


Machine learning models are one of the major contributors to the advancement of artificial intelligence technologies. By enabling systems to learn from data and predict outcomes with utmost accuracy, these models have become crucial for organizational growth. Machine learning models are critical in automating decision-making and enhancing predictive analytics.
These models serve as mathematical frameworks that help computers interpret complex datasets and identify patterns that would be difficult to recognize. By leveraging ML models, your organization can adapt to changing scenarios and make decisions based on data rather than intuition.
This guide offers insights into what machine learning models are, including their types, benefits, and use cases.
What are Machine Learning Models?
Machine learning (ML) models are a type of mathematical model designed to learn from data through specific algorithms. You can train the model by providing it with data and applying an algorithm that enables it to reason and detect relationships within the data.
After the initial training phase, you test the model using new unseen data to evaluate its performance. This evaluation phase tells you how well the ML model generalizes its knowledge to new scenarios, helping adjust the parameters to improve its accuracy.

For example, let’s say you want to build an application that recognizes user emotions based on their facial expressions. You can start by training a model with images of faces, each labeled with an emotion, such as happy, sad, angry, or crying. Through training, the model will learn to associate specific facial features with these emotions. You can then evaluate its performance to see if it predicts emotions accurately and identify any areas that need further refinement. After thorough evaluation and adjustment, you can use this model for your application.
What are Different Types of Machine Learning Models
There are many different types of machine learning models that can be classified into two different categories based on how they are trained.
Supervised Learning
In supervised learning, you train the model on labeled data, which is the data annotated with known outputs (labels). The model is provided with both the input and its corresponding output dataset. In the training phase, the model learns about different relationships between the input and output, minimizing the error in its predictions. Once the training is complete, you can evaluate the model using new data (testing dataset) to see how accurately it predicts the output.
Here are the two different types of supervised learning models:
Regression Model
Regression in supervised learning is used to analyze the relationship between a dependent variable (what you want to predict) and an independent variable (factors influencing the prediction). The main objective is to find how any changes in an independent variable affects the dependent variable.
For example, if you are predicting a house’s price based on factors like location and size, the regression model helps you establish a relationship between these factors and price. The relationship will help you quantify how much each factor contributes to the price. This model is mainly used when the output is a continuous value.
Terminologies you need to understand
- Response Variable: Also known as the dependent variable, it is the primary factor that you want to predict.
- Predictor Variable: Also known as the independent variable, it is the variable used to predict the response variable.
- Outliers: Outlier data points significantly differ from the other points in a dataset. Their values are either too high or low compared to other points. Because of the difference, the analysis can get skewed and lead to inaccurate results, so outliers need to be handled carefully.
- Multicollinearity: Multicollinearity occurs when there is a high correlation among the independent variables. For example, when predicting house prices, the number of rooms and square footage as independent variables might be correlated since larger houses tend to have more rooms. The correlation makes it difficult for the model to determine the individual effect of each variable on the price.
Types of Regression Model
- Linear Regression: This is the simplest form of regression, where the relationship between the input and output variable is assumed to be linear. The value of the dependent variable changes linearly with the independent variable, making a straight line.
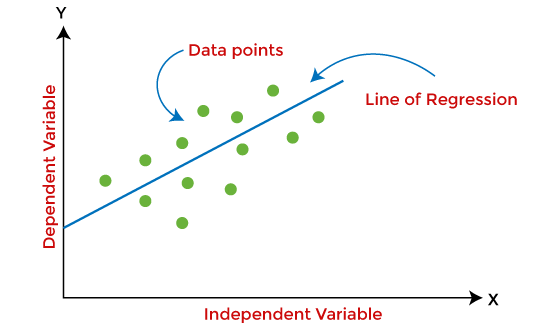
The relationship can be defined using the following equation:
Y= bX+c
In the above equation:
- Y is a dependent variable
- X is the independent variable
- b is the slope indicating the change
- c is the intercept that defines the value of Y when X=0.
For example, if you are predicting the salary of an individual based on experience, then the variable for salary is dependent; the salary increases with the increase in experience.
- Polynomial Regression: Polynomial regression defines the relationship between input and output variables by an n-degree polynomial equation. This model is used to capture more complex patterns that don’t fit a straight line. The additional terms allow the model to capture intricate relationships among variables, making it capable of fitting to curves or other complex patterns.
A polynomial equation might look like this:

