


The ability of machines to understand and process human language has simplified digital communications tremendously. From chatbots to text-to-image systems, Natural Language Processing (NLP) is transforming how you interact with technology.
Recent NLP advancements enable your machines to understand not only human languages but also coding and complex biological sequences like DNA. By using NLP models, machines are enhancing their ability to analyze textual input and produce natural responses.
This article will help you understand NLP’s fundamentals, how it works, and its impact on technology.
What Is Natural Language Processing (NLP)?

NLP is a dynamic field in artificial intelligence that specializes in the interaction between computers and humans. It involves the development of models that help machines understand, interpret, and generate human language meaningfully.
NLP uses computational linguistics methods to study written and spoken language and cognitive psychology to understand how the human brain works. NLP then combines these approaches with machine learning techniques to bridge the communication gap between humans and machines.
A Quick Glance into the Evolution of Natural Language Processing
Let’s take a look at the evolution of NLP over the years:
The Early 1950s
The concept of NLP emerged in the 1950s with Alan Turing’s creation of the Turing test. This test was built to check if a computer could exhibit intelligent behavior by interpreting and generating human language.
1950s-1990s
Initially, NLP was primarily rule-based, relying on handcrafted rules created by linguists to guide how machines processed language. A significant milestone occurred in 1954 with the Georgetown-IBM experiment, where a computer successfully translated over 60 Russian sentences into English.
Over the 1980s and 1990s, the focus remained on developing rule-based systems for parsing, morphology, semantics, and other linguistic aspects.
1990-2000s
During this period, the field witnessed a shift from a rule-based system to statistical methods. This change made it possible to develop NLP technologies using linguistic statistics rather than handcrafted rules.
During this time, data-driven NLP became mainstream, moving from a linguist-centered approach to one driven by engineers.
2000-2020s
With the exploration of unsupervised and semi-supervised machine learning algorithms, the NLP applications began to include real-world uses like chatbots and virtual assistants. The increased computing power facilitated the combination of traditional linguistics with statistical methods, making the NLP technology more robust and versatile.
2020-Present
Recent advances in NLP are driven by the integration of deep learning and transformer-based models like BERT and GPT. These developments have led to more advanced applications, such as highly accurate text generation, sentiment analysis, and language translation.
NLP continues to be a key part of many AI-driven technologies.
Why Is Natural Language Processing Important for Your Businesses?
A modern organization might receive thousands of inquiries daily through emails, text messages, social media, and video and audio calls. Manually managing such a high volume of communication would require a large team to sort, prioritize, and respond to each message. This can be both time-consuming and error-prone.
Now, imagine integrating NLP into your communication systems. With NLP, your applications will help you automatically process all incoming messages, identify the language, detect sentiments, and respond to human text in real-time.
Let’s consider an instance involving a customer expressing frustration on Twitter about a delayed delivery. An NLP system can instantly identify the negative sentiment and prioritize the message for immediate attention. The system can also generate a personalized response by recommending a solution or escalating the issue to a human agent if necessary.
NLP’s ability to efficiently process and analyze unstructured data has become invaluable for businesses looking to enhance customer service and decision-making.
What Are the Different Natural Language Processing Techniques?
Here are a few techniques used in natural language processing:
Sentiment Analysis
Sentiment analysis involves classifying the emotion behind a text. A sentiment classification model considers a piece of text as input and gives you the probability that the sentiment is positive, negative, or neutral. These probabilities are based on hand-generated features, TF-IDF vectors, word n-grams, or deep learning models.

Sentiment analysis helps you classify customer reviews on websites or detect signs of mental health issues in online communications.
Toxicity Classification
Toxicity classification enables you to build a model to identify and categorize inappropriate or harmful content within the text. This model can analyze messages or social media comments to detect toxic content, such as insults, threats, or identity-based hate.
The model accepts text as input and outputs the probabilities of each type of toxicity. By using these models, you can enhance online conversations by filtering offensive comments and scanning for defamation.
Machine Translation
Machine translation allows a computer to translate text from one language to another without human intervention. Google Translate is a well-known example of this.
