


Data has evolved over the years from simple paper records to complex digital formats, encompassing various forms, including numbers, text, and electronic bits. As the data volumes and the complexity of handling data continue to increase, the need for structured data management has become more imperative.
Data structures are specialized formats for efficiently organizing, storing, and accessing data. With the help of these data structures, you can classify and categorize data into organized formats. This categorization enhances retrieval speed and processing efficiency.
This article explores data structure fundamentals, types, and uses. It also examines how you can apply data structures in real-world applications to enhance computational efficiency.
What is a Data Structure?
Data structures offer a systematic way to organize, manage, and process data. They extend beyond primitive data types such as integers or floating-point numbers, providing a more sophisticated organization of varied data.
A data structure encompasses both the logical format of the data and its implementation in a program. This systematic approach enhances both computer and human understanding and usage of the data.
For example, a list of objects can be used to manage employee details. Each object represents an employee and stores attributes like name, position, and department. This allows you to store and retrieve information about any employee by quickly iterating through the list or accessing specific entries.
Classification of Data Structures
Data structures can be broadly classified into two types:
- Linear Data Structure: In a linear data structure, the data elements are organized sequentially, and each element is connected to its previous and next elements. Some examples of these structures include arrays, linked lists, stacks, and queues.
- Non-Linear Data Structure: The data elements in non-linear data structures are not organized sequentially. They are either connected in a hierarchical order or a network-like fashion. Some examples of these structures include trees and graphs.
Basic Terminologies Related to Data Structure
Here are some of the key terms related to data structures:
- Data: It is a piece of information that consists of basic values or a collection of values. For example, an employee’s name, ID, position, and salary are pieces of information about that employee.
- Data Item: A data item represents a single piece of data within the data. For instance, a person’s first name is a data item.
- Group Item: This is a collection of related data items. For example, an employee’s name might include first, middle, and last names.
- Elementary Items: The data items that can not be divided further. For example, an employee’s ID is an elementary item because it is a single value.
- Entity and Attribute: An entity is a category of objects within the dataset, such as an employee. On the other hand, an attribute is characteristic of that entity, such as ID, gender, and job title.
- File: A file is a component that includes a collection of records of the same entity type. For example, a file containing records for 100 employees would include data for each employee.
Need for Data Structures
A data structure offers a formal model that outlines how to logically arrange data elements within your application or organization’s storage system. These structures serve as building blocks for developing complex applications.
Factors to Consider While Choosing a Data Structure
When selecting a data structure for a program or an application, you should consider the following factors:
- Required Operations: Determine the specific functions and operations your program or application will perform. For example, if your program frequently needs to search the data elements, a data structure with fast search capabilities would be beneficial. Options like a binary tree or a hash table might be appropriate for this purpose.
- Processing Time: Evaluate the time complexity associated with each data structure for your needed operations. Processing time will impact how quickly an algorithm can complete a task as the size of the data increases. For example, simple arrays or linked lists might take linear time, which is manageable for smaller datasets but slow for large ones.
- Ease of Use: Some data structures, like arrays and linked lists, are simple, while others, like graphs and trees, might require more complex implementations. The complexity of the data structure should match the requirements of your application.
Type of Data Structure
Different data structures are good for other tasks. The type of data structure used in a particular situation depends on what you need to do with that data and the methods you want to use.
For example, some data structures are better for finding specific items, while others are better for adding and removing items. Choosing the proper data structure helps you program data more efficiently.
Here are some of the commonly used data structures:
Array
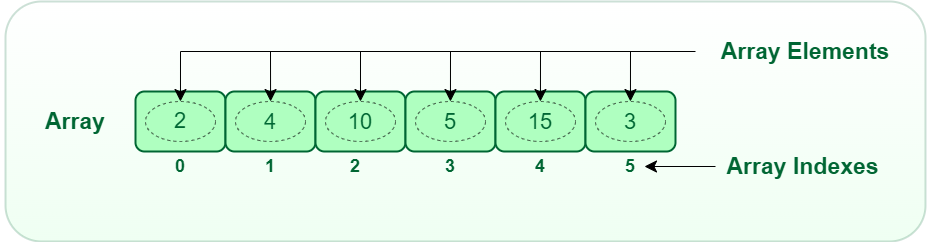
An array data structure allows you to store multiple elements of the same type in a single variable. It can store a collection of data elements, such as numbers or strings.