Here,
- y is dependent
- x is independent
- b0, b1, etc., are coefficients that the model learns
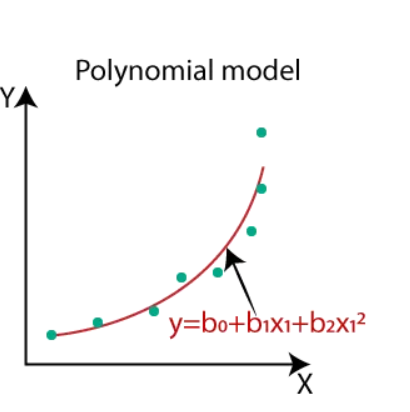
- An example of polynomial regression is if you want to predict a salary based on years of experience. At first, the salary may increase with years, but after reaching a certain level, the salary factor may slow down or plateau.
Classification Model
Classification in supervised learning is used to categorize new data into predefined categories based on the training dataset the model has been previously exposed to. The model learns from labeled data, where each data point is associated with its corresponding label.
Once the training is complete, the model can be tested on new data to predict which category it belongs to. For example, a category may include binary outcomes like Yes or No, 1 0r 0, as well as multi-class outcomes like Cat, Dog, Fruit, or Animal.
In classification models, a function maps the input variable to discrete outputs. The function can be represented mathematically as:
y = f(x)
Here:
- y denotes the output
- f is the function
- x represents the features of the input variable
Types of Classification Models
- Logistic Regression: This is the type of model that is used for binary classification tasks. You can optimize this model to predict the categorical variables where output is either Yes or No, 1 or 0, True or False, etc. For example, this model can be used in spam email detection, where it classifies incoming emails as either spam (1) or not spam (0).
- Support Vector Machine (SVM): The SVM model helps to find the hyperplane that separates data points of one class from another in high-dimensional space.

A hyperplane can be defined as a decision boundary that maximizes the margin between the nearest points of each class. The data points closest to the hyperplane are support vectors, which are crucial for defining the hyperplane. SVM focuses on the support vectors rather than all data points to make predictions.
Unsupervised Learning
In unsupervised learning algorithms, the model is trained on unlabeled data; there are no predefined labels or outputs. The main objective of the model is to identify patterns and relationships within the data. It works by learning from the inherent features of the data without the need for external guidance or supervision.
The main types of unsupervised learning models include:
- Clustering: It is the type of unsupervised learning where the model groups data points based on their similarities. The model forms homogeneous groups from a heterogeneous dataset using similarity metrics like cosine similarity. For instance, you can apply clustering to enhance customer segmentation, grouping customers with similar purchasing habits.

- Association: Association is a rule-based approach that identifies relationships or patterns among various items of large datasets. It works by finding frequent itemsets and drawing inferences about associations between them. For example, an association model can be used to analyze customer purchasing patterns. The model can help you identify that customers who buy bread are likely also to purchase butter. This insight can be useful for building useful product placement strategies.
Decision Tree Model of Machine Learning
Decision tree is a predictive approach to machine learning. It operates by repeatedly splitting the dataset into branches or segments based on specific conditions in the input data. Each split helps to separate data with similar characters, forming a structure that resembles a tree.
Structure of a Decision Tree
- Root Node: It represents the entire dataset and initiates the decision-making process.
- Internal Node: An internal node represents a decision point where the data is split further based on attributes.
- Branch: Each branch represents the outcome of a decision and the path that leads from one decision to another.
- Leaf Nodes: These are the endpoints or terminal nodes of the tree where the final prediction is made.