Effective machine translation can not only translate text but also identify the source language and differentiate between words with similar meanings.
Named Entity Recognition (NER) Tagging
NER tagging allows machines to detect entities in text and organize them into predefined categories, such as people’s names, organizations, dates, locations, and more. It is beneficial for summarizing large texts, organizing information efficiently, and helping reduce the spread of misleading information.

Word-Sense Disambiguation
Words can have different meanings depending on their context. For instance, the word “bat” can represent a creature or sports equipment used in games like cricket.
Word-sense disambiguation is an NLP technique that helps software determine the correct meaning of a word based on its usage. This is achieved through language model training or by consulting dictionary definitions.
Topic Modeling
Topic modeling is an NLP technique that enables machines to identify and extract the underlying themes or topics from a large collection of text documents.
Latent Dirichlet Allocation (LDA) is a popular method that involves viewing a document as a mix of topics and each topic as a collection of words. Topic modeling is useful in fields like legal analysis, helping lawyers uncover relevant evidence in legal documents.
Natural Language Generation (NLG)
NLG allows machines to generate text that resembles human writing. These models can be fine-tuned to create content in various genres and formats, including tweets, blog posts, and even programming code.
Approaches like Markov chains, Long Short-Term Memory (LSTM), Bi-directional Encoding Representations from Transformers (BERT), and GPT are used for text generation. NLG is useful for tasks like automated reporting, virtual assistants, and hyper-personalization.
Information Retrieval
Information retrieval involves finding relevant documents in response to a user query. It includes two key processes: indexing and matching. In modern NLP systems, you can perform indexing using the Two-Tower model. This model allows you to map embeddings in different data types by placing them in the same vector space. Once the indexing is done, you can compare embeddings easily using similarity or distance scores.
An information retrieval model is integrated within Google’s search function, which can handle text, images, and videos.
Summarization
Summarization in NLP is the process of shortening large texts to highlight the most important information.
There are two types of summarization:
- Extractive Summarization: This method involves extracting key sentences from the text. It scores each sentence in a document and selects the most relevant ones. Finally, the highest-scoring sentences are combined to summarize the original text’s main points concisely.
- Abstractive Summarization: This summarization paraphrases the text to create a summary. It is similar to writing an abstract, where you give a brief overview of the content. Unlike direct summaries, abstracts might include new sentences not found in the original text to explain the key points better.
Question Answering (QA)
Question answering is an NLP task that helps the machines respond to natural language questions. A popular example is IBM’s Watson, which won the game show Jeopardy in 2011.
QA comes in two forms:
- Multiple-choice QA: The model selects the most appropriate answer from a set of options.
- Open-domain QA: This will provide answers to questions on various topics in one or more words.
How Does Natural Language Processing Work?
Let’s take a look at the steps involved in making NLP work:
Data Collection
Before building an NLP model, you must collect text data from sources like websites, books, social media, or proprietary databases. Once you have gathered sufficient data, organize and store it in a structured format, typically within a database. This will facilitate easier access and processing.
Text Preprocessing
Text preprocessing involves preparing raw data for analysis by converting it into a format that an ML model can easily interpret. You can preprocess your text data efficiently using the following techniques:
- Stemming: This technique allows you to reduce words to their base form by ignoring the affixes. For example, the words “running,” “runner,” and “ran” might all be reduced to the stem “run.”
- Lemmatization: This process goes a step beyond stemming by considering the context and converting words to their dictionary form. For instance, “running” becomes “run,” but “better” becomes “good.”
- Stopword Removal: The process enables you to eliminate the common but uninformative words such as “and,” “the,” or “is.” Such words may not contribute much to the meaning of a sentence.
- Text Normalization: This includes standardizing the text by adjusting the case, removing punctuation, and correcting spelling errors to ensure consistency.
- Tokenization: It helps you divide the text into smaller units such as sentences, phrases, words, or sub-words. These units are also called tokens, which are mapped to a predefined vocabulary list with a unique index. The tokens are then converted into numerical representations that an ML model can process.
