


Extracting data from websites is crucial for developing data-intensive applications that meet customer needs. This is especially useful for analyzing website data comprising customer reviews. By analyzing these reviews, you can create solutions to fulfill mass market needs.
For instance, if you work for an airline and want to know how your team can enhance customer experience, scraping can be useful. You can scrape previous customer reviews from the internet to generate insights into areas for improvement.
This article highlights the concept of Python web scraping and the different methods you can use to scrape data from web pages.
What Is Python Web Scraping?
Python web scraping is the process of extracting and processing data from different websites. This data can be beneficial for performing various tasks, including building data science projects, training LLMs, personal projects, and generating business reports.
With the insights generated from the scraped data, you can refine your business strategies and improve operational efficiency.
For example, suppose you are a freelancer who wants to discover the latest opportunities in your field. However, the job websites you refer to do not provide notifications, causing you to miss out on the latest opportunities. Using Python, you can scrape job websites to detect new postings and set up alerts to notify you of such opportunities. This allows you to stay informed without having to manually check the sites.
Steps to Perform Python Web Scraping
Web scraping can be cumbersome if you don’t follow a structured process. Here are a few steps to help you create a smooth web scraping process.
Step 1: Understand Website Structure and Permissions
Before you start scraping, you must understand the structure of the website and its legal guidelines. You can visit the website and inspect the required page to explore the underlying HTML and CSS.
To inspect a web page, right-click anywhere on that page and click on Inspect. For example, when you inspect the web scraping page on Wikipedia, your screen will split into two sections to demonstrate the structure of the page.
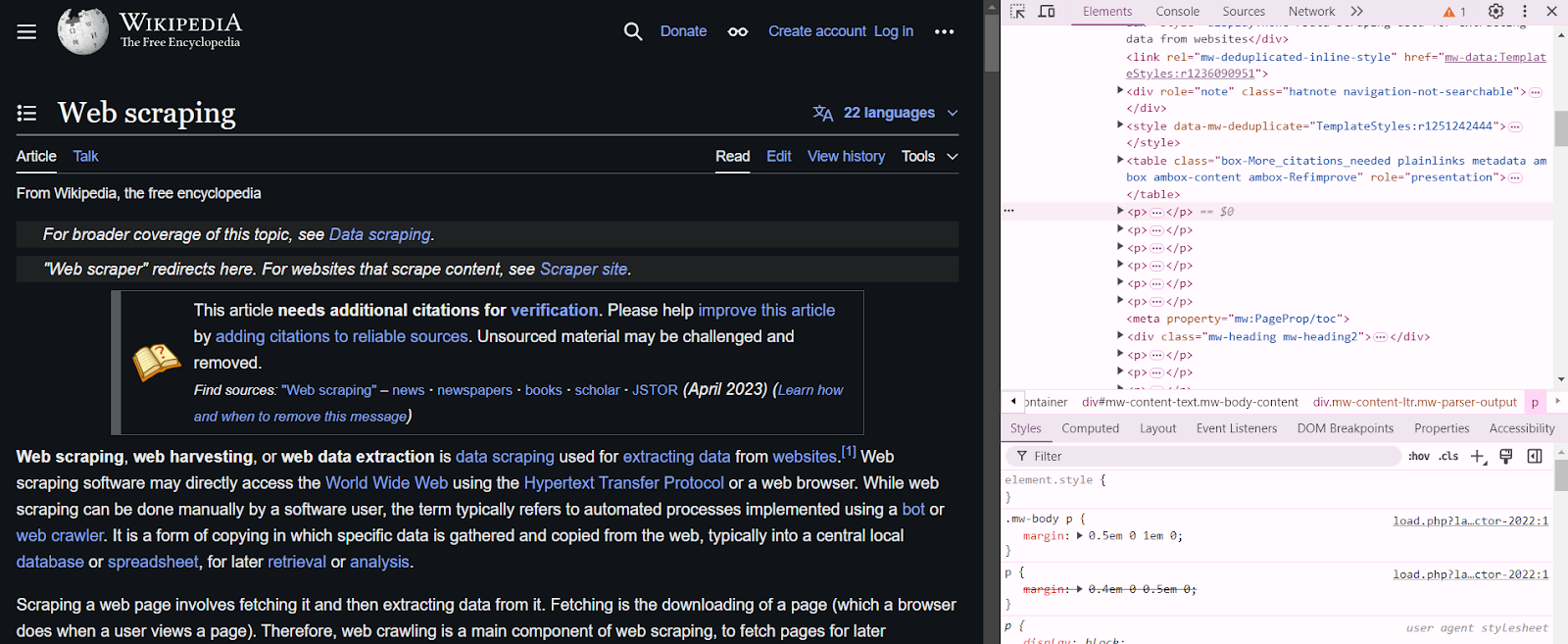
To check the website rules, you can review the site’s robot.txt file, for example, https://www.google.com/robots.txt. This file provides you with the website’s terms and conditions, which outline the information about the content that is permissible for scraping.
