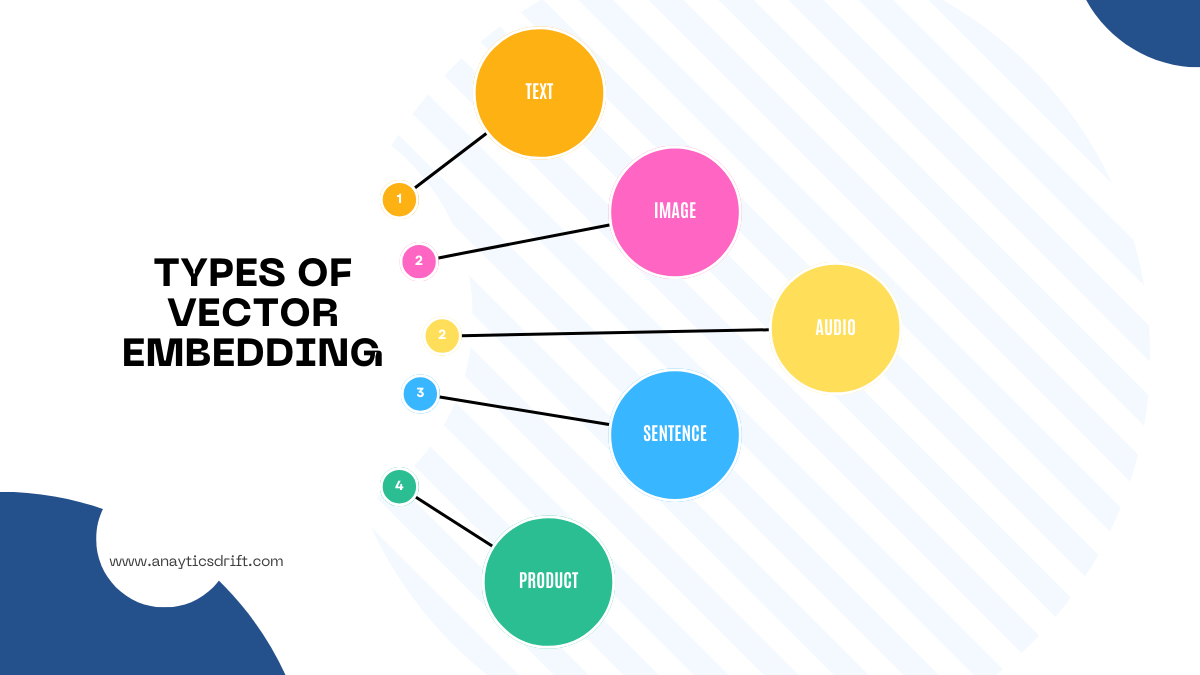
Types of Vector Embeddings
You can represent different types of data in the form of vector embeddings. These vectors are used in NLP tasks and help you create solutions like chatbots, advanced language models like GPT-4, and generative image processors.
Here are some common types of vector embeddings, each used for different purposes:
Text Embedding
Text embedding is a technique to convert text into numerical vectors, capturing the text’s meaning and context. It is a way to transform unstructured text into vector data points that can be quickly processed by machine learning models. Text embeddings are useful for tasks such as search and information retrieval, question-answering systems, document clustering, text classification, language modeling, and synonym generation.
Here are some of the common types of text embeddings:
- Word Embeddings: These embeddings represent individual words as vectors in a high-dimensional space, clustering similar words together. You can generate word embeddings using techniques like Word2Vec, GloVe, and ELMo, each catering to specific requirements.
- Document Embeddings: Document embedding is where you embed and capture the overall semantic meaning of the entire document. These embeddings allow ML models to understand concepts and relationships within a document rather than just focusing on specific words. Tools like Doc2Vec or Sentence-BERT can help generate these embeddings.
Image Embedding
Image embeddings refer to the process of converting images into numerical vectors. From a full image to individual pixels, image embedding provides the ability to classify the features of an image mathematically for analysis.
You can use techniques like convolutional neural networks (CNNs) or pre-trained models like VGG and ResNet to generate image embeddings. These embeddings are used for classification, object detection, and image similarity assessment.
Audio Embedding
Audio embedding represents audio data in vector format. To generate audio embeddings, you extract features, such as pitch, tone, or rhythm, from audio signals. These features are then represented numerically for processing by ML models.
Using audio embedding, you can develop systems like smart assistants that understand voice commands. These systems can detect features and emotions from spoken words.
Audio can be embedded using techniques like recurrent neural networks (RNNs) and CNNs. RNNs can capture temporal dependencies in audio sequences. On the other hand, CNNs help analyze audio spectrograms, treating them like images and extracting spatial hierarchies of features.
Sentence Embedding
Sentence embedding involves representing individual sentences as vectors that capture their meaning and context. These embeddings are helpful in tasks requiring nuanced sentiment analysis.
By encoding the semantic information, the embedding can be used to compare, classify, and derive insights from textual data. These insights can be utilized for applications like chatbots and content moderation, helping them analyze languages more accurately.
Product Embedding
Product embeddings represent products as vectors capturing features, attributes, or other semantic information. Various e-commerce sites use product embeddings to analyze a customer’s behaviors and purchase patterns and provide recommendations based on semantic similarities.
For example, if a customer buys a specific shirt, the system can recommend similar shirts or complementary items like pants.
How to Create a Vector Embedding?
Creating vector embedding involves transforming discrete data points like words, images, or objects into numerical vectors. These vectors represent data features in a high-dimensional space, capturing similarities and relationships between the data points.