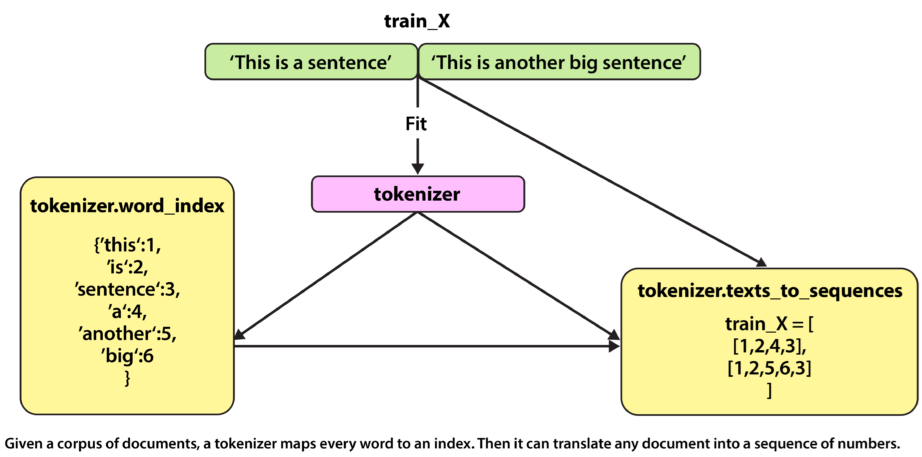
Feature Extraction
Feature extraction involves deriving syntactic and semantic features from processed text data, enabling machines to understand human language.
For capturing syntactical properties, you must use the following syntax and parsing methods:
- Part-of-Speech (POS) Tagging: A process that involves tagging individual words in a sentence with its appropriate part of speech, such as nouns, verbs, adjectives, or adverbs, based on context.
- Dependency Parsing: Dependency parsing involves analyzing a sentence’s grammatical structure and recognizing relationships across words.
- Constituency Parsing: Constituency parsing allows you to break down a sentence into its noun or verb phrases.
To extract semantics, leverage the following word embedding techniques, which convert text into numerical vector representations to capture word meaning and context.
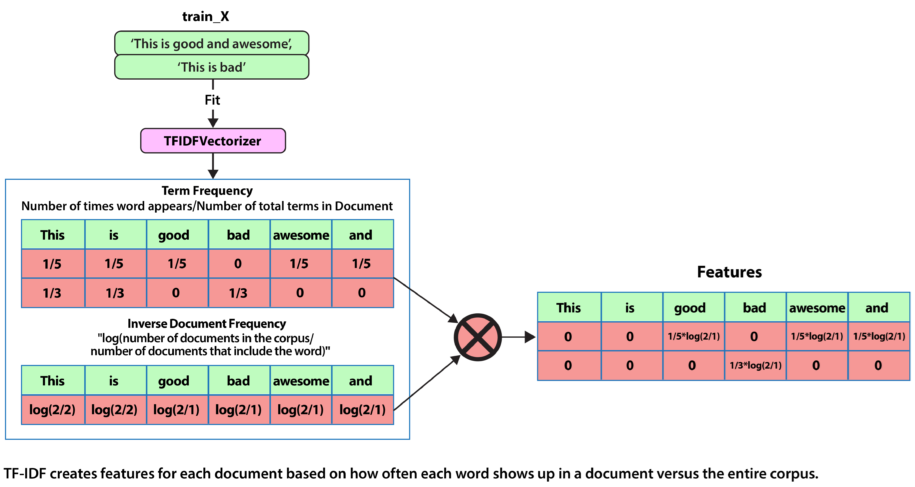
- Term Frequency-Inverse Document Frequency (TF-IDF): TF-IDF involves weighing each word based on its frequency. The method evaluates the word’s significance using two metrics:
- Term Frequency (TF): TF is measured by dividing the occurrence of the word by the total number of words in the document.
- Inverse Document Frequency (IDF): IDF is computed by considering the logarithm of the ratio of the total number of documents to the number of documents containing the word.
