


The rapid digitization of processes across industries has led to an exponential increase in the quantity and complexity of data generated. Advancements in technology, including high-resolution cameras, sensors, and IoT devices, have also contributed to the data growth. This diverse data, which includes formats like text, images, videos, and audio, is categorized as unstructured data.
Processing such data is complex and requires a modern tech stack to extract relevant insights and apply them in use cases to simplify downstream tasks. Conventional data management systems struggle to handle the volume, variety, and velocity of modern data. This is where vector databases come into play.
Vector databases are designed to help you store and retrieve high-dimensional data efficiently, making them ideal for managing unstructured information. This guide will provide you with a detailed explanation of unstructured data processing in vector databases.
What Is Unstructured Data?
Unstructured data refers to data that doesn’t follow a pre-defined format, structure, or schema. It includes varied information types such as text, images, videos, social media posts, and emails. Unlike structured data, unstructured data doesn’t have a consistent format or relationship between its components. This makes it difficult to extract invaluable insights directly from the data.
To perform unstructured data processing, you require advanced techniques like machine learning models, text mining, and natural language processing. By utilizing these methods, you can discover hidden trends, relationships, and patterns crucial for making informed decisions, improving customer experiences, or driving innovation.
Common Challenges with Processing Unstructured Data
The lack of standardization in unstructured data can cause issues when you try to process it. Some of the common challenges that you might experience include:

- Data Quality and Consistency: Unstructured data has poor data quality due to inconsistencies, noise, irrelevant information, errors, and missing data points. This can significantly compromise the accuracy and reliability of any analysis or insights derived from such data.
- Lack of Metadata: Unlike structured data, unstructured data has limited or no metadata available. This makes categorizing, organizing, searching, indexing, and retrieving data more complex and time-consuming.
- Scalability and Storage: The volume and diversity of unstructured data keep increasing exponentially. To accommodate and process it effectively, you need modern infrastructure that supports scalable storage and high computational resources, which can be expensive.
- Security and Privacy Concerns: Unstructured data can contain sensitive information, making it vulnerable to security breaches and privacy violations. This necessitates compliance with relevant data protection regulations and implementing security measures to protect data.
Comprehensive Guide on How to Process Unstructured Data
Unstructured data processing in vector databases is a complex process that requires transforming data into numerical representations suitable for vector search and analysis. This involves tasks like feature extraction, vectorization, applying similarity search algorithms, and more.
Below is a detailed guide that covers all the steps from unstructured data extraction to deriving actionable insights.
Data Collection and Preparation
The first step involves identifying your project goals, collecting the necessary data, and loading it into repositories like data lakes or warehouses. There are several ways of extracting unstructured data, including Optical Character Recognition (OCR), web scraping, and log file parsing. You can also access data via ETL/ELT tools and APIs.
Once you’ve gathered all the relevant information, you must clean this raw data to remove anomalies and duplicates. This eliminates any data points that can introduce bias into the downstream analysis.
For textual data, you can implement tokenization (breaking text into discrete words or phrases), stemming (reducing words to base form), and lemmatization (resolving words to their dictionary form) for pre-processing. Tools like NLTK, spaCy, and Pandas can help with this.
Meanwhile, for images or videos, you might require operations like resizing, cropping, grayscaling, and applying filters or contrast enhancements. You can use libraries like OpenCV and Pillow for this.
Creating Vector Embeddings
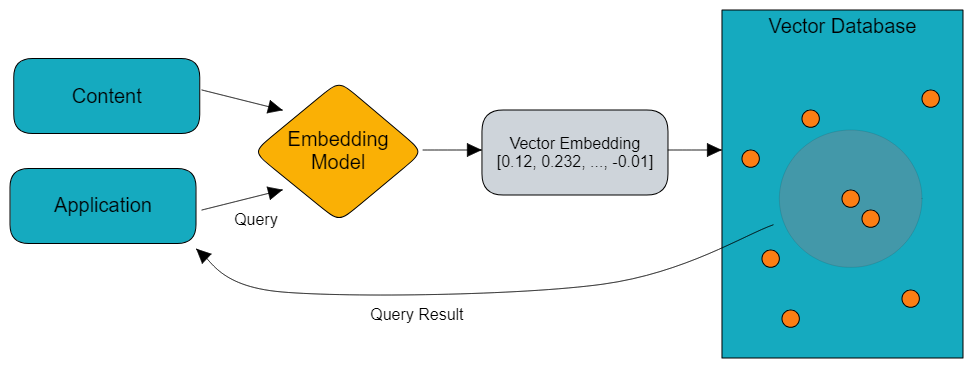
Once the data is cleaned and prepared, the next step is to convert it into a machine-readable format. Vector embeddings help convert complex data (text, images, audio, and videos) into numerical representations, enabling machines to process this data further.
You can use Word2Vec, GloVe, and BERT to capture semantic and syntactic relationships between words. These models can map words, phrases, and documents to dense vectors, resulting in word embeddings, sentence embeddings, and document embeddings. Similarly, you can use TensorFlow’s YAMNET model to generate audio embeddings.