Step 2: Set up the Python Environment
The next step involves the use of Python. If you do not have Python installed on your machine, you can install it from the official website. After successful installation, open your terminal and navigate to the folder where you want to work with the web scraping project. Create and activate a virtual environment with the following code.
python -m venv scraping-env
#For macOS
source scraping-env/bin/activate
#For Windows
scraping-env\bin\activateThis isolates your project from other Python projects on your machine.
Step 3: Select a Web Scraping Method
There are multiple web scraping methods you can use depending on your needs. Popular options include using the Requests library with BeautifulSoup for simple HTML parsing and HTTP requests using web sockets, to name a few. The choice of Python web scraping tools depends on your specific requirements, such as scalability and handling pagination.
Step 4: Handle Pagination
Web pages can be difficult to scrape when the data is spread across multiple pages, or the website supports real-time updates. To overcome this issue, you can use tools like Scrapy to manage pagination. This will help you systematically capture all the relevant data without requiring manual inspection.
Python Scraping Examples
As one of the most robust programming languages, Python provides multiple libraries to scrape data from the Internet. Let’s look at the different methods for importing data using Python:
Using Requests and BeautifulSoup
In this example, we will use the Python Requests library to send HTTP requests. The BeautifulSoup library enables you to pull the HTML and XML files from the web page. By combining the capabilities of these two libraries, you will be able to extract data from any website. If you do not have these libraries installed, you can run this code:
pip install beautifulsoup4
pip install requestsExecute this code in your preferred code editor to perform Python web scraping on an article about machine learning using Requests and BeautifulSoup.
import requests
from bs4 import BeautifulSoup
r = requests.get('https://analyticsdrift.com/machine-learning/')
soup = BeautifulSoup(r.text, 'html.parser')
print(r)
print(soup.prettify())Output:
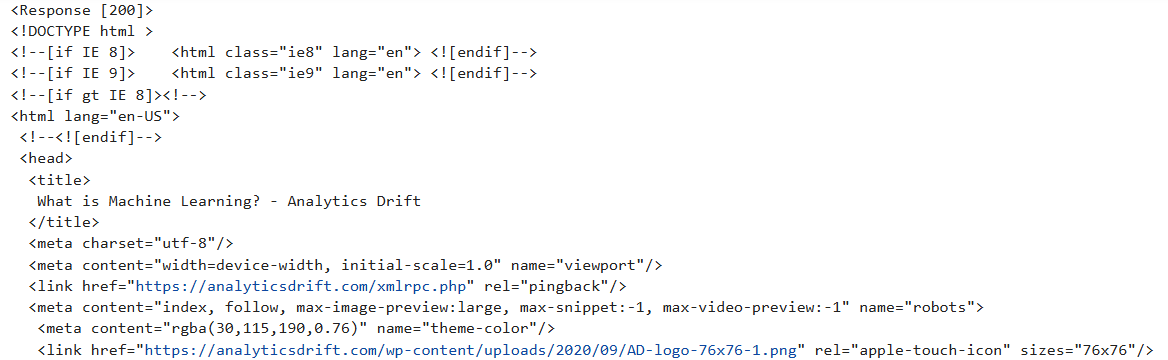
The output will produce a ‘Response [200]’ to signify the get request has successfully extracted the page content.
