


Machine learning and artificial intelligence are some of the popular terms these days, especially to promote software or tools. While these technologies are becoming integral to our lives, many people struggle to gain a comprehensive understanding for effective use.
This article will provide you with machine learning details, including how it works, the different methods, and common algorithms. By understanding these essential concepts, you can evaluate the appropriate applications within your organization that can benefit with machine learning.
Machine Learning Definition
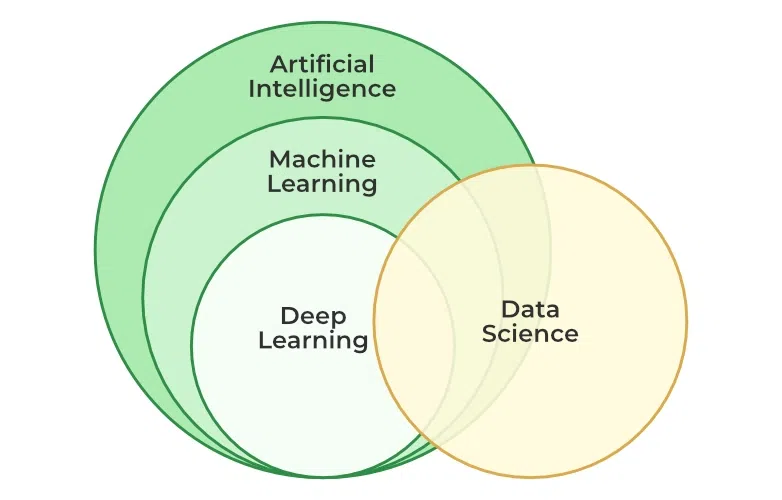
Machine learning is a branch of artificial intelligence that enables you to develop specialized models using algorithms trained on large datasets. These models identify patterns in data to make predictions and automate tasks that involve considerable data volumes.
Nowadays, you can find the use of machine learning in various applications, including recommendation systems, image and speech recognition, natural language processing (NLP), and fraud detection.
For example, Netflix’s recommendation system suggests movies based on the genres you have previously watched. Machine learning models are also being used in autonomous vehicles, drones, robotics, and augmented and virtual reality technologies.
The terms artificial intelligence and machine learning are usually used together or sometimes even interchangeably. However, artificial intelligence encompasses different techniques that make machines mimic human behavior. While AI systems can operate autonomously, ML models typically require human intervention for training and evaluation.
How Does Machine Learning Work?
Here is a simplified overview of how machine learning algorithms work:
Data Collection
First, you should collect relevant data such as text, images, audio, or numerical data that the model will use to perform the assigned task.
Data Preprocessing
Before you use data for model training, it is essential to preprocess and convert it into a standardized format. This includes cleaning the data to handle missing values or outliers. You can also transform the data through normalization or aggregation and then split it into training and test datasets.
Choosing a Model
You should choose a suitable machine learning model depending on the desired task, such as classification, clustering, or some other form of data analysis. Common options include supervised, unsupervised, semi-supervised, and reinforcement learning models.
Training a Model
In this step, you have to train the chosen model using the cleaned and transformed data. During this process, the model identifies the patterns and relationships within the data, enabling it to make predictions. You can use techniques like gradient descent to adjust the model parameters and minimize prediction errors.
Evaluating the Model
Now, you can evaluate the trained model using test data. To assess the performance of your machine learning models, you can use metrics such as recall, F1 score, accuracy, precision, and mean squared error.
Fine-tuning
To improve performance further, you can fine-tune the machine learning models by adjusting hyperparameters. These parameters are not directly involved in model learning but affect its performance. Fine-tuning these factors can improve the accuracy of model outcomes.
Prediction or Inference
The final step involves using the trained and fine-tuned model to make predictions or decisions on new data. For this, the model utilizes the features and patterns it learned during training, whether class labels in classification or numerical values in regression. The model then uses this learning on the new inputs and generates the required outputs.
Machine Learning Methods
The major machine learning methods are as follows:
Supervised Learning
Supervised learning involves using labeled datasets to train models to produce the desired outcomes; the training data is already tagged with the correct output. This input data works as a guide and teaches machines to adjust their parameters to identify accurate patterns and make correct decisions.
Supervised learning is ideal for solving problems with available reference data records. It is classified into two types:
- Classification: This involves categorizing the outputs into predefined groups. It is used in email spam filtering, image recognition, and sentiment analysis.