Each component of an array is identified by an index, which is a unique number indicating its position within the array. The indexing makes accessing, modifying, and managing the data easy for an array.
Types of an Array
- One- Dimensional Array: Stores elements in a single row and are accessed using a single index number.
- Two-Dimensional Array: This array consists of rows and columns resembling a matrix, and the values inside it are accessed using two indices.
- Multi-Dimensional Array: It is an array of arrays with multiple indices and dimensions.
Linked Lists
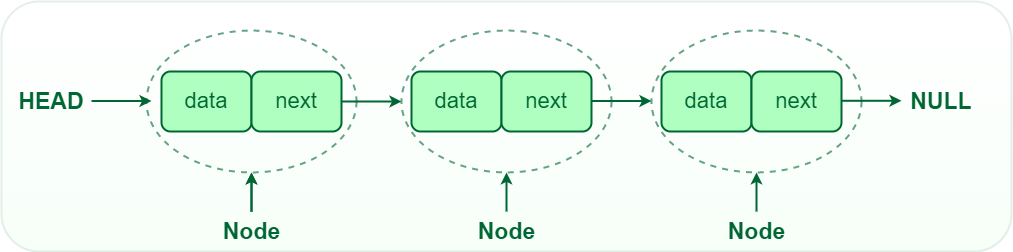
A linked list consists of elements, called nodes, stored in a sequence and connected using pointers. Each node contains two fields: one stores the data, and the other includes the address of the next node. The pointer of the last node is a null pointer, which indicates that there are no more nodes to follow, signifying the end of the list.
Types of Linked Lists
- Singly Linked List: A linked list where you can move in only one direction. It consists of data and a pointer field referencing the next node.
- Doubly Linked List: A doubly linked list consists of one data field and two pointer fields. One pointer field refers to a node before, and the other field refers to the node after. This list allows you to go in both directions, backward and forward.
- Circular Linked List: A circular linked list is similar to a singly linked list. The key difference is that, in a circular linked list, the pointer field of the last node consists of the address of the first made, creating a circular structure.
Stacks
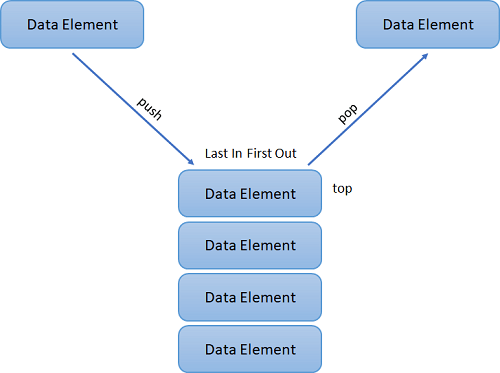
Stack is a data structure that manages the data elements using ‘Last in, First Out’ (LIFO) to manage the data elements. The LIFO method implies that the last element added will be the first to be removed.
Key Operations You Can Perform on a Stack
- Push: It is the operation to add an element to the stack.
- Pop: Pop is an operation that removes an element from the stack.
Queues
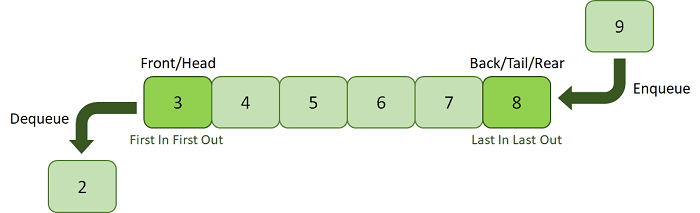
A queue is a data structure that follows the ‘First In, First Out’ (FIFO) principle. It implies that the first element added to the queue will be the first to be removed.
Key Operations You Can Perform On a Queue
- Enqueue: Enqueue allows you to add an element to the rear (end of the queue from where you add an element) of the queue.
- Dequeue: Dequeue allows you to remove an element from the front (end of the queue where the element is removed) of the queue.
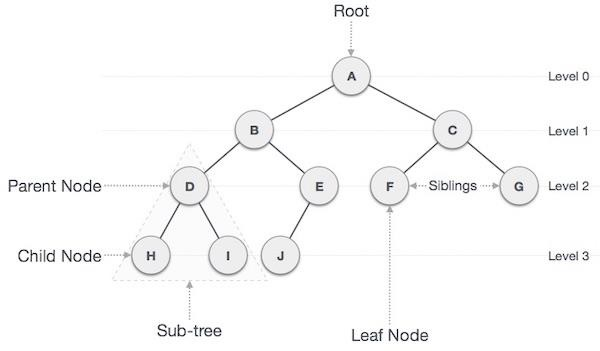
Trees
A tree is a nonlinear data structure that helps you organize data hierarchically. It consists of nodes connected by edges, with a single node called the root. A node can have child nodes, creating a parent-child relationship.