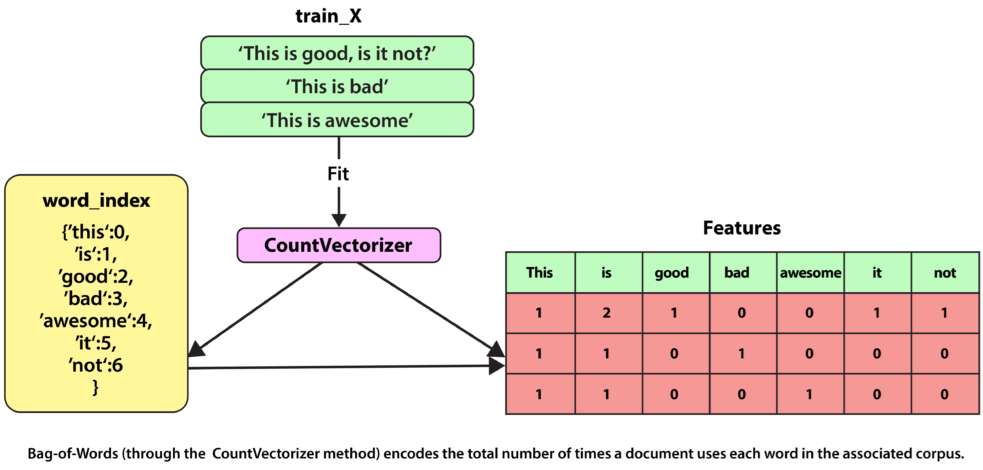
- Bag of Words: This model allows you to represent text data numerically based on the frequency of each word in a document.
- Word2Vec: Word2Vec uses a simple neural network to generate high-dimensional word embeddings from raw text. These embeddings can capture contextual similarities across words. It has two main approaches:
- Skip-Gram: To predict the surrounding context words from a given target word.
- Continuous Bag-of-Words (CBOW): To predict the target word from context words.
- Global Vectors for word representation (GloVe): GloVe is similar to Word2Vec and focuses on generating word embeddings to extract meaning and context. However, GLoVE constructs a global word-to-word co-occurrence frequency matrix instead of neural networks to create embeddings.
Model Training
Once the data is processed and represented in a format that the machine can understand, you must choose an appropriate ML model. This can include logistic regression, support vector machines (SVM), or deep learning models like LSTM or BERT.
After selecting the model, feed the training data, which consists of extracted features, into the model. The model then learns the patterns and relationships in the data by adjusting its parameters to minimize prediction errors.
Evaluation and Fine-tuning of Hyperparameters
You may need to test the trained model to assess its performance on unseen data. Common metrics include accuracy, precision, recall, and F1 Score to determine how well the model generalizes. Based on evaluation results, you can fine-tune the model’s hyperparameters, such as batch size or learning rate, to improve its performance.
Model Deployment
After training and fine-tuning, you can deploy the model to make predictions on new, real-world data. The model deployment also allows you to solve NLP tasks such as NER, machine translation, or QA. The NLP model capabilities will help you automate complex workflows and derive useful trends from unstructured data, improving analysis and decision-making.
Libraries and Frameworks for Natural Language Processing
Here are the popular libraries and development frameworks used for NLP tasks:
Natural Language Toolkit (NLTK)
NLTK is among the most popular Python libraries offering tools for various NLP tasks, including text preprocessing, classification, tagging, stemming, parsing, and semantic analysis. It also provides access to a variety of linguistic corpora and lexical resources, such as WordNet. With its user-friendly interface, NLTK is a good choice for beginners and advanced users.
spaCy
spaCy is a versatile, open-source Python library designed for advanced NLP tasks. It supports over 66 languages, with features for NER, morphological analysis, sentence segmentation, and more. spaCy also offers pre-trained word vectors and supports several large language models like BERT.
Deep Learning Libraries
TensorFlow and PyTorch are popular deep-learning libraries for NLP. They are available for both research and commercial use. You can train and build high-performance NLP models by using these libraries, which offer features like automatic differentiation.
HuggingFace
HuggingFace, an AI community, offers hundreds of pre-trained deep-learning NLP models. It also provides a plug-and-play software toolkit compatible with TensorFlow and PyTorch for easy customization and model training.