Retrieving Raw HTML Contents with Sockets
The socket module in Python provides a low-level networking interface. It facilitates the creation and interaction with network sockets, enabling communication between programs across a network. You can use a socket module to establish a connection with a web server and manually send HTTP requests, which can retrieve HTML content.
Here is a code snippet that enables you to communicate with Google’s official website using the socket library.
import socket
HOST = 'www.google.com'
PORT = 80
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = (HOST, PORT)
client_socket.connect(server_address)
request_header = b'GET / HTTP/1.0\r\nHost: www.google.com\r\n\r\n'
client_socket.sendall(request_header)
response = ''
while True:
recv = client_socket.recv(1024)
if not recv:
break
response += recv.decode('utf-8')
print(response)
client_socket.close()Output:
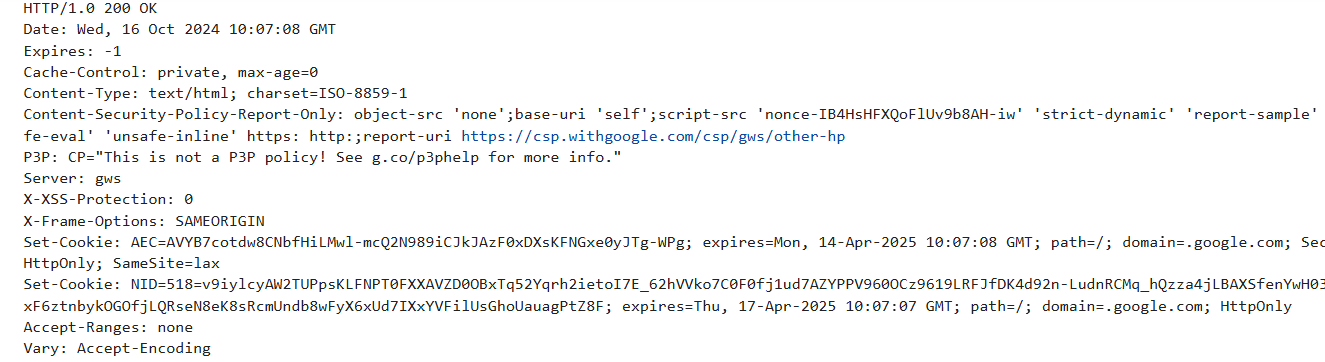
This code defines a target server, Google.com, and the port as 80 signifies the HTTP port. You can send requests to the server by establishing a connection and specifying the header request. Finally, the server response is converted from UTF-8 to string form and presented on your screen.
After getting the response, you can parse the data using regular expressions (RegEx), which allows you to search, transform, and manage text data.
Urllib3 and LXML to Process HTML/XML Data
While the socket library provides a low-level interface for efficient network communication, it can be complex to use for typical web-related tasks if you aren’t familiar with network programming details. This is where the urllib3 library can help simplify the process of making HTTP requests and enable you to effectively manage responses.
The following Python web scraping code performs the same operation of retrieving HTML contents from the Google website as the above socket code snippet.
import urllib3
http = urllib3.PoolManager()
r = http.request('GET', 'http://www.google.com')
print(r.data)Output:
The PoolManager method allows you to send arbitrary requests while keeping track of the necessary connection pool.
In the next step, you can use the LXML library with XPath expressions to parse the HTML data retrieved with urllib3. The XPath is an expression language to locate and extract specific information from XML or HTML documents. On the other hand, the LXML library helps process these documents by supporting XPath expressions.
Let’s use LXML to parse the response generated from urllib3. Execute the code below.
from lxml import html
data_string = r.data.decode('utf-8', errors='ignore')
tree = html.fromstring(data_string)
links = tree.xpath('//a')
for link in links:
print(link.get('href'))Output:

In this code, the XPath finds all the <a> tags, which define links available on the page and highlight them in the response. You can check that the response contains all the links on the web page that you wanted to parse.