Let’s take an example of creating a vector embedding for movies based on their genre. Consider these three movies: Inception, Lion King, and Nemo. These movies have differing characteristics, like action, animation, and adventure. You can assign values to these features.
Inception is a sci-fi movie with no animation and mostly adventure and action. You could represent its vector value in a 3D space as [Action: 2, Animation:0, Adventure: 3] or simply [2,0,3]. Similarly, you can assign values to Lion King and Finding Nemo based on their characteristics.
After assigning values, you represent the values in a 3D space. You will find that Lion King and Finding Nemo have more semantic similarities in terms of animation and adventure than Inception.
The example above uses 3-dimensional space, but in practice, a vector embedding spans to N-dimensional spaces. It is a multidimensional representation used by ML models and neural networks to make decisions, enabling hierarchical nearest-neighbor search patterns.
Approaches to Creating Vector Embeddings
There are two approaches you can consider when creating vector embeddings:
- Feature Engineering: In feature engineering, you use domain knowledge to manually quantify and assign feature values for creating vectors. While detail-oriented, this method is labor-intensive and expensive.
- Deep Learning: This approach helps train the ML models to automatically convert data points (objects) into vectors. The method’s benefits include scalability and the ability to handle complex data structures.
Using Pre-Trained Models to Create Vector Embeddings
Pre-trained models are models trained on very large datasets that transform data like text, audio, and images into vector embeddings. The embeddings created by these models serve as inputs to custom models or vector databases, simplifying the initial steps of many machine-learning tasks.
For textual data, you can use word embedding models like Google’s Word2Vec or Stanford’s GloVe to train a model from scratch to generate embeddings. On the other hand, architectures like ImageNet or ResNet are useful for image data.
Challenges in Handling Vector Embeddings
Although vector embeddings are useful in implementing various NLP tasks, they are not without their challenges. You must address these issues to ensure the effectiveness of your applications.
Here are some of the challenges you might encounter when handling vector embeddings:
- Quality of Training Data: When you train a model to generate vector embeddings, the outcome relies on the quality of the training data. If the data is biased or incomplete, the generated embeddings can be skewed or inaccurate.
- Context Ambiguity: Without enough context, an embedding model may struggle to capture the intended meaning accurately, leading to ambiguity. For example, the word “bat” can refer to an animal or sports equipment. This lack of clarity can lead the model to produce incorrect vector representations, complicating language understanding and data processing.
- Managing High-Dimensional Space: Managing high-dimensional vector space can be computationally demanding. As the datasets grow, the complexity of handling the vectors increases with the increase in the number of dimensions. Optimizing algorithms and advanced techniques become essential to handle the intricacies of the data.
- Maintaining Embedding Models: The spoken language is dynamic, with new words and phrases constantly emerging and meanings evolving. Embedding models must be regularly updated to reflect these changes. The process of ensuring that models remain aligned with the current language usage requires continuous ongoing effort, resources, and time.
Applications of Vector Embedding
Vector embeddings are efficient tools for a range of applications across various fields. Here are some examples of its applications:
Search Engines
Vector embeddings are used in search engines to retrieve relevant information. The embedding helps search systems to match the user query with the documents or items based on semantic similarity and return relevant outputs.
A good vector embedding example is when you input an image in Google’s reverse image search; the engine converts it into a vector representation. This vector is then used in vector search, which allows the system to locate the image’s position in an n-dimensional space. It then retrieves related images based on semantic similarity, enhancing the accuracy and efficiency of the search.
Recommendation Systems
Recommendation systems utilize vector embeddings to capture user preferences and the characteristics of items they like. By matching these embeddings to similar products, systems can recommend new items to users.
For example, Netflix’s recommendation systems use vector embeddings to represent the features of movies or shows, as well as user watch history and ratings. The system then uses semantic similarity search to compare the user’s vectors with the movie vector, identifying embeddings closer in a vector space. This allows the system to suggest content that the user might like.
Anomaly Detection
The anomaly detection algorithms optimize the use of vector embeddings to spot unusual patterns or outliers in data. These algorithms are trained on embeddings representing normal behavior. Based on distance and dissimilarity measures, these algorithms can learn to detect deviations.
Anomaly detection is particularly useful in cybersecurity, where deviation in user behavior or network traffic can signal a potential threat, data breach, or unauthorized access.
Graph Analytics
Graph analytics involves creating graph embeddings, where nodes represent entities like people, products, or other items, and edges define the relationships between nodes. These embeddings help capture the structural and relational dynamics within a graph.
For example, graph embeddings can be used in social networks to suggest potential friends by identifying similarities in user profiles. These similarities can include common connections, interests, and activities.
Conclusion
Vector embeddings play a vital role in modern machine-learning applications by transforming complex data into structured numerical representations. The ability of these embeddings to capture the meaning and semantic relationships between different data points facilitates varied use cases.
These embeddings can be used in algorithms for search engines to improve search results and accuracy. In recommendation systems, they enable precise product suggestions by aligning products with user preferences based on semantic similarities. On the other hand, in anomaly detection, these embeddings help identify unusual patterns, contributing to reliable systems.
Vector embeddings represent a significant step in creating a more intelligent machine learning system that improves operational efficiency and user experiences.
FAQs
What is the meaning of embedding vectors?
Embedding vectors, or vector embeddings, are numerical representations of complex data types, enabling machine learning models to easily understand and analyze the data.
How big are vector embeddings?
Vector embeddings can be large and complex. For instance, a vector in OpenAI can typically be as long as 1536 dimensions, where each embedding is an array of up to 1536 floating-point numbers.
Why do you need vector embeddings?
Vector embeddings are needed for processing and analyzing data in NLP tasks such as classification, clustering, language modeling, and graph analytics.