- Regression: It establishes a relationship between the input and output variables. Popular applications for regressions include predicting real estate prices, stock market trends, and sales forecasting.
Unsupervised Learning
In unsupervised learning, models are not supervised using labeled training datasets. Instead, the model finds hidden patterns in the data and makes decisions using the training data. The model does this by understanding the structure of the data, grouping data points according to similarities, and representing the dataset in compressed format.
There are four unsupervised machine learning types as follows:
- Clustering: In clustering, the model looks for similar data records and groups them together. Examples include customer segmentation or document clustering.
- Association: This involves the model finding interesting relations or associations among the variables of the dataset. It is used in recommendation systems or social network analysis.
- Anomaly Detection: In this type, the model identifies outlier data records or unusual data points and is used for fraud detection in banking and finance sectors.
- Artificial Neural Networks: Such models consist of artificial neurons that transform input data into desired outputs. Examples of artificial neural networks are the creation of realistic images, videos, or audio.
Semi-Supervised Learning
Semi-supervised machine learning is an intermediary approach between supervised and unsupervised learning. In this method, the model uses a combination of labeled and unlabeled training datasets. However, the proportion of labeled data is less than unlabeled data in semi-supervised learning.
First, labeled data is used to train the model for generating accurate results. Then, you can use the trained model to generate pseudo labels for unlabeled data. After this, labels and input data from labeled training data and pseudo labels are linked together. Using this combined input, you can train the model again to get the desired results.
Semi-supervised learning is used in speech analysis, web content classification, and text document classification.
Reinforcement Learning
In reinforcement learning, the model is not trained on sample data but uses a feedback system of rewards and penalties to optimize its outputs. This is similar to a trial-and-error approach, where the model learns and streamlines its results on its own. It involves an agent that learns from its environment by performing a set of actions and observing the result of these actions.
After the action is taken, a numerical signal called a reward is generated and sent to the agent for a positive outcome. The agent tries to maximize rewards for good actions by changing the policy of action accordingly.
The value function is another element of reinforcement learning that specifies the good state and actions for the future using reward. The final component is a model that mimics the behavior of the surrounding environment to predict what will happen next based on current conditions. You can use this to understand the possible outcomes of the model.
Reinforcement learning is the core of AI agentic workflows, where AI agents observe the environment and choose an approach autonomously to perform specific tasks. It is also used in robot training, autonomous driving, algorithmic trading, and personalized medical care.
Common Machine Learning Algorithms
Machine learning algorithms form the foundation for data analysis tasks, enabling computers to perform several complex computations. Some common machine learning algorithms are as follows:
Linear Regression
The machine learning linear regression algorithm is used to predict outcomes that vary linearly with the input data records. For instance, it predicts housing prices based on the area of the house using historical data.
Logistic Regression
The logistic regression algorithm helps evaluate discrete values (binary values like yes/no or 1/0) by estimating the probability of a given input belonging to a particular class. This makes it invaluable for scenarios, like email spam detection or medical diagnoses, that require such discrete decisions.
Neural Networks
Neural network algorithms work like the human brain to identify patterns and make predictions based on complex datasets. They are used mostly in natural language processing, image and speech recognition, and image creation.
Decision Trees
The decision tree algorithm involves splitting the data into subsets based on feature values, creating a tree-like structure. You can interpret complex data relations easily through this algorithm. It is used for both classification and regression tasks due to its flexible structure. Some common applications include customer relationship management and investment decisions, among others.
Random Forests
The random forest algorithm predicts output by combining the results from numerous decision trees. This makes it a highly accurate algorithm and effective for fraud detection, customer segmentation, and medical diagnosis.
Real-life Applications of Machine Learning
Some of the applications of machine learning in real life include:
Email Automation and Spam Filtering
Machine learning is used in email services to filter spam and keep inboxes clean. To accomplish this, you have to train a model on large datasets of emails labeled as spam or not spam. Datasets contain information including textual content, metadata features, images, and attachments in the emails.
A trained machine learning model can identify a newly arrived email as spam if any of its features match those of the dataset labeled as spam. While the spammers change their tactics periodically, the machine learning model can constantly update to stay efficient.
Product Recommendations
Machine learning can help you suggest personalized product recommendations to your customers on your e-commerce platform. The machine learning model enables you to segment customers based on their demographics, browsing histories, and purchase behaviors.