Scraping Data with Selenium
Selenium is an automation tool that supports multiple programming languages, including Python. It’s mainly used to automate web browsers, which helps with web application testing and tasks like web scraping.
Let’s look at an example of how Selenium can help you scrape data from a test website representing the specs of different laptops and computers. Before executing this code, ensure you have the required libraries. To install the necessary libraries, use the following code:
pip install selenium
pip install webdriver_managerHere’s the sample code to scrape data using Selenium:
import time
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
def setup_driver():
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1920x1080")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36")
service = Service(ChromeDriverManager().install())
return webdriver.Chrome(service=service, options=options)
def scrape_page(driver, url):
try:
driver.get(url)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CLASS_NAME, "title")))
except TimeoutException:
print(f"Timeout waiting for page to load: {url}")
return []
products = driver.find_elements(By.CLASS_NAME, "thumbnail")
page_data = []
for product in products:
try:
title = product.find_element(By.CLASS_NAME, "title").text
price = product.find_element(By.CLASS_NAME, "price").text
description = product.find_element(By.CLASS_NAME, "description").text
rating = product.find_element(By.CLASS_NAME, "ratings").get_attribute("data-rating")
page_data.append([title, price, description, rating])
except NoSuchElementException as e:
print(f"Error extracting product data: {e}")
return page_data
def main():
driver = setup_driver()
element_list = []
try:
for page in range(1, 3):
url = f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={page}"
print(f"Scraping page {page}...")
page_data = scrape_page(driver, url)
element_list.extend(page_data)
time.sleep(2)
print("Scraped data:")
for item in element_list:
print(item)
print(f"\nTotal items scraped: {len(element_list)}")
except Exception as e:
print(f"An error occurred: {e}")
finally:
driver.quit()
if __name__ == "__main__":
main()Output:

The above code uses a headless browsing feature to extract data from the test website. Headless browsers are web browsers without a graphical user interface that helps you take screenshots of websites and automate data scraping. To execute this process, you define three functions: setup_driver, scrape_page, and main.
The setup_driver() method configures the Selenium WebDriver to control a headless Chrome browser. It includes various settings, such as disabling the GPU and setting the window size to ensure the browser is optimized for scraping without a GUI.
The scrape_page(driver, url) function utilizes the configured web driver to scrape data from the specified webpage. The main() function, on the other hand, coordinates the entire scraping process by providing arguments to these two functions.
Practical Example of Python Web Scraping
Now that we have explored different Python web scraping methods with examples, let’s apply this knowledge to a practical project.
Assume you are a developer who wants to create a web scraper to extract data from StackOverflow. With this project, you will be able to scrape questions with their total views, answers, and votes.
- Before getting started, you must explore the website in detail to understand its structure. Navigate to the StackOverflow website and click on the Questions tab on the left panel. You will see the recently uploaded questions.