Types of Trees
- Binary Tree: In this data structure, a parent node can have at most two children, a left node and a right node.
- Binary Search Tree: A BST is a binary tree in which each node has a specific order of its elements. The value of each left child node is smaller than that of the parent node, and the value of each right node is larger than that of the parent node.
- AVL Tree: An AVL tree is a special BST particular that automatically balances itself, maintaining a roughly even shape. Each node in the AVL tree has a balance factor; if the balance becomes uneven, the tree performs rotation to rebalance itself.
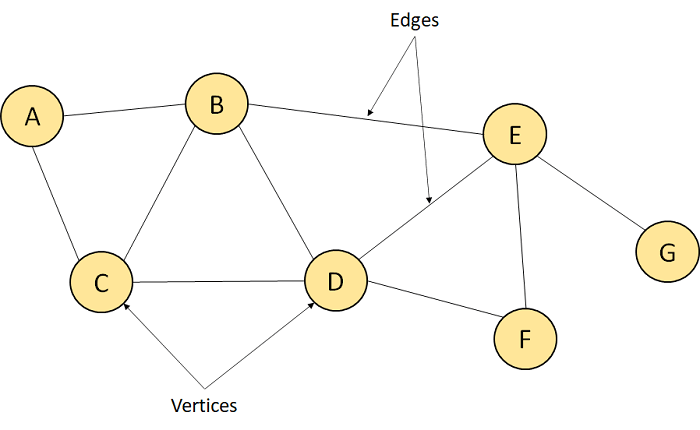
Graphs
A graph is a nonlinear data structure consisting of vertices (nodes) and edges (connections between nodes). Graphs can represent various real-world systems, such as social and communication networks.
Depending on the structure and properties, graphs can be categorized into several types: directed, undirected, weighted, unweighted, null, trivial, simple, and more. Each type of graph serves a different purpose based on the nature of the connection and the data it represents.
Operations on Data Structures
Operations on data structures are fundamental actions performed to manipulate and manage the data stored within them. Let’s look at some operations that apply to the above data structures.
- Insertion: Insertion is adding a new element to a data structure. For example, you can use an insert operation to add details of a new employee, such as name, ID, or position, to a linked list.
- Deletion: It involves the removal of a data element from a data structure. For example, you can delete the record of an employee who just left the company.
- Searching: You can search operations for a specific element within the data structure. This involves checking each element to locate a value, such as searching for a node in a binary search tree.
- Sorting: Arranging elements in a specific order, such as ascending or descending, allows you to organize the data efficiently. For instance, sorting a list of contacts alphabetically by last name in a contact management app will enable you to find and access specific contacts quickly.
- Merging: Merging is combining two data structures into one. This could involve merging two sorted arrays into a single sorted array or combining two linked lists. For instance, a company with separate online and in-store transaction databases can merge their datasets into a single comprehensive database.
- Splitting: Splitting involves dividing a data structure into smaller parts, such as splitting a large array into multiple sub-arrays or partitioning a graph into separate components.
- Updating involves modifying an existing element’s value in the data structure, such as updating an employee’s salary in an employee management system.
Applications and Use Cases of Data Structures
Data structures are essential for efficiently managing and processing data in various real-world applications. Here are some key uses of data structures:
- Linked lists are useful for managing collections of items that don’t need to be ordered, such as playlists in a music app or collections of bookmarks in a web browser. This allows you to add or remove a data element without worrying about the order.
- Queues are suited for collections needing first-in and first-out orders, like print queues, which ensure jobs are processed in the order they are received.
- Graphs can be used to analyze connectivity and relationships. For example, you can utilize them for map routes in transportation networks by representing locations as vertices and routes as edges. It allows for the calculation of shortest paths and the optimization of travel routes.
Key Takeaways
Data structures are fundamental for structuring data to allow for efficient processing, storage, and retrieval. You can broadly classify data structure into two types: linear (array, linked lists, stacks, queues) and non-linear (trees, graphs) structures, each suited to different tasks. Data structures support various operations, including insertion, deletion, searching, sorting, merging, splitting, and updation. Understanding their properties and applications helps you make informed data management and programming decisions.