


Data is generated every second across various industries in different forms and structures. Due to increased remote work and online entertainment, the amount of data created and consumed worldwide is expected to reach over 180 zettabytes by 2025.
However, the challenge isn’t predicting data growth but managing it to extract valuable insights for strategic decisions and improve business productivity. It is essential to organize various data types, such as structured, semi-structured, and unstructured data, into suitable data platforms. Understanding the key differences between these data types is the first step in this process.
This article covers structured vs semi-structured vs unstructured data differences to help you identify and manage them efficiently.
What Is Data?
Data refers to raw facts, figures, or observations collected for analysis. It can be in various forms, including numbers, text, binary formats, or other types. Before processing and analyzing data, it is crucial to identify the type of data you are dealing with.
Classifying data into structured, semi-structured, and unstructured formats helps you determine the appropriate storage, retrieval, and analysis methods. Each format has unique characteristics that influence how the data should be handled. By understanding the data type at hand, you can aggregate it effectively, ensuring that subsequent processing leads to meaningful insights. Once you have identified and stored data from multiple sources, you can transform it into actionable information for strategic decision-making.
Types of Data
Here’s a detailed information about the different types of data—structured, semi-structured, and unstructured:
Structured Data
Structured data is data represented in tabular format with predefined columns and rows. It comes from various internal sources within your organization, such as customer information, financial datasets, sensor data, weblog statistics, product records, and online surveys or polls. Structured data can also be generated from outside the organization, including market research data or publicly available datasets.
To efficiently manage these structured datasets, you can use spreadsheet applications like Microsoft Excel, relational databases like MySQL, and CRM systems like Salesforce. For better analytics and reporting, you can migrate the structured data from these platforms to data warehouses like Google BigQuery or Amazon Redshift.
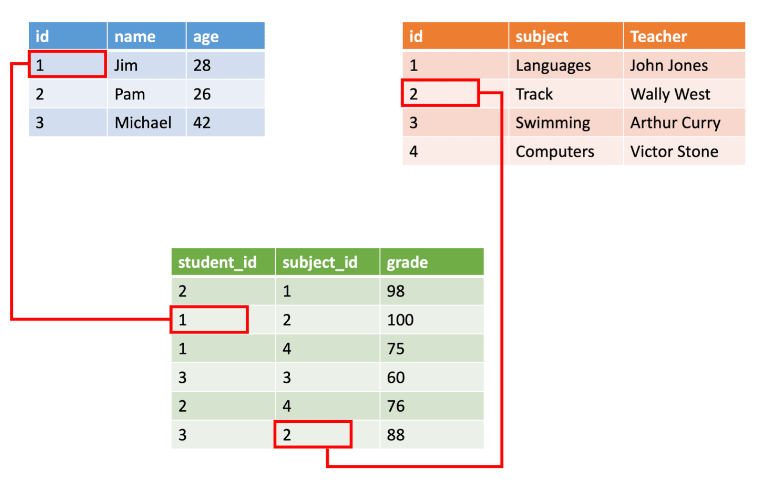
Once the structured data is in data warehouses, you can easily organize and query it using SQL. To extract meaningful insights from the data, you can apply various analytical techniques, such as statistical analysis, data mining, and visualization.
Use Cases
- Finance: Banks and financial institutions record transactions, account balances, and customer information in a structured format for real-time reporting and fraud detection. Analyzing these structured datasets helps in credit scoring and risk assessment, enabling institutions to make better lending decisions.
- Real Estate: In real estate, you can analyze structured data such as property listings, market prices, and sales histories. This analysis helps real estate agents to assess property values, predict trends, and set competitive rental rates.
Semi-Structured Data
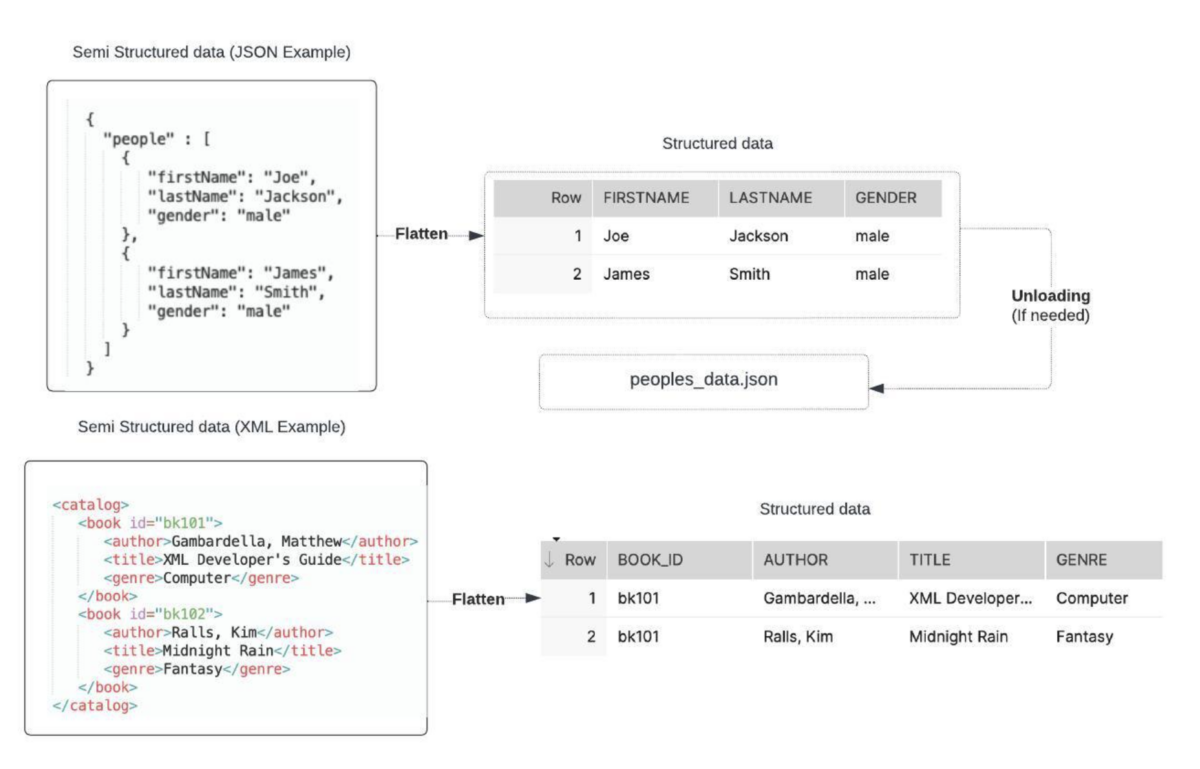
Semi-structured data is a form of information that does not conform to a rigid schema like structured data. However, it contains some organizational properties that make it easier to analyze. Unlike structured data, semi-structured data will not fit neatly into tables and rows. Instead, it often uses tags or metadata to help you separate elements.