For images, convolutional neural networks (CNNs) like ResNet50 or VGG16 can help you extract feature vectors. You can also use multimodal models like VisualBERT and CLIP. These models convert pixel data into feature vectors that represent patterns like edges, textures, and shapes.
After creating vector embeddings that represent the essential features of your unstructured data, you store them in vector databases for analysis.
Indexing Vectorized Data
Indexing large datasets of vector embeddings involves organizing high-dimensional vectors to facilitate efficient similarity searches. It is a crucial technique for applications like semantic search, recommendation systems, and anomaly detection.
The most common method used for indexing is implementing the Approximate Nearest Neighbor (ANN) algorithm using the Facebook AI Similarity Search (FAISS) library. However, you can also leverage other algorithms like kd-trees and ball trees. These algorithms use metrics such as cosine similarity, dot product, or Euclidean distance to measure the similarity between two vectors.
Some of the indexing strategies that you can utilize include:
- Local Sensitive Hashing (LSH): LSH is a technique that allows you to map similar vectors to the same hash buckets. By hashing query and database vectors, LSH significantly reduces the search space, making it efficient for ANN searches.
- Hierarchical Navigable Small Worlds (HNSW): HNSW organizes vectors in a hierarchical structure, where every node represents a group of similar vectors. This hierarchical structure enables efficient navigation and search, making it suitable for large-scale datasets.
- Flat Indexing: In flat indexing, you store all vectors in a single list without any structural modifications. While simple, it can be inefficient for larger datasets as it requires a linear search to find nearest neighbors.
- Inverted File (IVF) Indexing: Through IVF indexing, you divide the dataset into multiple subsets (vector spaces). Then, assign each vector to one or more vector spaces based on its similarity to cluster centers. This reduces the search space and improves search efficiency, especially for large datasets.
Depending on your database’s scale and computational resources, you should choose the best-fitting strategy that provides quick data access and simplifies the querying process.
Querying and Performance Optimization
Once you have set up your system for unstructured data extraction, vector embedding generation, and indexing, you can begin the querying process. The query you send to the vector database through an LLM application undergoes the same process and results in a query vector. This is compared to the stored vector embeddings to find the most relevant responses.
You can track the query performance using metrics such as F1 score, precision, recall, and mean reciprocal rank and analyze if you can optimize it further. The common methods for fine-tuning the query performance include:
- Dimensionality Reduction: You can use techniques like Principal Component Analysis (PCA) and t-SNE to reduce the dimensions of vectors while preserving the relationships between data points. This method enhances performance by minimizing the computational burden of comparing high-dimensional vector comparisons.
- Parallel Processing: When working with large datasets, distributing the workload into smaller subtasks and executing them concurrently across multiple nodes enables faster retrieval. You can implement parallelism by leveraging parallel indexing and parallel query execution.
- Data Distribution: Data distribution involves partitioning data across multiple nodes or servers so that each node is responsible for processing a subset of vectorized data. This strategy improves query performance and overall system responsiveness by ensuring proper load balancing. You can implement data distribution and achieve fault tolerance using techniques like sharding, partitioning, or replication.
- Caching: You can utilize caching mechanisms for frequently executed queries and improve performance by storing the pre-computed results. For any similar queries, the system can quickly return the cached result without reprocessing the entire query again.
By applying these optimization techniques, your vector database can efficiently handle several queries at a time.
Use Cases of Unstructured Data Processing
With unstructured data processing, you can extract valuable insights and support several real-world applications. Here are some key use cases:
- Customer Sentiment Analysis: You can analyze unstructured data from social media posts, customer reviews, and surveys to get a general sense of your customers’ sentiments and preferences. Natural Language Processing (NLP) techniques can help understand consumer behavior, improve products, and enhance your customer service strategies.
- Recommendation Systems: Platforms like Netflix or Amazon process unstructured data such as browsing history, user interactions, and purchase behavior to personalize recommendations. These companies utilize machine learning models to analyze data and provide relevant product or content suggestions, improving user experience and engagement.
- Fraud Detection: Unstructured data processing helps financial institutions to monitor transaction logs and identify fraudulent activities. By leveraging anomaly detection algorithms, organizations can block suspicious accounts and take other precautionary measures before irreversible damage occurs.
Wrapping It Up
Unstructured data processing is a powerful tool that can help you gain invaluable insights and a competitive edge. This article explores how using vector databases and advanced techniques like ML and NLP to analyze high-volume, complex data can benefit you.
To process unstructured data in vector databases, you can use vectorization, indexing, querying, and performance optimization strategies. This enables you to make informed business decisions and increase your profitability by capitalizing on the information you obtain.
FAQs
Can you store unstructured data in a database?
Yes, you can store unstructured data in No-SQL databases, data lakes, and data warehouses.
How is unstructured data like images, PDFs & videos transformed into structured data?
Unstructured data, such as images, PDFs, and videos, is transformed into structured data using feature extraction techniques. You can use OCR to extract text from images and PDFs, while computer vision helps analyze visual content in images and videos.
What are some strategies to support the general storage and retrieval of information from unstructured data?
For better data storage and retrieval of information from unstructured data, some of the effective strategies include creating vector embeddings, indexing, normalization, and adding metadata.