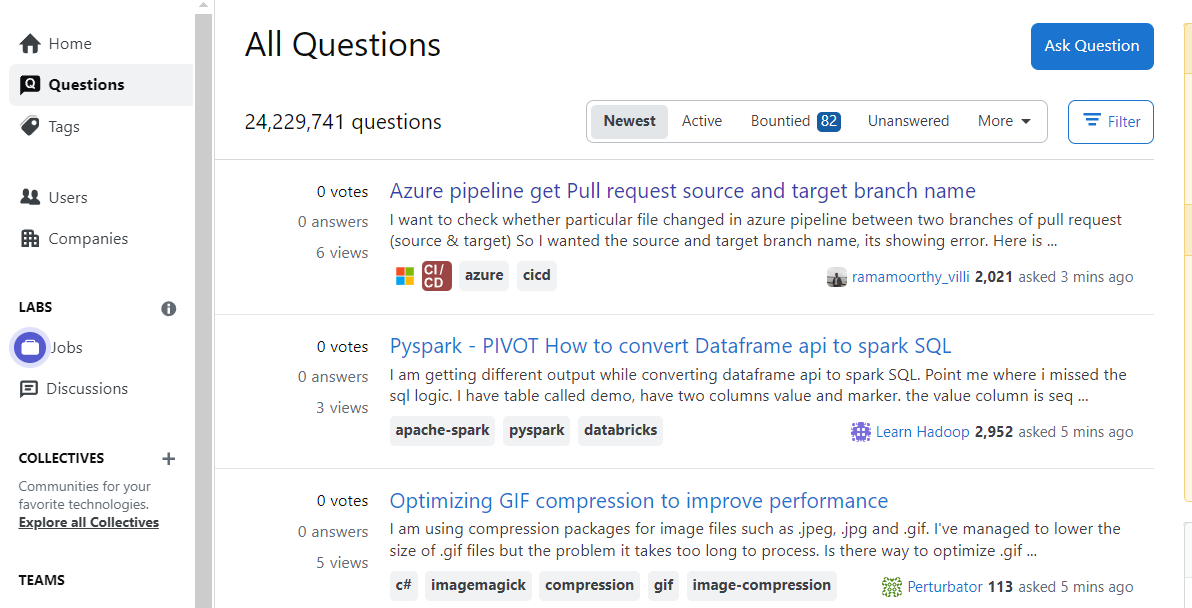
- Scroll down to the bottom of the page to view the Next page option, and click on 2 to visit the next page. The URL of the web page will change and look something like this: https://stackoverflow.com/questions?tab=newest&page=2. This defines how the pages are arranged on the website. By altering the page argument, you can directly navigate to another page.
- To understand the structure of questions, right-click on any question and click on Inspect. You can hover on the web tool to see how the questions, votes, answers, and views are structured on the web page. Check the class of each element, as it will be the most important component when building a scraper.
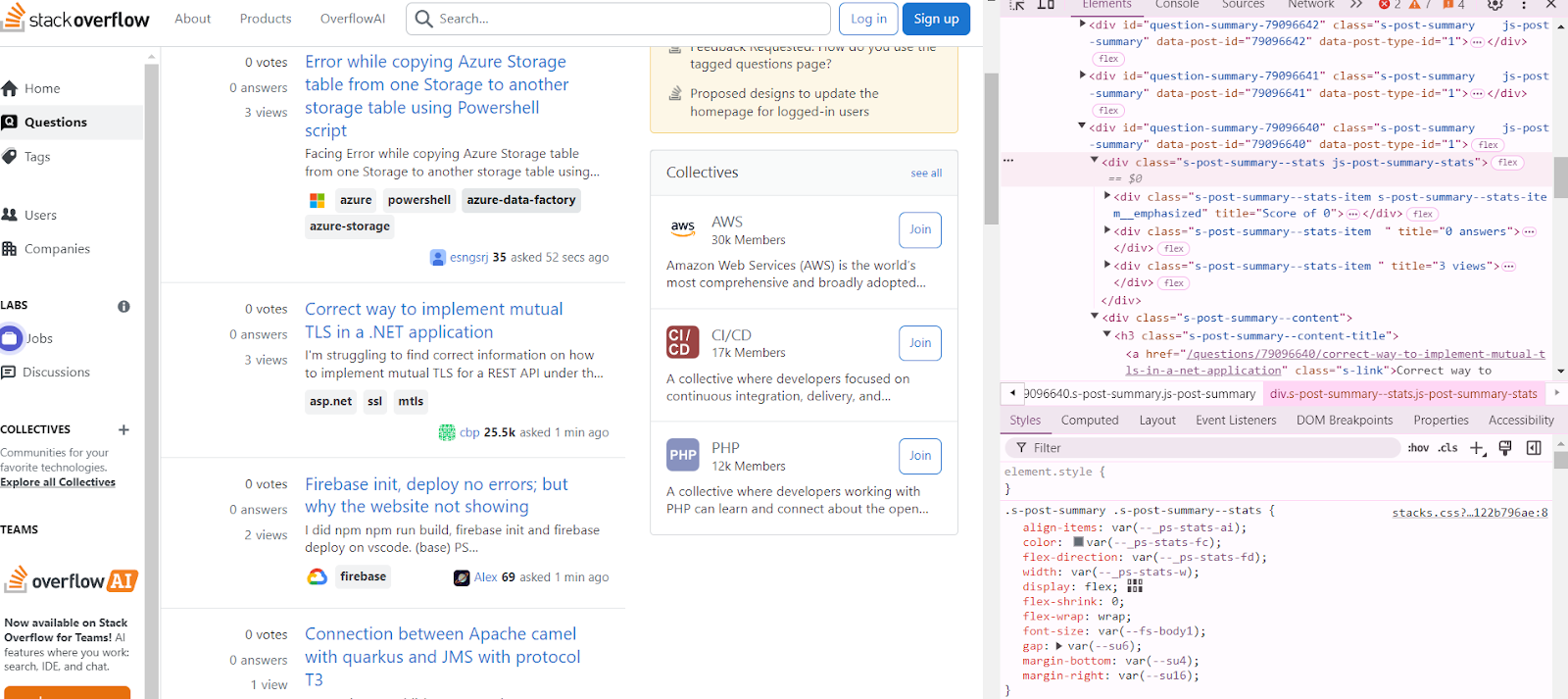
- After understanding the basic structure of the page, next is the coding. The first step of the scraping process requires you to import the necessary libraries, which include requests and bs4.
from bs4 import BeautifulSoup
import requests- Now, you can mention the URL of the questions page and the page limit.
URL = "https://stackoverflow.com/questions"
page_limit = 1- In the next step, you can define a function that returns the URL to the StackOverflow questions page.
def generate_url(base_url=URL, tab="newest", page=1):
return f"{base_url}?tab={tab}&page={page}"- After generating the URL in a suitable format, execute the code below to create a function that can scrape data from the required web page:
def scrape_page(page=1):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(generate_url(page=page), headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
question_summaries = soup.find_all("div", class_="s-post-summary")
page_questions = []
for summary in question_summaries:
try:
# Extract question title
title_element = summary.find("h3", class_="s-post-summary--content-title")
question = title_element.text.strip() if title_element else "No title found"
# Get vote count
vote_element = summary.find("div", class_="s-post-summary--stats-item", attrs={"title": "Score"})
vote_count = vote_element.find("span", class_="s-post-summary--stats-item-number").text.strip() if vote_element else "0"
# Get answer count
answer_element = summary.find("div", class_="s-post-summary--stats-item", attrs={"title": "answers"})
answer_count = answer_element.find("span", class_="s-post-summary--stats-item-number").text.strip() if answer_element else "0"
# Get view count
view_element = summary.find("div", class_="s-post-summary--stats-item", attrs={"title": lambda x: x and 'views' in x.lower()})
view_count = view_element.find("span", class_="s-post-summary--stats-item-number").text.strip() if view_element else "0"
page_questions.append({
"question": question,
"answers": answer_count,
"votes": vote_count,
"views": view_count
})
except Exception as e:
print(f"Error processing a question: {e}")
continue
return page_questions- Let’s test the scraper and output the results of scraping the questions page of StackOverflow.