Then, the model helps identify similar patterns and suggests products according to the customer’s interests. As customers continue to use your e-commerce portal, you can collect more data and use it to train the model to give more accurate recommendations.
Finance
In finance, you can use machine learning to calculate credit scores to evaluate the risk of lending to individuals by analyzing their financial history. It is also used in trading to predict stock market prices and economic trends using historical data and real-time information. ML models are particularly helpful to detect fraud by identifying unusual financial transactions.
Social Media Optimization
Deploying machine learning models on social media platforms can provide you with content tailored to your preferences. The machine learning model suggests posts by analyzing your previous interaction in the form of likes, shares, or comments.
The ML models can also help detect spam, fake accounts, and inappropriate content, improving your social media experience.
Healthcare
Machine learning can be leveraged in healthcare to analyze medical data for quick and accurate disease diagnosis. This involves analysis of patient health records, lab tests, and imaging to forecast the development of certain symptoms. Machine learning models can also help with early detection and treatment of critical diseases like cancer.
The pharmaceutical sector is another area where machine learning finds its applications. It helps identify potential chemical compounds for drugs and their success rates quicker than traditional methods. This makes the drug discovery process efficient.
Challenges of Using Machine Learning
Some of the challenges associated with the use of machine learning are as follows:
Lack of Quality Training Data
Training a machine learning model requires access to quality datasets. The training data should be comprehensive and free from biases, missing values, and inaccuracies. However, most datasets are of low quality because of errors in the data collection or preprocessing techniques, leading to inaccurate and biased outcomes.
Data Overfitting or Underfitting
Discrepancies caused by overfitting and underfitting are common in machine learning models.
Overfitting occurs when a model learns not only the underlying patterns but also the noise and outliers from the training data. Such models perform well on training datasets but yield poor results on new datasets.
Underfitting occurs when the ML model is extremely simple and does not capture the required patterns from training datasets. This results in poor results on both training and test datasets.
Data Security
Data security is a significant challenge for machine learning, as the data used for training may contain personal or sensitive information. If proper data regulations are not followed, this information may be exposed to unauthorized access.
Data breaches can also affect data integrity. This can lead to data tampering and corruption, compromising data quality.
Lack of Skilled Professionals
Machine learning requires human intervention for accessing data, model preparation, and ethical purposes. However, there is a shortage of skilled human forces with expertise in artificial intelligence and machine learning. The major reasons for this are the complexity of the field and educational gaps.
Best Practices for Using Machine Learning Efficiently
Here are some best practices that you can follow to use machine learning effectively:
Clearly Define the Objectives
You should clearly define the objectives for adopting machine learning in your workflows. For this, you can analyze the limitations of the current processes and the problems arising from these limitations. To ensure a smooth organizational workflow, you should communicate the importance of using machine learning to your colleagues, employees, and senior authorities.
Ensure Access to Quality Data
The efficiency of the machine learning model depends entirely on the quality of training data. To build effective machine learning models, you should collect relevant data and process it by cleaning and transforming it before using it as a training dataset. The dataset should be representative, unbiased, and free from inaccuracies.
Right Model Selection
Choosing the right machine learning models to achieve optimal outcomes is imperative. Select a model based on your objectives, nature of the data, and resources such as time and budget. You can start with simpler models and then move to complex models if necessary. To evaluate model performance, you can use cross-validation techniques and metrics such as accuracy, precision, F1 score, and mean squared error.
Focus on Fine-tuning
You should fine-tune your machine learning models by adjusting their hyperparameters through grid search or random search techniques. Feature engineering and data augmentation also helps to streamline the functionality of your models and generate accurate outcomes.
Document
Detailed documentation of data sources, model choices, hyperparameters, and performance metrics can help you for future references. It also helps make the machine learning process more transparent, as the documentation can explain the model’s decisions or actions.
Way Forward
As machine learning is evolving, there is a need to create awareness about its responsible development and usage. Efforts should be made to foster transparency in the deployment of machine learning models in any domain. There should also be regulatory frameworks to monitor any discrepancies.
For effective use of machine learning technology, an expert workforce should be developed by upskilling or reskilling all the stakeholders involved. Collaboration between policymakers, industry, and academia should be encouraged to address ethical considerations.
WIth these things in mind, we can create a future where machine learning will be used for humanity’s betterment while driving technological and economic growth.