Semi-structured data sources include graphs, emails, JSON, XML, HTML, and log files. This data type is often stored in data lakes such as Amazon S3 or Azure Data Lake Storage. After it is stored in suitable storage, you can process it using various tools like Apache Kafka, Apache Spark, or Elasticsearch.
Use Cases
- Web Services: APIs use semi-structured data formats like JSON and XML to exchange data between web services. Since JSON and XML use a predictable structure with key-value pairs (JSON) or tags (XML), the web services can accurately interpret the data even if the exact structure varies slightly. This flexibility also helps the API scale and adapt to new data requirements without redesigning the entire schema.
- Content Management System (CMS): This system allows you to use metadata and tags in the semi-structured data from blog posts and articles to improve content personalization. Using these semi-structured fields, the CMS can help you analyze user behavior or preferences, enabling your team to tailor recommendations or display content relevant to each user. Besides this, it enables you to enhance search accuracy to find content faster.
Unstructured Data
Unstructured data refers to information that does not have a predefined format. It usually comes from sources like text-based documents, images, videos, and audio and can be stored in data lakes like Google Cloud. Analyzing unstructured data can be challenging since it is unorganized and comes in many forms. Vector databases are increasingly valuable in this process for handling large and complex unstructured datasets. These databases allow you to store data as numerical vectors, enabling fast similarity searches and pattern recognition.
To make sense of unstructured data stored in Google Cloud or vector databases, tools like natural language processing (NLP), machine learning, and big data analytics are essential. These tools allow you to analyze and derive insights from unstructured data types by identifying key patterns and understanding contextual meaning. Using these analytical insights, you can predict future trends and make decisions.
Use Cases
- Sentiment Analysis: You can analyze customer reviews and social media posts to assess public opinions about the products or services. This analysis can directly lead to more targeted product improvements, enhanced customer service, and improved marketing strategies.
- Medical Imaging: Healthcare professionals can analyze the unstructured data from medical images using machine learning. This helps them in more accurate diagnostics and personalized treatment planning.
Structured, Semi-Structured, and Unstructured Data: A Quick Tabular Comparison
| Features | Structured Data | Semi-Structured Data | Unstructured Data |
| Data Organization | Well organized in rows and columns. | Partially organized | Unorganized |
| Storage Requirements | Requires less storage space. | Generally, you need moderate storage space as it includes metadata and may have varying formats. | Demands high storage space because it can be in diverse formats. |
| Insight Quality | Provides clear, quantitative insights that are easy to interpret. | Offers moderate insights that can reveal trends and relationships. | Enables rich qualitative insights that capture rich context. |
| Data Processing | You can efficiently process structured data using SQL. | Requires parsing for queries. | Advanced analytical techniques are required to process unstructured data. |
| Scalability | Difficult to scale due to fixed schema. | More scalable than structured data but less than unstructured. | Easy to scale as it is schema-independent. |
| Transaction Management | Support transaction and concurrency mechanisms. | Transaction handling is still in the development phase, and some principles have been adapted from traditional DBMS. | No transaction and concurrency control management. |
| Data Versioning | Using version control systems like data version control (DVC), you can maintain multiple versions of structured rows or tables over time. As a result, you can revert to the previous changes if needed. | Git, a version control system, helps you manage changes in JSON, XML, or HTML documents by storing different versions of the entire file. | Data versioning applies to the entire dataset of unstructured data. Each version of the entire dataset captures the state of the data at a specific point in time. |
| Data Storage Options | Relational databases and data warehouses | NoSQL databases or document stores | Object storage, file systems, and data lakes |
| Supported Data Types | Numeric, text, and dates | JSON, XML, and HTML | Text, images, audio, and video |
Final Thoughts
You have learned the differences between structured, semi-structured, and unstructured data. Structured data is best for applications that require strict organization and quick query responses. Semi-structured data facilitates schema adaptability while maintaining some organization.
Conversely, unstructured data, which supports various formats such as text, images, and videos, presents limitations and advantages. While it is harder to analyze, you can extract rich insights from unstructured data through advanced techniques like ML and NLP. In the end, the choice of data type depends on your projects.
FAQs
How do I choose structured vs unstructured data?
Structured data is better if you require precise calculations, aggregations, or JOIN operations. Conversely, unstructured data is appropriate if your analysis is focused on understanding sentiment, trends, or themes from sources like text, images, videos, or audio.
Can semi-structured data be converted into structured data?
Yes, you can convert semi-structured data into structured data through a parser.