Spark NLP
Spark NLP is an open-source text processing library supported by Python, Java, and Scala. It helps you perform complex NLP tasks such as text preprocessing, extraction, and classification. Spark NLP includes several pre-trained neural network models and pipelines in over 200 languages and embeddings based on various transformed models. It also supports custom training scripts for named entity recognition projects.
Gensim
Gensim is an open-source Python library for developing algorithms for topic modeling using statistical machine learning. It helps you handle a large collection of text documents and extract the semantic topics from the corpus. You can understand the main ideas or themes within large datasets by identifying these topics.
Five Notable Natural Language Processing Models
Over the years, natural language processing in AI has gained significant attention. Here are some of the most notable examples:
Eliza
Eliza was developed in mid-1966. It aimed to pass the Turing test by simulating human conversation through pattern matching and rule-based responses without understanding the context.
Bidirectional Encoder Representations from Transformers (BERT)
BERT is a transformer-based model that helps AI systems understand the context of words within a sentence by processing text bi-directionally. It is widely used for tasks like question answering, sentiment analysis, and named entity recognition.
Generative Pre-trained Transformer (GPT)
GPT is a series of transformer-based models that helps AI systems generate human-like text based on input prompts. The latest version, GPT-4o, provides more complex, contextually accurate, natural responses across various topics. GPT-4o is highly effective for advanced chatbots, content creation, and detailed information retrieval.
Language Model for Dialogue Applications (LaMDA)
LaMDA is a conversational AI model developed by Google. It is designed to create more natural and engaging dialogue. LaMDA is trained on dialogue data rather than general web text, allowing it to provide specific and context-aware responses in conversations.
Mixture of Experts (MoE)
MoE is an architecture that uses different sets of parameters for various inputs based on the routing algorithms to improve model performance. Switch Transformer is an example of a MoE model that helps reduce communication and computational costs.
Advantages and Disadvantages of Natural Language Processing
| Advantages | Disadvantages |
| With NLP, you can uncover hidden patterns, trends, and relationships across different pieces of text. This allows you to derive deeper insights and accurate decision-making. | NLP models are only as good as the quality of the training data. Biased data can lead to biased outputs. This can impact sensitive fields like government or healthcare services. |
| NLP allows automation in gathering, processing, and organizing vast amounts of unstructured text data. This reduces the need for manual effort and cuts labor costs. | When you speak, the verbal tone or body language can change the meaning of your words. NLP can struggle to understand things like importance or sarcasm, making semantic analysis more challenging |
| NLP helps you create a knowledge base that AI-powered search tools can efficiently navigate. This is useful for quickly retrieving relevant information. | Language is constantly evolving with new words and changing grammar rules. This may result in NLP systems either making an uncertain guess or admitting to uncertainty. |
Real-Life Applications of Natural Language Processing
- Customer Feedback Analysis: NLP helps you analyze customer reviews, surveys, and social media mentions. This can be useful for your business to extract sentiments, identify trends, and detect common issues, enabling the enhancement of products and services.
- Customer Service Automation: NLP allows you to develop chatbots or virtual assistants to provide automated responses to customer queries. As a result, your business can offer 24/7 support, reduce response times, and improve customer satisfaction.
- Stock Forecasting: With NLP, you can analyze market trends using news articles, financial reports, and social media. This will help you predict stock price movements and make smart investment decisions.
- Healthcare Record Analysis: NLP enables you to analyze unstructured medical records, extract critical information, identify patterns, and support diagnosis and treatment decisions.
- Talent Recruitment: You can use NLP to automate resume screening, analyze job descriptions, and match candidates based on skills and experience. This will automate the hiring process and enhance the quality of your hires.
Conclusion
NLP is one of the fastest-growing research domains in AI, offering several methods for understanding, interpreting, and generating human language. Many businesses are using NLP for various applications to make communication more intuitive and efficient.
Now that you have explored the essentials of NLP, you can simplify each NLP task and streamline model development. This acceleration will improve your productivity and drive innovation within your organization.