How Does a Decision Tree Work?
A decision tree works by breaking down a dataset into smaller subsets based on some specific conditions (questions) about input features. At each step, the data is split, and similar outcomes are grouped. The process continues until the dataset can’t be split further, reaching the leaf nodes (where final predictions are made).
Reinforcement Machine Learning Model
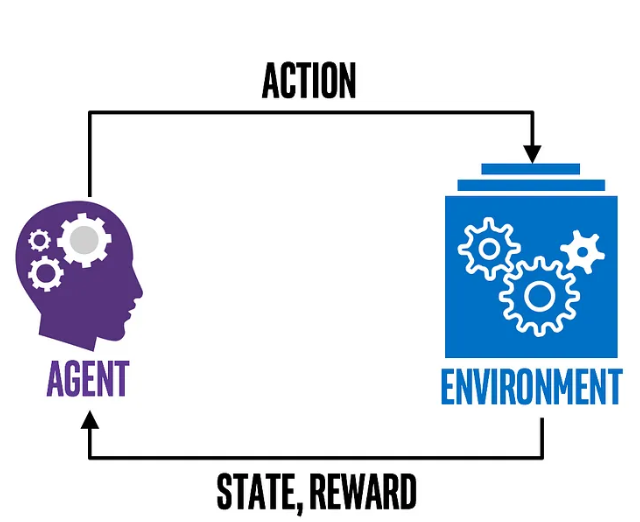
A reinforcement learning (RL) model is a type of machine learning model that enables a computer system to make decisions to achieve the best possible outcomes. In this model, an agent learns to make a decision by interacting with the environment. The agent takes actions to achieve a goal and receives feedback in the form of rewards or penalties based on the actions. RL model’s main objective is to learn how to maximize the cumulative reward over time.
For example, you can optimize your pricing strategy using RL machine learning models based on customer behavior and market conditions.
- Agent: The pricing algorithm acts as the agent, helping make real-time decisions about product pricing.
- Environment: The market landscape, including customer demand, sales data, and competitor price, represents the environment.
- Action: The agent can set various price points, increasing or decreasing, or maintaining the current price.
- State: It includes factors such as current demand, inventory levels, and customer engagement metrics.
- Rewards: The agent can receive a positive reward for increased sales or a negative reward for decreased sales.
After a few iterations, you learn about customer buying patterns and can identify the optimal pricing strategy that maximizes revenue while remaining competitive.
Practical Use Cases of Machine Learning Models
The following are some practical examples that demonstrate the impactful use of machine learning in various applications across different industries.
Recommendation Systems
Many big retailers, such as Amazon and Flipkart, or streaming platforms like Netflix, use ML-powered recommendation systems to analyze users’ preferences and behavior. Through content-based filtering, these systems aim to enhance customer satisfaction and enhance engagement by providing relevant product or service suggestions.
For example, let’s take a look at how Netflix recommends movies or shows. It uses ML recommendation systems to analyze what shows you have watched, how long you have watched them, and what you have skipped. The system learns your habits and finds patterns in the data to suggest content you will likely enjoy, and that perfectly aligns with your taste.
Spam Email Filtering
Email services need robust systems to protect users from spam and phishing attacks. A reliable filtering system can be built using machine learning to sort relevant emails from unwanted or harmful content. The ML model analyzes each email’s content, such as sender’s location, email structure, and IP address. It learns from millions of emails to detect subtle signs of spam that may be missed by rule-based systems.
For example, Google employs machine learning powered by user feedback to catch spam and identify patterns in large datasets to adapt to evolving spam tactics. The Google ML model has advanced to a point where it can detect and filter spam with about 99% accuracy. It uses a variety of AI filters that determine what mail is spam. These filters look at email characteristics like IP address, domain and subdomains, and bulk sender authentication. The ML model also optimizes user feedback to improve the filtering process, where it learns from patterns like when a user marks spam for a certain email in their inbox.
Healthcare Advancements
Machine learning models can help analyze complex medical data such as images, patient histories, and genetic information. This can facilitate early disease detection, enabling timely medical interventions.
For example, machine learning models can help healthcare providers detect early signs of cancer in medical images like MRIs and CT scans. These models help to identify minute details and anomalies in the images that the naked eye can overlook. The more accurate the detection, the more accurate the diagnosis.
Predictive Text
Predictive text technology enhances typing efficiency by suggesting the next word or phrase likely to be used. ML models learn from language patterns and previous inputs to predict what users will type, improving the speed and accuracy of suggestions.
For example, Google’s smart compose in Gmail is powered by machine learning, which helps you write emails faster; it offers suggestions as you enter text. The smart compose is available in English, Spanish, French, Italian, and Portuguese.
Conclusion
Machine learning models have transformed how systems or applications operate. These models simplify the processes of data analysis and interpretation, offering significant benefits across various industries, including healthcare, marketing, and finance.
There are multiple types of machine learning models, such as classification, clustering, and regression. These models continuously learn from the data, enhancing their accuracy and efficiency over time. You can employ the ML models to improve the operational efficiency of your applications, improve decision-making, and derive innovation in various business fields.
FAQs
Are AI and Machine Learning the Same or Different?
AI and machine learning are related but different. AI has a broader concept where the primary object is to develop machines that can simulate human intelligence. Whereas Machine learning is a subset of AI, involving teaching machines to learn from data. This machines improve their performance over time.
Is ChatGPT a Machine Learning Model?
Yes, ChatGPT is a machine-learning model. It is specifically a generative AI model based on the deep learning architecture known as the Transformer. This allows it to produce contextually relevant data by learning from a huge dataset of diverse information.
What is the Simplest Machine Learning Model?
Linear regression is considered the simplest machine learning model. You can use this model to predict the relationship between a dependent variable and an independent variable.
When to Use Machine Learning Models?
You can use ML models across various applications such as for building recommendation systems, filtering spam in emails or advancing healthcare with predictive diagnostics.