results = []
for i in range(1, page_limit + 1):
page_ques = scrape_page(i)
results.extend(page_ques)
for idx, question in enumerate(results, 1):
print(f"\nQuestion {idx}:")
print("Title:", question['question'])
print("Votes:", question['votes'])
print("Answers:", question['answers'])
print("Views:", question['views'])
print("-" * 80)Output:
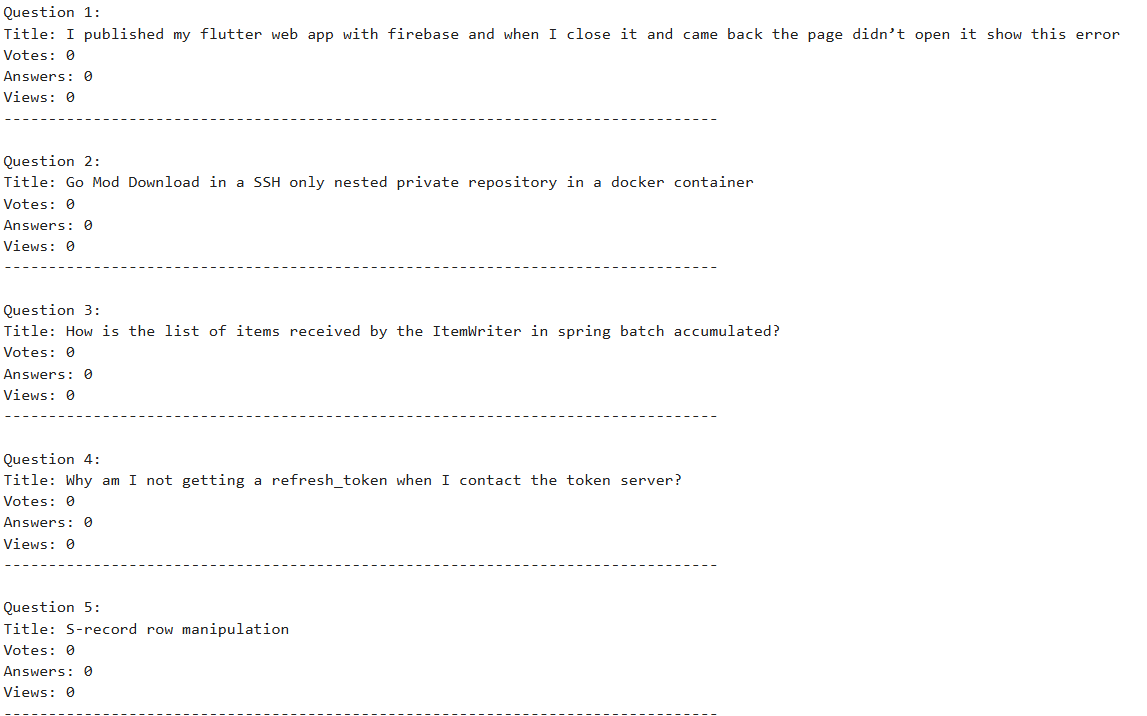
By following these steps, you can build your own StackOverflow question scraper. Although the steps seem easy to perform, there are some important points to consider while scraping any web page. The next section discusses such concerns.
Considerations While Scraping Data
- You must check the robots.txt file and the website’s terms and conditions before scraping. This file and documentation outline the parts of the site that are accessible for scraping, helping ensure you comply with the legal guidelines.
- There are multiple tools that allow you to scrape data from web pages. However, you should choose the best tool according to your specific needs for ease of use and the data type to scrape.
- Before you start scraping any website, it’s important to review the developer tools to understand the page structure. This will help you understand the HTML structure and identify the classes or IDs associated with the data you want to extract. By focusing on these details, you can create effective scraping scripts.
- A website’s server can receive too many requests in a short period of time, which might cause server overload or access restrictions with rate limiting. To overcome this issue, you can consider request throttling, which is a method of adding delays between requests to avoid server overload.
Conclusion
Python web scraping libraries allow you to extract data from web pages. Although there are multiple website scraping techniques, you must thoroughly read the associated documentation of the libraries to understand their functionalities and legal implications.
Requests and BeautifulSoup are among the widely used libraries that provide a simplified way to scrape data from the Internet. These libraries are easy to use and have broad applicability. On the other hand, sockets are a better option for low-level network interactions and fast execution but require more programming.
The urllib3 library offers flexibility in working with high-level applications requiring fine control over HTTP requests. In hindsight, Selenium supports JavaScript rendering, automated testing, and scraping Single-Page Applications (SPAs).
FAQs
Is it possible to scrape data in Python?
Yes, you can use Python libraries to scrape data.
How to start web scraping with Python?
To start with web scraping with Python, you must learn HTML or have a basic understanding of it to inspect the elements on a webpage. You can then choose any Python web scraping library, such as Requests and BeautifulSoup, for scraping. Refer to the official documentation of these tools for guidelines and examples to help you start extracting data.